算法流程图如何提取数据库
 社区干货
社区干货
Flink on K8s 企业生产化实践|社区征文
提取复杂、链路过长等问题,在大数据与算法间架起科学桥梁,提供强有力的样本及特征数据支撑。平台从 Hive 、Hbase 、关系型数据库等大数据 ODS ( Operational Data store ) 层进行快速的数据 ETL ,将数据抽取到特征... 启动流程图: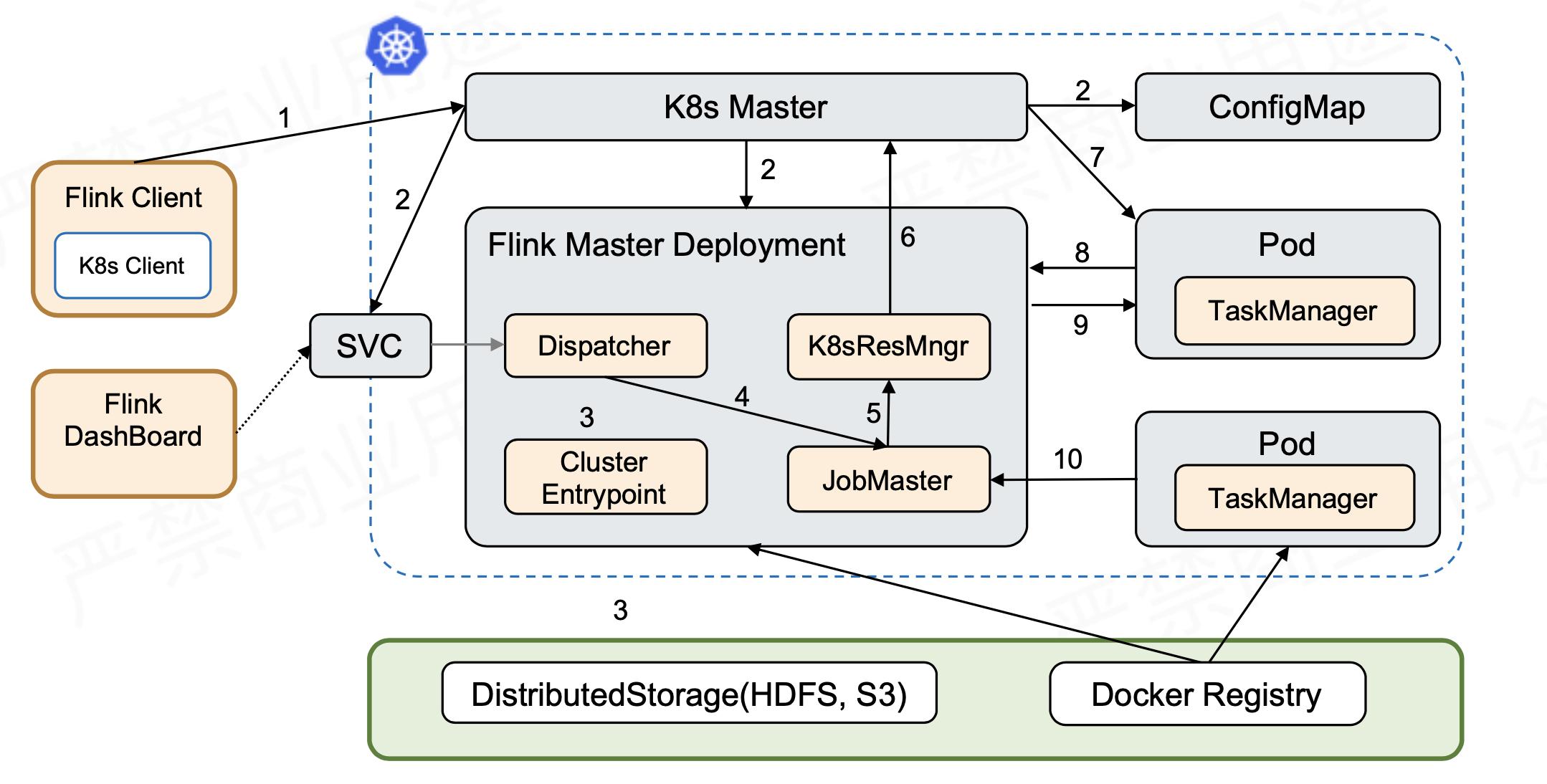- 首先创建出了 Service、Master 和 ConfigMap 这几个资源以后,F...
