图数据库基于内存
 社区干货
社区干货
字节跳动自研万亿级图数据库 & 图计算实践
对于数据内在关系是图模型以及在图上游走类和模式匹配类的查询,比如社交关系查询,图数据库会有更大的性能优势和更加简洁高效的接口。**为什么不选择开源图数据库**图数据库在 90 年代出现,直到最近几年在数据爆炸的大趋势下快速发展,百花齐放;但目前比较成熟的大部分都是面对传统行业较小的数据集和较低的访问吞吐场景,比如开源的 Neo4j 是单机架构;因此,在互联网场景下,通常都是基于已有的基础设施定制系统:比如 Facebo...
抖音大规模实践,火山引擎向量数据库是这样炼成的
基于企业知识库的问答以及Chatdoc等工具应用。### **火山引擎****向量数据库****技术演进之路**- **存算分离的** **分布式架构** **搭建**在抖音集团内部,早期的向量化检索引擎是围绕搜索、推荐、广告业务来构建的,由于这些业务天然具有极大的数据规模,因此从一开始,就需要思考如何在向量索引中支持百亿数据的检索需求,比如图虫拥有几亿图片素材,数量规模早已超出单机内存的极限,举个例子,对于1亿条128维的Float向量,不考...
字节跳动 NoSQL 的探索与实践
这三种数据关联到一起就会形成 **图状结构** 。**自研分布式图数据库**为了满足内部 social graph 在线增删改查的场景,字节跳动自研了 **分布式图存储数据库 ByteGraph** 。针对刚才提到的图状数据结构,... **图计算系统**从图数据库又引申出来一个非常大的概念——图计算。举个例子,在 Google 上搜索时,需要基于网页的链接关系计算每个页面的 page rank,从而对页面进行排序。页面的链接关系其实就是一张图,基于网页...
字节跳动 NoSQL 的探索与实践
这三种数据关联到一起就会形成图状结构。### 自研分布式图数据库为了满足内部 social graph 在线增删改查的场景,字节跳动自研了分布式图存储数据库 ByteGraph。针对刚才提到的图状数据结构,ByteGraph 支持有向属... 从图数据库又引申出来一个非常大的概念——图计算。举个例子,在 Google 上搜索时,需要基于网页的链接关系计算每个页面的 page rank,从而对页面进行排序。页面的链接关系其实就是一张图,基于网页链接关系的 page ra...
 特惠活动
特惠活动
 图数据库基于内存-优选内容
图数据库基于内存-优选内容
 图数据库基于内存-相关内容
图数据库基于内存-相关内容
字节跳动 NoSQL 的探索与实践
用户和内容的连接:用户发布内容之后的评论、点赞、转发等,自媒体还会关注广告点击及分成收益等数据。这三种数据关联到一起就会形成图状结构。### 自研分布式图数据库为了满足内部 social graph 在线增删... 从图数据库又引申出来一个非常大的概念——图计算。举个例子,在 Google 上搜索时,需要基于网页的链接关系计算每个页面的 page rank,从而对页面进行排序。页面的链接关系其实就是一张图,基于网页链接关系的 page ra...
VikingDB:大规模云原生向量数据库的前沿实践与应用
基于向量的粗排打散等。在内部产品的不断迭代过程中,VikingDB 也逐渐契合云原生的理念,为孵化商业化向量数据库产品打下了坚实的基础。依托于 VikingDB 在字节内部积累的丰富经验,我们在火山引擎推出了 VikingD... 我们发现硬件的瓶颈主要在于内存带宽,因此我们整理出了基于内存带宽的性能预估方法。我们考虑 1000 万条 128 维 Float 向量的 ANN 计算场景,仅就一般情况粗略估算,实际中向量的分布情况会对检索性能和精度产生影响...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 而且会影响内存中cache的使用效率;在计算时,由于行数据在内存中是顺序存储在一起的,所以对 cpu cache 也很不友好。 列存就是解决上述问题的灵丹妙药,首先读取时只需要读取关心的列数据,在计算时也对cpu cache非常友...
