两个工作表之间的索引引起参数错误,谷歌表格。
 社区干货
社区干货
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
这一巨大的增长引发了广泛的关注,并且使得 GPT-3 在自然语言处理任务中取得了令人瞩目的成就。 然而随着模型参数的增长,模型的大小也成为一个问题。为了解决这个问题,人们开始尝试模型小型化的方法。Chinchilla 就是一种模型小型化的尝试,相较于其前代模型,将模型参数缩小了 4 倍,但样本量却增大了 4 倍,这种方法试图在保持相对较小的模型规模的同时利用更多的数据提升模型的性能。最近最新推出的 GPT-4 模型以及 Google 最...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
多个系统之间的 ETL 也浪费了大量的资源, 同时对于研发人员来讲,也不得不学习维护多套系统。为了解决这个问题,我们开启了 Krypton 项目,这是字节跳动基础架构 计算-实时引擎, 创新应用中心, 存储-HDFS & NoSQL 团队... 导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应对各种 Workload 的系统,对于不同的 Workload,系统...
干货 | 以一次Data Catalog架构升级为例,聊聊业务系统的性能优化
做了很多修修补补的工作,系统的可维护性和扩展性变得不可忍受。比如为了支持数据血缘能力,引入了字节内部的图数据库veGraph,写入时,需要业务层处理MySQL、ElasticSearch和veGraph三种存储,模型也需要同时理解关系型... 我们发现以下两个参数对于JanusGraph的查询性能有比较大的影响:* query.batch = ture* query.batch-property-prefetch=true其中,关于第二个配置项的细节,可以参照我们之前发布的[文章](https://mp.wei...
基于火山引擎 EMR 构建企业级数据湖仓
导致了他们在演化过程中变得越来越相似。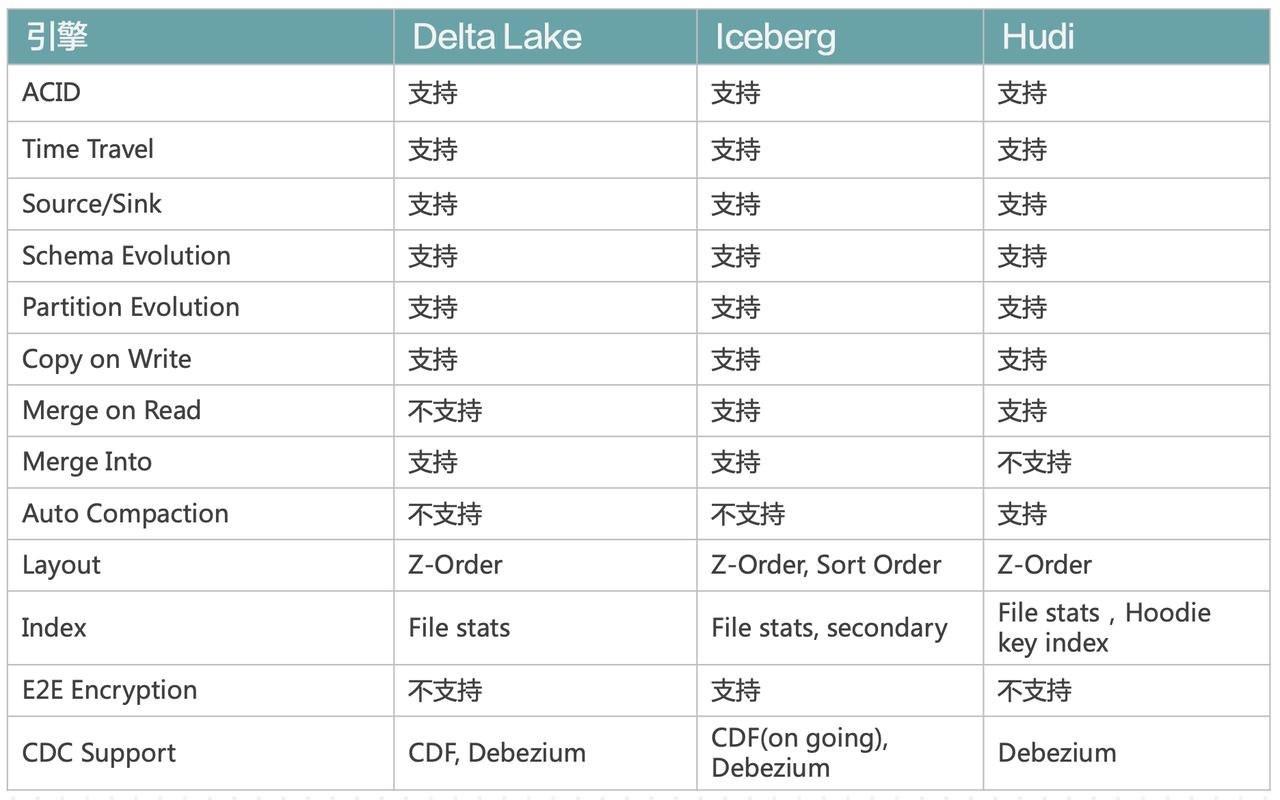可以看到,绝大部分特性这三者都是支持的。只不过在一些小的方面,三者之间是有一点区别的。这种相似性可能也会给用户的选型造成一些困扰。可以简单地从支持特性的区别以及对生态的支持等方面给选型做一些建议。下面这个表格给出了三种格式在生态方面的支...