一文理解 HyperLogLog(HLL) 算法 | 社区征文
HyperLogLog(HLL) 算法是一种估算海量数据基数的方法,被广泛用于各个数据库产品中。与精确的基数统计算法相比,HLL 具备**可合并性 (mergeability)** ,因而可以方便地对海量数据进行并行计算,被广泛地用于大数据多维分析场景中。例如分别统计一款 APP 每个小时的 UV 以及全天的 UV,这类问题就非常适合使用 HLL 算法。本文将会由浅入深,从基本概念讲起,引导读者从直观上理解 HLL 算法背后蕴含的基本思想。# 基数统计基数 (...
万字长文带你漫游数据结构世界|社区征文
[](https://markdownpicture.oss-cn-qingdao.aliyuncs.com/blog/数据结构.png)# 数据结构是什么?> 程序 = 数据结构 + 算法是的,上面这句话是非常经典的,程序由数据结构以及算法组成,当然数据结构和算法也是相... 红黑树的算法简单一点。## 栈栈是一种数据结构,在`Java`里面体现是`Stack`类。它的本质是**先进后出**,就像是一个桶,只能不断的放在上面,取出来的时候,也只能不断的取出最上面的数据。要想取出底层的数据,只有...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。#### 2.2 NL2SQL的目标与定位从技术的角度来看,NL2SQL的本质是将用户的自然语言语句转化为计算机可... 该数据集获取自关系型数据库Official Airline Guide (OAG, 1990),包含27张表以及不到2,000次的问询,每次问询平均7轮,93%的情况下需要联合3张以上的表才能得到答案,问询的内容涵盖了航班、费用、城市、地面服务等信...
 特惠活动
特惠活动
 算法流程图如何提取数据库-优选内容
算法流程图如何提取数据库-优选内容
 算法流程图如何提取数据库-相关内容
算法流程图如何提取数据库-相关内容
AB实验设计实现与分流算法
# AB实验设计实现与分流算法**背景**在现实的产品设计场景中以及业务决策中,需要对方案进行决策。例如,App或网页端某个页面的某个按钮的颜色是用蓝色还是红色,是放在左边还是右边?传统的解决方案通常是集体... 仅依赖了配置中心和数据库,然后上游流量的请求进入AB获取实验决策全部都是本地内存操作。其中重载配置过程如上图所示:* 后台用户编辑实验信息(①)* 进行相应的增删改操作修改DB(②)* 触发发布一个静态配置,如...
抖音大规模实践,火山引擎向量数据库是这样炼成的
在数据库中存储和对比的并不是图片和视频片段,而是通过深度学习等算法将其提取出来的“特征”,“特征”提取的过程称为 Embedding,提取出的“特征”用数学中的向量来表示。向量化的目的是为了通过向量相似来进行非结... 流程是先将图片源数据上传到向量数据库,把图片数据进行向量化、存储并形成向量索引,然后,用户将要搜索的图片上传,上传后向量化,向量化的图片与向量数据库进行向量检索比对查询,获取相似度最高的结果,返回给用户。...
一文读懂火山引擎云数据库产品及选型
> **火山引擎存储&数据库产品解决方案团队**,由资深的存储&数据库解决方案架构师组成。团队致力于帮助企业与组织更好的使用火山引擎云存储与云数据库产品,针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软...
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
缓存的数据值 = 数据库中的值;- 缓存中没有该数据,数据库中的值 = 最新值。反推缓存与数据库不一致:- 缓存的数据值 ≠ 数据库中的值;- 缓存或者数据库存在旧的数据,导致线程读取到旧数据。> 为何会出现数据... 由缓存抽象层来完成缓存数据和数据库数据的更新**,时序流程图如下: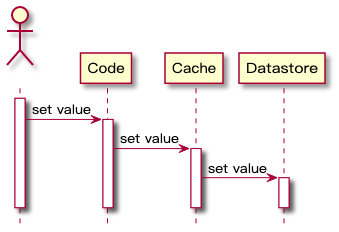`Write-Through` 的主要好处是应用系统的不需要...
分布式数据库TiDB的设计和架构
导语市场上有很多数据库产品,如Oracle、MySQL、SQLServer、NoSQL、NewSQL等,那么目前数据库圈最火的分布式关系型数据库之一TiDB你了解吗?相信很多同学以前听说过TiDB,也知道是一款国人研发的数据库,但你知道TiDB... 将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。:迁移实施
> **王志雷**,火山引擎存储&数据库解决方案架构师,专注于存储&数据库产品的解决方案规划、设计和拓展工作。 > **贾伟力**,火山引擎存储&数据库解决方案架构师,专注于存储&数据库产品的解决方案规划、设计和拓展... 并适当利用rsync算法(差分编码)以减少数据的传输,rsync算法并不是每一次都整份传输,而是只传输两个文件的不同部分。- **源端支持场景** - Linux本地文件系统 - NFS文件 - 第三方云NAS- **迁移流程** 