流式计算 Flink版
流式计算 Flink版






- 文档首页
 流式计算 Flink版快速入门作业开发开发 Flink SQL 任务
流式计算 Flink版快速入门作业开发开发 Flink SQL 任务

在 Flink 控制台,可以创建 Flink SQL 任务,通过简单的 SQL 语句表达业务逻辑,就能持续计算数据并输出结果。
本文通过一个简单示例,介绍如何开发 Stream 类型的 SQL 任务。如需了解 Batch SQL 任务,请参见开发 Flink Batch SQL 任务。
前提条件
项目管理员(Project_Admin)已经在项目内创建好 Flink 资源池,请参见创建资源池。
体验流程
本文将 Flink SQL 任务开发流程总体分为了两个阶段,分别是开发阶段和运维阶段,每个阶段对应的成员及主要工作均不相同。
- 开发阶段:一般是开发人员(Project_Dev)负责开发 SQL 任务,完成开发和调试后将任务上线到生产环境。
- 运维阶段:一般是运维人员(Project_OPS)负责启动任务,并查看任务执行情况。
步骤一:开发 SQL 任务
- 登录流式计算 Flink 版控制台。
- 在顶部菜单栏选择目标地域。
- 在左侧导航栏选择项目管理,在搜索框中根据项目名称进行模糊搜索,然后单击项目区块进入项目。
- 在项目左侧导航栏选择作业开发。
- 在作业开发页面单击加号按钮,创建任务。
您也可以选择目标文件夹,直接在该文件夹中创建任务;也可以直接单击 Flink 任务下的 Flink SQL。
在创建作业对话框,设置任务名称、任务类型、所属文件夹、引擎版本等参数,然后单击确定
配置
说明
任务名称
自定义设置任务的名称。
名称的字符长度限制在 1~48,支持数字、大小写英文字母、下划线(_)、短横线(-)和英文句号(.),且首尾只能是数字或字母。任务类型
选择 Flink 任务 > Flink Stream > SQL。
如需体验 JAR 任务的开发流程,请参见开发JAR 作业。所属文件夹
系统提供文件夹管理功能,用于分类管理任务。在体验任务开发过程中,您可以直接选择系统默认存在的数据开发文件夹。
如果您有自建文件夹管理任务的要求,请单击创建文件夹的文件夹按钮,然后创建文件夹。引擎版本
目前支持 Flink 1.11-volcano 、Flink 1.16-volcano、Flink 1.17-volcano 版本,请按需选择。