 特惠活动
特惠活动
 两个工作表之间的索引引起参数错误,谷歌表格。-优选内容
两个工作表之间的索引引起参数错误,谷歌表格。-优选内容
 两个工作表之间的索引引起参数错误,谷歌表格。-相关内容
两个工作表之间的索引引起参数错误,谷歌表格。-相关内容
一文读懂火山引擎云数据库产品及选型
**关系型数据库**将数据存储于二维表格之中,数据以行为单位,一行数据表示一个实体信息,每一行数据的属性都是相同的,通过 SQL 语言进行操作,容易理解,广泛应用于企业的 ERP、CRM、财务系统和交易系统等核心业务系统... 不是关系型数据库中的关系,而是指不同对象之间的联系。例如,社交关系(人与人的关系)、推荐关系(人与物的关系)、关联关系(物与物的关系)等等。这类数据用关系型数据库很难处理,特别是在互联网海量数据条件下更复杂,...
API 发布历史
错误任务信息的错误码 视频剪辑错误码 2024 年 03 月发布时间 API 说明 相关文档 2024-03-29 用量查询相关 API 在请求参数中 StartTime 中添加开始时间最早不早于当前时间的 366 天的说明 用量查询 2024-03-28 Upd... 索引文件参数。 确认上传 2023-09-01 StartWorkflow GetWorkflowExecutionResult ListSnapshots StartWorkflow 的请求参数的 Input 中的 Snapshot 数组新增 SampleOffsets 采样截图自定义时间参数。 返回参数 Sn...
Go 生态下的字节跳动大规模微服务性能优化实践
微服务也为字节跳动基础架构团队带来了两个性能代价:**通信代价** ,不同服务之间通过网络进行通信,用户必须压缩数据包,将其变成与平台、语言无关的协议发送出去,由对方解码之后使用,因此会造成通信上的开销。特别是... 很容易导致微服务野蛮生长,造成治理负担。 Go 服务性能分析集群性能优化一般有如下思路:收集原始性能数据——建立指标体系——跟踪监控异常/手动分析——定位性能瓶颈——优化方案。...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
这一巨大的增长引发了广泛的关注,并且使得 GPT-3 在自然语言处理任务中取得了令人瞩目的成就。然而随着模型参数的增长,模型的大小也成为一个问题。为了解决这个问题,人们开始尝试模型小型化的方法。Chinchilla 就是一种模型小型化的尝试,相较于其前代模型,将模型参数缩小了 4 倍,但样本量却增大了 4 倍,这种方法试图在保持相对较小的模型规模的同时利用更多的数据提升模型的性能。最近最新推出的 GPT-4 模型以及 Google 最近...
分布式数据库TiDB的设计和架构
OTA行业从事过DBA运维工作、在大规模数据库自动化、平台化方面有较资深的落地经验。# 导语市场上有很多数据库产品,如Oracle、MySQL、SQLServer、NoSQL、NewSQL等,那么目前数据库圈最火的分布式关系型数据库之一... 它是基于 Google Spanner/F1 论文,未开源它的代码及技术细节,是基础软件最前沿的领域之一,技术门槛最高。NewSQL 代表产品有Spanner/F1(未开源)、CockroachDB(开源)和TiDB(开源)。新增应用:百度云爱速搭新增应用:智联自动售卖机新增应用:AIGCaaS新增应用:极致了新增应用:Imagine新增应用:用友Yonbip高级版新增应用:APIFY新增... 错误信息、内部错误码的错误变量,以及预先添加的自定义变量如:客服手机号、邮箱号、企业id、模板id、指定人员userid等,作为变量数据插入流程字段配置中,满足变量批量替换、错误监控、流程参数记录等场景使用需要。...
集简云12月新增/更新:新增更新18个功能,新增5款应用,更新21款应用,新增更新近400个动作
语聚AI连接集简云数据表新增功能:人工服务对话助手新增模型选择和支持搜索引擎新增功能:Google新增Gemini Pro模型新增功能:Google新增Gemini Pro Vision视觉模型... **表单一键发布,提升数据收集与管理能力****表单生成**功能——在数据表中创建相关工作表后,可将该工作表通过表单生成进行字段配置,发布后,即便是外部人员也可通过公开链接或扫码,不用登录就能提交...
如何构建企业内的 TiDB 自运维体系
因此我们逐步把目光转向了已经趋于成熟的分布式关系型数据库 TiDB。自 2020 年初开始使用 TiDB,随着运维体系的逐步完善,产品自身能力的逐步提升,接入业务已经涉及得物的多个 业务线,其中个别为关键业务场景。业界... 还是会走错索引,当然这里有一部分原因可能是条件过多和索引过多导致的。为了解决问题,核心服务上线的 SQL 就必须一一 Review。如果无法正确使用索引的就使用 SPM 绑定,虽然能解决,但是使用成本还是略高。希望官方继...
