图数据库聚合操作
 社区干货
社区干货
字节跳动自研万亿级图数据库 & 图计算实践
本文将对字节跳动自研的分布式图数据库和图计算专用引擎做深度解析和分享,展示新技术是如何解决业务问题,影响几亿互联网用户的产品体验。来源:字节跳动技术团队图状结构数据广泛存在 ... 图数据模型、支持写入原子性、部分 Gremlin 图查询语言的通用图数据库系统,在公司所有产品体系落地,我们称之为 ByteGraph。**ByteGraph 的数据模型和 API****数据模型**就像我们在使用 SQL 数据库时,先...
2022技术盘点之平台云原生架构演进之道|社区征文
下图为SmartOps架构全景: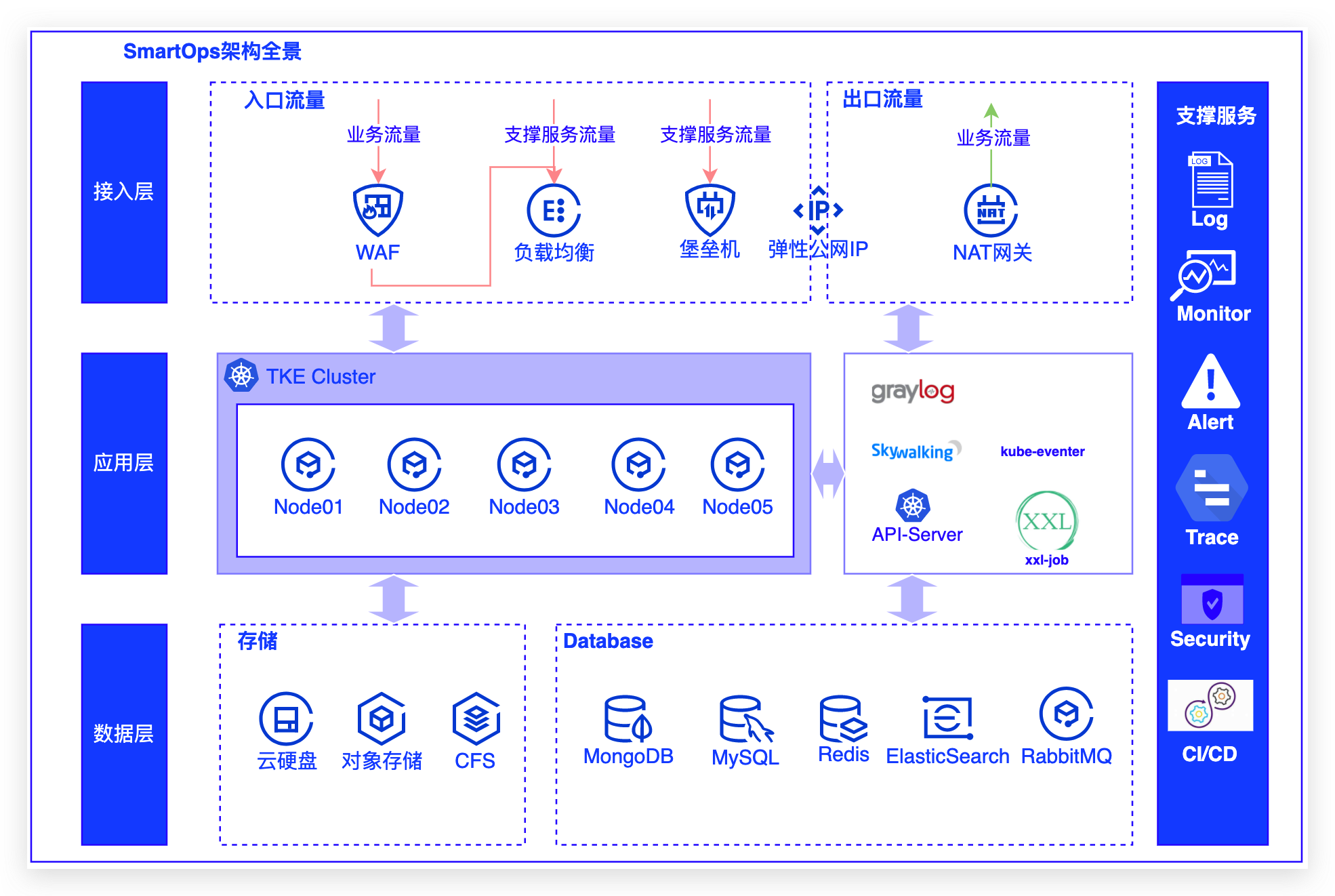- 接入层:通过WAF/SLB,配合NAT网关治理出方向流量,部署有堡垒机进行运维等其他辅助业务进行支撑;- 应用层:采用腾讯TKE进行业务容器部署,配合K8s原生服务注册发现/配置中心/分布式调度中心/日志/监控/告警/链路追踪/DevOps等构筑完整应用体系;- 数据层:存储使用有云硬盘/对象存储/CFS,数据库有Mon...
超复杂调用网下的服务治理新思路
再把它们塞到一张图后整张图变得不可读,它的意义就不大了。第二点,如果一个微服务的实例数只有几十个,这时实例的管理是比较简单的,如果实例数超过 300,那么团队不可避免地会需要使用一些分片策略或是长连接策略... ETL 把它转化成一个离线数据库。整个大框是一个 domain,它不同于 DDD 的 domain,它被称为服务域,可以理解成是一组服务的集合。字节跳动内部也参考了这种 domain 的思想,把一些服务聚合起来,产生特殊的化学反应。...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 所以在OLTP场景主要使用行存;但是行存不是完美的,例如需要遍历全表获取符合要求的行,但只取部分列进行分组/排序/聚合等操作,行存就不太适合了,在读取时,由于会读取大量的无效的列的数据,且数据量很大,在存储是系统...