任务描述
输入任务的描述语句,一般描述任务实现的功能。
在任务编辑区编辑 SQL 任务的业务逻辑代码。
此处提供一个示例 SQL 任务代码。代码含义为:新建一个产生随机数据的 datagen 源表,统计 datagen 源表随机产生的 word 字段单词次数,并将结果写入数据结果表。create table doc_source (word varchar) WITH ( 'connector' = 'datagen', 'rows-per-second' = '5', 'fields.word.length' = '30' ); create table doc_result (word varchar, cnt bigint) WITH ( 'connector' = 'print' ); insert into doc_result select t.word, count (1) from doc_source t group by t.word;单击格式化按钮,系统自动调整SQL代码格式。
系统将自动美化您的 SQL 语句,使得语句更加美观、整洁、可读。SQL 任务代码编辑完成后,单击验证按钮。
系统会自动校验您的 SQL 语句正确性,如果报错,请根据提示自主完成 SQL 语句修改。检验通过后,系统提示success。代码编辑和验证通过后,单击保存按钮,保存任务代码。
步骤二:调试 SQL 任务
系统验证功能只能校验 SQL 语法正确性,无法完全规避代码运行中可能出现的错误,在任务上线前,强烈建议完成任务调试。
Session 集群用于在开发环境调试任务。支持使用线上数据和离线文件两种方式,请按需选择调试方式。
创建 Session 集群
在任务编辑区域上方,单击 Session 。
在 Session资源池页面,单击创建资源池。
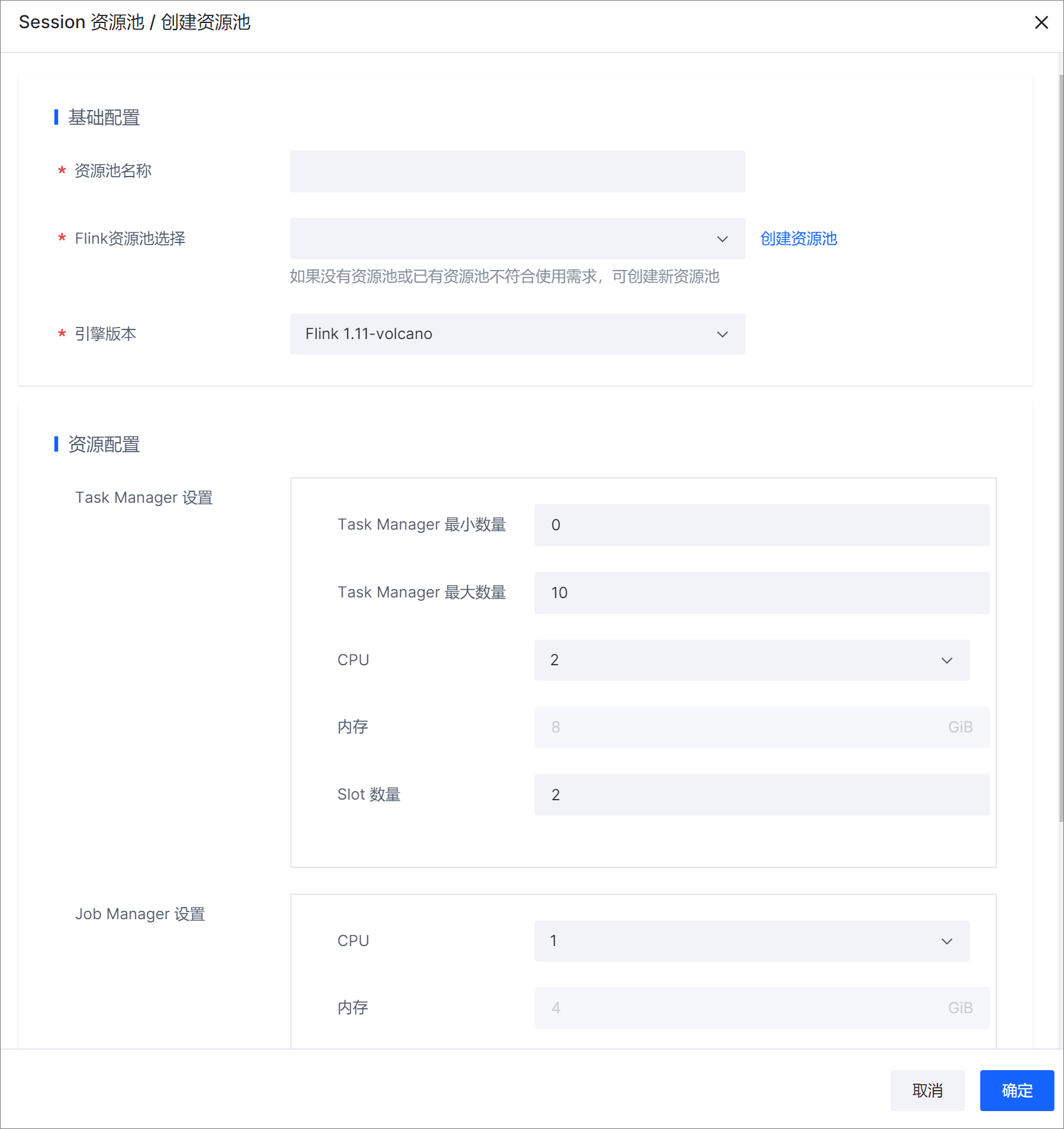
在创建资源池面板,设置基础配置和资源配置的参数,然后单击确定。
配置
说明
基础配置:必填参数。
资源池名称
自定义设置 Session 资源池名称。
支持小写字母、数字和短横线(-),且必须以小写字母或数字开头和结尾,字符长度范围为 2 ~ 63。Flink资源池选择
从下拉列表中选择目标 Flink 资源池。
引擎版本
目前支持 Flink 1.11-volcano 和 Flink 1.16-volcano 版本,建议选择与任务的引擎版本一致,否则调试任务时会提示引擎版本不匹配。