抖音大规模实践,火山引擎向量数据库是这样炼成的
基于企业知识库的问答以及 Chatdoc 等工具应用。 火山引擎向量数据库技术演进之路 **存算分离的分布式架构搭建**在抖音集团内部,早期的向量化检索引擎是围绕搜索、推荐、广告业务来构建的,由于这些业务天然具有极大的数据规模,因此从一开始,就需要思考如何在向量索引中支持百亿数据的检索需求,比如图虫拥有几亿图片素材,数量规模早已超出单机内存的极限,举个例子,对于 1 亿条 128 维的...
分布式数据库在抖音春晚活动中的应用
缺了上述任意一个模块都很难构建出一个具有完备 ACID 特性的关系型数据库。了解关键子模块后,我们来看看计算层的数据模型。对于用户或者后端应用开发者来说,数据库可能是用户、数据库和数据表的一个集合;但是对于数据库开发者来说,数据库本质是内存数据模型和磁盘数据模型的复杂组合。我们来看看有哪些数据模型。内存(In-Memory)数据模型:首先肯定会有一个基于page/block组织的 LRU cache;还会有基于 page 组织的一个树状结构...
字节跳动的 Flink OLAP 作业调度和查询执行优化实践
**一、背景**========= 字节跳动内部有很多混合计算的需求,需要一套既支持 TP 计算,也支持 AP 计算的系统。下图是字节跳动 HTAP 系统的总体架构。系统使用内部自研的数据库作为 TP 计算引擎,使用 Flin... 主要基于三个方面的考虑:* **统一引擎降低运维成本。**字节跳动流式计算团队对 Flink 有非常丰富的运维和优化开发经验,在流批一体的基础上,使用 Flink 作为 AP 计算引擎可以降低开发和运维成本;* **生态支...
达梦@记一次国产数据库适配思考过程|社区征文
图或表不存在,字段列名不存在的异常。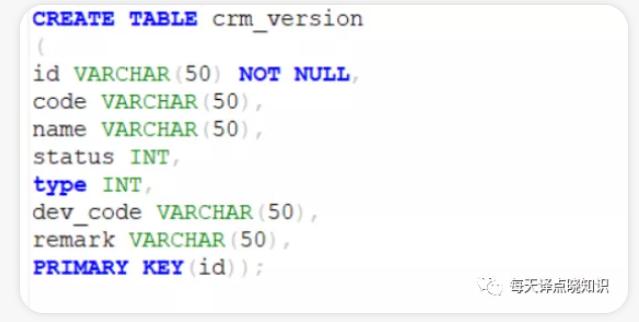若是通过**Mysql或Oracle或其他数据库,文件... db2等等数据库,那么其他关系型数据库?肯定是提供一些这样的入口可以去扩展的,只是各种框架的适配程度不一样,都在不断兼容。网上关于这块的资料并不全面,基于数据库产品名称这条线索,于是,小编封装了独立的适配器sd...
Flink on K8s 企业生产化实践|社区征文
关系型数据库等大数据 ODS ( Operational Data store ) 层进行快速的数据 ETL ,将数据抽取到特征平台进行管理,并统一了数据出口,供数据科学家、数据工程师、机器学习工程师做算法模型的数据测试、训练、推理及其他... 首先本文对 K8s 基本概念及 Flink 任务执行图进行简要介绍,接着文章对比了现有的几种 Flink on K8s 部署方式,为什么flink 要基于K8s做部署?主要有以下几个优势:- 容器环境容易部署、清理和重建:不像是虚拟...
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API,当下较为热门的查询性能缓存。**```yum源方式安装:示例:包存在yum install -y redis配置:/etc/redis.conf启动:redis/usr/sbin/redis-server /etc/redis.conf 或 redis-server & 后台运行(使用默认端口)日志:/usr/local/redis/logs/查看:redisps -ef | grep redisnetstat -tunpl|grep 6379登入:redisredis-cli -p 6379 --raw(中文数据正常显示)re...