 特惠活动
特惠活动
 图数据库聚合操作-优选内容
图数据库聚合操作-优选内容
 图数据库聚合操作-相关内容
图数据库聚合操作-相关内容
V2.58.0
数据连接支持直连 Hologres 在数据连接的 Hologres 数据库中新增直连作为连接方式。用户使用 Hologres 数据库的直连连接方式,可以实现支持实时数据功能,可以直接连接用户的数据库,满足用户对数据实时性的要求。 【... 如下图所示: 【新增】任务创建体验升级 (1)可视化建模任务创建页面,新增移除数据连接按钮,提高操作效率。(2)可视化建模任务创建页面,支持自由布局与网格布局切换,灵活调整任务各节点的布局。(3)可视化建模任务创建...
基础使用
使用 CREATE TABLE 命令建立一个表(Table) ,更多详细参数访问 官网文档 查看详细信息。切换数据库命令如下: USE example_db;Doris 支持单分区和复合分区两种建表方式。下面以聚合模型为例,分别演示两种分区的建表语句。 3.4.1 非分区表 建立一个名字为 table1 的逻辑表。分桶列为 siteid,桶数为 10。这个表的 schema 如下: 字段名 说明 siteid 类型是INT(4字节),默认值为10。 citycode 类型是 SMALLINT(2字节)。 username 类型是...
使用场景举例
会触发视图执行定义的 SQL,写入另外一张表。目前在 ByteHouse 根据物化视图的用途分为如下使用场景: Aggregate聚合物化视图,提升特定聚合查询的性能 Normal修改主键排序物化视图,提升对含有非主键列过滤条件查询性能 Realtime实时消费物化视图,用于对实时数据进行加工,产出数据 源数据进行ETL转化物化视图 下面以一个行为分析系统的事件表来说明上述视图的使用方法。 源表定义 SQL --创建数据库create database mv;--数据源表CR...
查看监控信息
操作步骤。 注意事项云数据库 PostgreSQL 版默认每 30 秒获取一次数据,并根据查询结果的显示粒度,将采集的数据求取平均值或最大值后进行展示。例如,当查询过去 3 小时中代理节点的 QPS 数据时,云监控查询结果的显示粒度为 2 分钟,即每次展示的数据实际上是过去 4 次查询结果的平均值。查看监控数据的方法,请参见查看监控数据。 并根据查看监控数据时选择的查询时间范围,将获取的数据根据不同的周期和方式进行聚合展示,具体规则如...
指标字段配置
在实际使用中,维度与指标字段也可以互相转换。本文将为您介绍指标字段配置的具体能力。 2.指标字段配置具体介绍 2.1 设置聚合方式功能说明 :指标字段在图表中展示聚合结果,支持对指标字段(要求字段本身不含聚合函数... 聚合结果为 2 平均 最大值 最小值 方差 标准差 分位数:支持1%、5%、10%、25%、50%、75%、90%、95%、99%分位数 操作步骤 : 点击字段 选择「聚合方式」 选择所需聚合方式,如,「最大值」 修改完成 注意 :当...
查询慢日志
具体操作,请参见创建实例。 注意事项默认展示近 5 分钟内的慢日志信息,例如慢 SQL 数量、CPU 使用率和慢 SQL 列表。 最多可以支持查看近 7 天内的慢日志数据。 由于云数据库 MySQL 版实例当前默认开启数据库代理... 您需要在慢日志发展趋势图内,单击某时间点的柱状图。 目标 说明 筛选慢 SQL 单击高级筛选,在展开的筛选区域,按需配置以下参数后,单击查询。 聚合方式:按需勾选是否聚合忽略执行 User 或聚合忽略 IP 来源,支持同时...
超复杂调用网下的服务治理新思路
再把它们塞到一张图后整张图变得不可读,它的意义就不大了。第二点,如果一个微服务的实例数只有几十个,这时实例的管理是比较简单的,如果实例数超过 300,那么团队不可避免地会需要使用一些分片策略或是长连接策略... ETL 把它转化成一个离线数据库。整个大框是一个 domain,它不同于 DDD 的 domain,它被称为服务域,可以理解成是一组服务的集合。字节跳动内部也参考了这种 domain 的思想,把一些服务聚合起来,产生特殊的化学反应。...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 所以在OLTP场景主要使用行存;但是行存不是完美的,例如需要遍历全表获取符合要求的行,但只取部分列进行分组/排序/聚合等操作,行存就不太适合了,在读取时,由于会读取大量的无效的列的数据,且数据量很大,在存储是系统...
查看指定聚合维度的数值分布
1. 场景示例 背景:如图所示为一张订单粒度的数据集,具有每笔订单的详情数据,包括订单ID、订单发生的省份、订单金额等。需求:根据省份聚合,计算各省份的总销售额(付款金额之和),并查看此数据(即各省销售额)的分布。... 操作步骤 (1)创造「各省付款金额」字段 指定依据[省份]维度,求[付款金额]之和,并保存为维度。表达式为:{fixed [省份]: sum([付款金额])} (2)对各省付款金额分段 选择字段并创建组按照步长分组,根据需求设置每个组...