资源配置:选填参数,系统已有默认基础资源配置。
Task Manager 设置
Task Manager 最小数量
TaskManager 数量的最大最小值。
Task Manager 最大数量
CPU
TaskManager 的 CPU 核数,默认值为 2 核。
内存
TaskManager 的内存大小,默认值为 8 GiB。
Slot 数量
推荐单 Slot 使用资源不少于 1 核 4 GiB,每个 Task Manager 可以配置 2 个 Slot。
Job Manager 设置
CPU
JobManager 的 CPU 核数,默认值为 1 核。
内存
JobManager 的内存大小,默认值为 4 GiB。
自定义参数
Key-Value
根据需要可自定义设置参数。
创建完成返回 Session 资源池页面,请单击操作列下的启动按钮。
Session 资源池创建后,默认为未启动状态,需要您启动资源池。当 Session 资源池显示为运行中,表示资源池启动完成。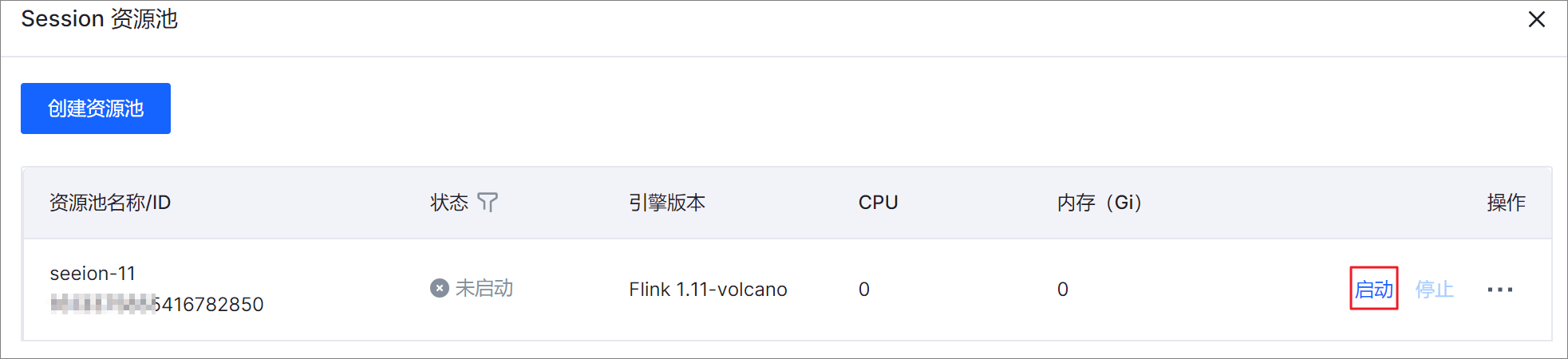
使用线上数据调试任务
使用 Session 资源池调试任务,支持使用线上数据和离线文件两种方式,本文选择使用线上数据进行调试。如需了解离线文件调试方法,请参见使用离线数据调试任务。
- 在任务开发栏目下选择目标 SQL 任务,然后在编辑区上方选择正确的执行方式和引擎版本,再单击调试。
说明
Flink Stream 类型任务选择执行方式为 STREAMING;Flink Batch 类型任务选择执行方式为 BATCH。
- 在调试任务对话框,选择使用线上数据调试类型和 Session资源池,然后单击确定。
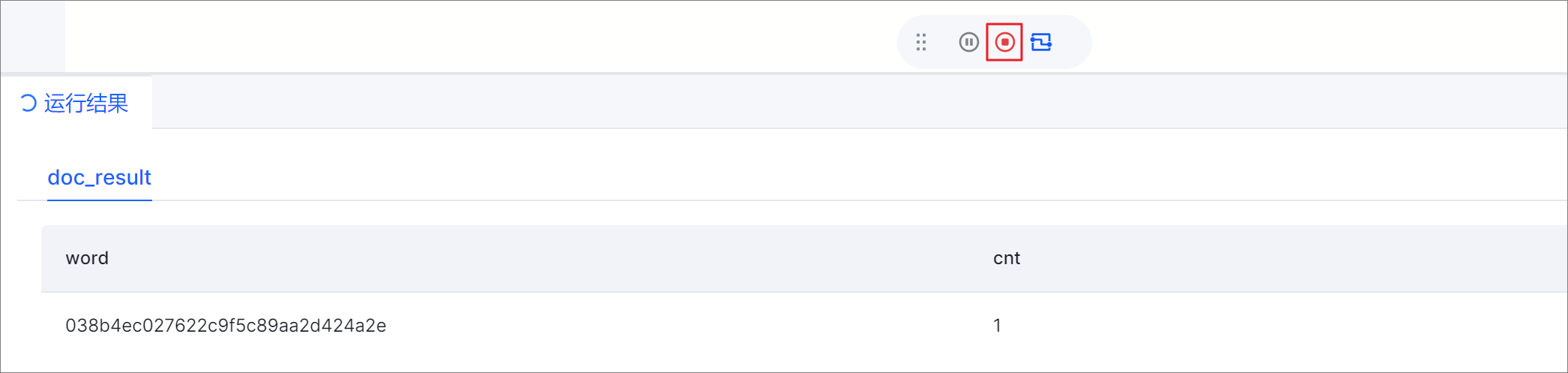
- 查看任务调试结果,然后单击红色的任务停止按钮。
系统返回到任务编辑页面,在任务编辑区下方可查看到调试结果。任务调试结果确认满足预期后,请及时停止调试,避免长时间占用资源。说明
如果您选择的 Session 资源池与任务的引擎版本不一致,将提示引擎版本不匹配。
步骤三:上线 SQL 任务
开发与生产环境隔离,当任务开发人员完成任务开发和调试后,可以将任务上线到生产环境。
在任务开发栏目下查找并单击目标任务,然后在编辑区上方选择正确的执行方式和引擎版本,再单击上线。
说明
