蚂蚁金服数据库设计图
 社区干货
社区干货
数字化转型之路-云原生与ChaosMeta
普惠金融对数据价值的利用和智能决策也提出了更高的要求。下面是蚂蚁金融云的技术架构:### 蚂蚁小程序云蚂蚁小程序云作为一家领先的金融领域云厂商,通过内置接口与蚂蚁金服的各项开...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系... 数据库领域专家 & HBase Committer。北京邮电大学硕士,曾就职于 Nebula Graph、蚂蚁金服、猿辅导等公司,一直从事数据库相关研发工作。 ■ 推荐阅读 [,能很好的解决复杂的数据运算及表间处理,多用于银行、电信等传统行业复杂业务逻辑场景中,以 Oracle 为代表。此类数据库挑战在于成本高,随着数据量增加,只能通过购买更贵更好的服务器;无法线性扩容...
蚂蚁集团混沌工程 ChaosMeta V0.5 版本发布
**空间管理:** 根据组织或活动隔离数据,确保数据的安全性和隐私性。、复盘分析总结风险点。基于业界现状和上面的问题分析,结合蚂蚁集团在混沌工程领域的多年经验,ChaosMeta 平台从设计上覆盖了“准入检测”、“流量注入”、“故障注入”...
 特惠活动
特惠活动
 蚂蚁金服数据库设计图-优选内容
蚂蚁金服数据库设计图-优选内容
 蚂蚁金服数据库设计图-相关内容
蚂蚁金服数据库设计图-相关内容
蚂蚁分工与集简云平台深度合作,实现无代码集成数百款应用
蚂蚁分工在企业服务生态开放平台已连续48个月蝉联同类冠军,是久居生态前列的头部服务商。**在服规模以上企业超过2000家,包括顾家家居、启飞智能、希恩碧、明益信、海兴电力等知名企业。**...
使用 KubeRay 和 Kueue 在 Kubernetes 中托管 Ray 工作负载
相关数据显示 Ray 已被 OpenAI/Uber/Amazon/字节跳动/蚂蚁金服等众多企业所使用。基于 Ray,Anyscale 也推出了自己的 LLM 相关商业化产品,并以成本和易用性等方向作为卖点。上图右侧展...
使用 KubeRay 和 Kueue 在 Kubernetes 中托管 Ray 工作负载
相关数据显示 Ray 已被 OpenAI/Uber/Amazon/字节跳动/蚂蚁金服等众多企业所使用。基于 Ray,Anyscale 也推出了自己的 LLM 相关商业化产品,并以成本和易用性等方向作为卖点。上图右侧展示...
KubeCon | 使用 KubeRay 和 Kueue 在 Kubernetes 中托管 Ray 工作负载
数据显示 Ray 已被 OpenAI/Uber/Amazon/字节跳动/蚂蚁金服等众多企业所使用。基于 Ray,Anyscale 也推出了自己的 LLM 相关商业化产品,并以成本和易用性等方向作为卖点。上图右...
使用 KubeRay 和 Kueue 在 Kubernetes 中托管 Ray 工作负载
相关数据显示 Ray 已被 OpenAI/Uber/Amazon/字节跳动/蚂蚁金服等众多企业所使用。基于 Ray,Anyscale 也推出了自己的 LLM 相关商业化产品,并以成本和易用性等方向作为卖点。上图右侧...
[数据库系统] 业界列式存储浅析
数据一般采用一个一个的数据块进行存储,利用顺序读写提升性能。行存的实现一般是将一行数据完整的从头到尾连续存储(超长的字段一般会单独存储,行内记录逻辑地址),连续多行构成一个页,页的尾部通常会存储索引来解决record不定长时的快速查找问题,数据排列结构如下图所示: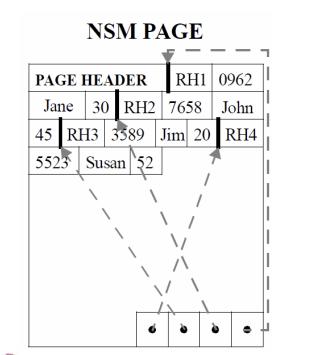列存和行存的区别主要是在...
KubeCon EU 2023 | 字节跳动云原生欧洲行回顾!
Wenbo QI(蚂蚁金服/Dragonfly 社区);Yingyang Huang(火山引擎/Dragonfly 社区)**议题简介**:Dragonfly 是一个基于 P2P 的图像和文件分发系统。本次议题主要介绍了 Dragonfly & Nydus 的系统架构以及系统设计,同时也介绍了 Dragonfly 如何在机器学习推理引擎中加速分发模型,并且会提供 Dragonfly & Nydus 在火山引擎(Volcano Engine)进行镜像加速的最佳实践,以及在镜像下载过程中的相关数据。最后,描述 Dragonfly 如何与生...