Flink Stream 类型任务选择执行方式为 STREAMING;Flink Batch 类型任务选择执行方式为 BATCH。
在任务上线设置对话框,选择运行资源池、设置任务优先级和调度策略,然后单击确定。
系统会提示任务上线成功,可以前往任务管理页面查看。配置
说明
运行资源池
从下拉列表中选择任务运行的 Flink 资源池。
注意
如果您提交的任务开启了自动调优,则必须运行在按量付费类型的资源池。
任务优先级
系统默认预置的优先级为 L3,您可以按需设置任务优先级,数字越小优先级越高。
任务优先级决定了任务内部的调度顺序,优先级高的任务先被调度,即 L3 先于 L4 被调度。调度策略
根据需求配置任务调度策略:
- GANG:保证任务的所有实例被一起调度,即当剩余资源满足任务正常运行所需资源时才进行分配;不满足所需资源则不分配。
该策略不会出现分配资源后,任务却不能启动的现象,解决了资源死锁问题。说明
Flink Batch 任务不支持 GANG 调度策略,仅支持 DRF 调度策略。执行方式选择为 Batch,上线配置页面不会展示 GANG 策略。
- DRF:从多维资源考虑,更为合理地将资源公平分配给资源池内的各个任务,从而提升利用率。
例如:剩余10 核 40 GB 的资源,A 任务需要10 核 20 GB 资源;B 任务需要 2 核 8 GB 的资源。如果分配给 A,剩余 0 核 20 GB 资源无法被利用;DRF 策略会选择分配给 B,剩下 8 核 32 GB 可以继续给后来任务使用。
调度时长
设置为 GANG 调度策略时,需要设置调度时长。调度时长表示再次调度的时间间隔,即任务拉起不成功会再次重试调度。
如果超过调度时长,任务就会调度失败。如果设置为 0,则会一直重试。更多配置
SQL 任务支持在上线前跳过深度检查,允许任务强制上线。
默认不勾选。勾选跳过上线前检查后,表示将跳过 SQL 代码深度检查,任务将会直接上线。- GANG:保证任务的所有实例被一起调度,即当剩余资源满足任务正常运行所需资源时才进行分配;不满足所需资源则不分配。
步骤四:启动 SQL 任务
开发与生产环境隔离,任务开发人员将任务上线到生产环境后,由运维人员启动任务。
在项目左侧导航栏选择任务运维 > 任务管理。
在任务列表页面,单击操作列中的启动。
在启动任务对话框,选择任务启动方式,然后单击确定。
任务启动需要一定时长,请耐心等待。启动成功后,状态为运行中。配置
说明
启动方式
请根据实际情况选择任务启动方式:
- 从最新状态启动:以最新的 Checkpoint 或 Savepoint 启动。
- 全新启动:不使用 Checkpoint 或 Savepoint,直接启动。
- 支持直接启动。
- 支持开启从源表时间点开始消费。对于 BMQ/Kafka 等任务可以指定时间位点进行启动。
- 指定快照启动:指定目标快照(Savepoint)启动。
说明
首次上线的任务,只能是全新启动方式。
参数配置
任务携带在开发侧的并行度、Task Manager 和 Job Manager 的资源配置。在启动任务时支持您更新配置并快速生效。
说明
更新参数配置并启动任务后,将新增一个任务版本,并将最新配置同步到任务开发侧。
- 并行度:任务全局并发数。
- 单个 TaskManager CPU 数:单个 TaskManager 的 CPU 核数。
- 单个 TaskManager 内存大小:单个 TaskManager 占用的内存大小。
- 单个 TaskManager slot 数:单个 TaskManager 的 Slot 数量。
- JobManager CPU 数:单个 JobManager 的 CPU 核数。
- JobManager 内存大小:单个 JobManager 占用的内存大小。
更多设置
在任务开发变更时新增或修改算子,可能会导致任务无法从快照恢复,此时您可以选择启用允许忽略部分算子状态功能,保证任务能正常运行。
注意
- 仅当选择指定快照启动或从最新状态启动方式时,支持勾选忽略部分算子状态。
- 当您选择全新启动方式时,不支持忽略算子状态。
步骤五:查看 Flink UI
任务在生产环境上正常运行后,您可以在 Flink UI 界面了解任务运行、TaskManager、JobManager 的详细信息。
- 在项目左侧导航栏选择任务运维 > 任务管理。
- 在任务列表页面筛选目标任务,单击操作列下的 Flink UI。
浏览器将会自动打开 Apache Flink Dashboard 页面。 - 在 Apache Flink Dashboard 左侧导航栏选择 Task Managers,然后单击任务 ID。
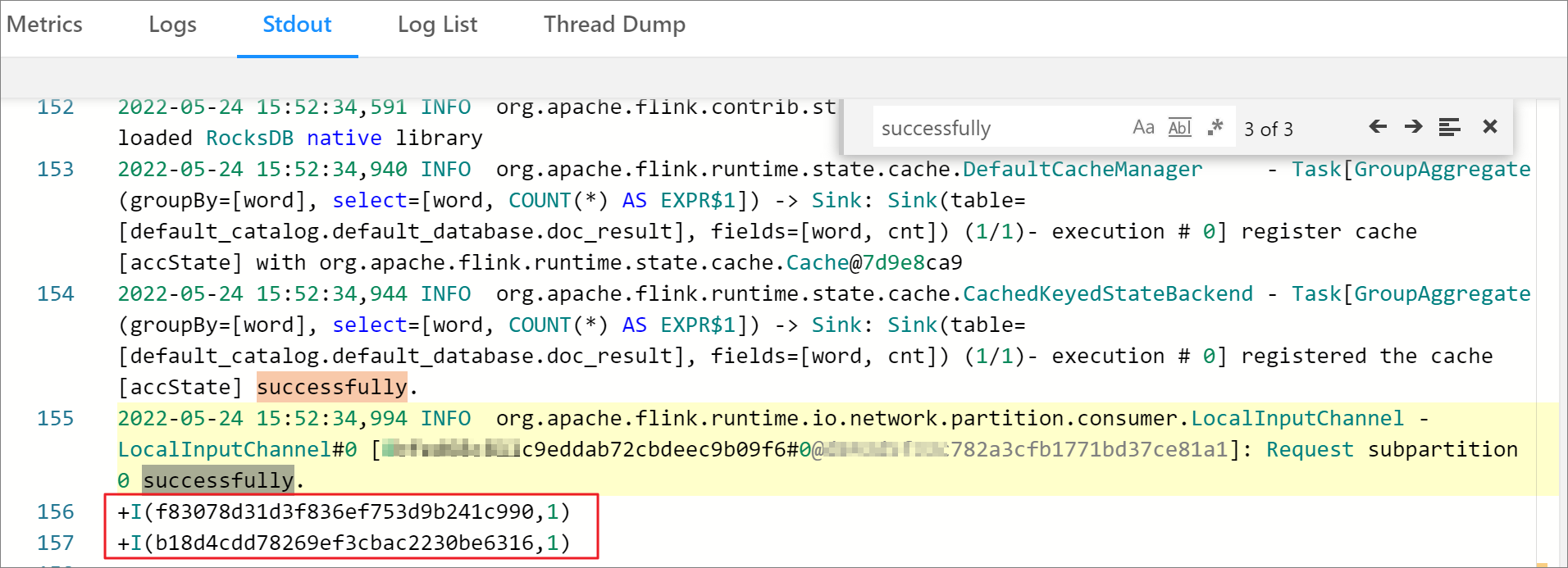
- 在任务的 Task Manager 详情页面,单击 Stdout 页签,然后在日志中搜索
successfully,查看任务执行结果。