LRU全关联缓存与按最近使用排序的队列是否相同?
 社区干货
社区干货
探索云原生化的服务架构体系的技术风向,攻克云原生化微服务架构的痛点和特性 | 社区征文
容器化和容器编排:容器化是将应用程序及其依赖项打包到一个独立的单元中,称为容器。容器可以在不同的环境中运行,并提供了隔离、可移植和一致性的好处。容器编排工具(如Kubernetes)可以管理大规模容器集群的部署... 相关组件可以根据需要采取适当的操作。这种架构具有高扩展性、松耦合性和适应性,特别适用于实时数据处理和事件驱动的场景。- 支持实时数据处理、流式计算、消息队列等场景。> 未来的后端服务架构将更加注重弹...
「火山引擎」数据中台产品双月刊 VOL.04
四款数据中台产品的功能迭代、重点功能介绍、平台最新活动、技术干货文章等多个有趣、有料的模块内容。## **产品迭代一览**### **大数据研发治理套件** **DataLeap**- **【新增通道任务功能】** - 数... 预览队列及服务资源使用情况,以便适配更合适的资源。 - 资源组策略调整,支持按需扩充资源并发。 - 数据资产地图中 LAS 表支持同步显示数据安全中的敏感列信息。**说明文档链接** : ### **云原生数据...
火山引擎上云迁移指南(二):迁移实施
**制作自定义系统镜像**:对于某些旧版本操作系统且无法进行操作系统升级,或当前应用、代码无人维护,无法采用重新部署的方式构建应用,可以通过制作自定义镜像方式部署应用。 #### 迁移数据盘 推荐使用开源工... 相同的主题下。- **迁移流程** 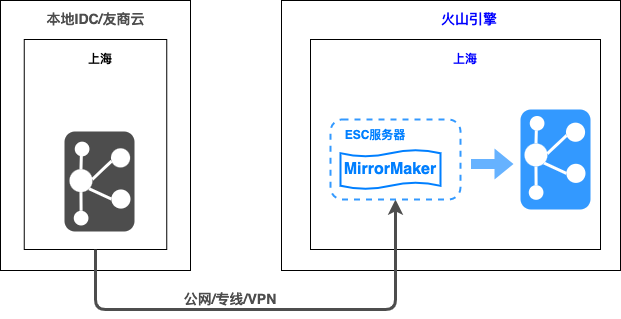- **方案优势**:支持Kafka消息数据的迁移### 消息队列:Rock...
火山引擎上云迁移指南(一):上云迁移背景与流程
配套的迁移工具和专业的迁移团队保驾护航。- 成熟的迁移方法论:将帮助用户更好控制迁移风险,助保障客户业务系统、平稳地迁移上云。- 配套的迁移工具:提高迁移效率和降低人为操作的失误风险,避免人为失误导致的数... 打开企业的新局面。- **法律安全合规**: - 汽车行业:自动驾驶场景,涉及采集地理信息中包含涉密测绘成果,需要按照《中华人民共和国保守国家秘密法》中的相关规定要求进行监管合规存储与处理。 - 金融行业:金融...
 特惠活动
特惠活动
 LRU全关联缓存与按最近使用排序的队列是否相同?-优选内容
LRU全关联缓存与按最近使用排序的队列是否相同?-优选内容
 LRU全关联缓存与按最近使用排序的队列是否相同?-相关内容
LRU全关联缓存与按最近使用排序的队列是否相同?-相关内容
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.04
四款数据中台产品的功能迭代、重点功能介绍、平台最新活动、技术干货文章等多个有趣、有料的模块内容。双月更新,您可通过关注「字节跳动数据平台」官网公众号、添加小助手微信加入社群获取产品动态~**接下来让... 预览队列及服务资源使用情况,以便适配更合适的资源。 - 资源组策略调整,支持按需扩充资源并发。 - 数据资产地图中 LAS 表支持同步显示数据安全中的敏感列信息。**说明文档链接** : ### **云原生数据...
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
操作Spark的RDD或者DataFrame的API,SparkSQL可直接输入SQL对数据进行ETL等工作的处理,极大提升了易用度。但是相比Hive等引擎来说,由于SparkSQL缺乏一个类似Hive Server2的SQL服务器,导致SparkSQL在易用性上比不上H... 以及类似用户名+密码和Kerberos等常见的用户认证能力。****(4)支持跨队列提交,同时支持在JDBC的参数里面配置Spark的相关作业参数,** 例如Driver Memory,Execute Number等。这里还有一个问题需要考虑,即用户通过...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
操作Spark的RDD或者DataFrame的API,SparkSQL可直接输入SQL对数据进行ETL等工作的处理,极大提升了易用度。但是相比Hive等引擎来说,由于SparkSQL缺乏一个类似Hive Server2的SQL服务器,导致SparkSQL在易用性上比不上H... 以及类似用户名+密码和Kerberos等常见的用户认证能力。**4. **支持跨队列提交,同时支持在JDBC的参数里面配置Spark的相关作业参数,**例如Driver Memory,Execute Number等。这里还有一个问题需要考虑,即用户通...
基于国产化环境的金融级业务系统性能优化实践|社区征文
操作系统以及分布式数据库,具有高性能、低成本、弹性扩展、敏捷交付等特点,有效解决传统架构的性能瓶颈。系统从应用架构上构建了完善的业务中台能力,真正做到系统解耦,支持对业务服务场景进行整合重构,为产品创新和... 不需要swap进行缓存)。Swap分区状态查询:关闭swap,命令 swapoff:**:ht...
免费公测|火山引擎云原生消息引擎公测正式开启!
易运维性差,对于集群数据的 Balance 以及升级操作极易引起集群抖动和流量分布不均。针对上述问题,火山引擎基于字节内部实践推出了自研消息中间件产品——**云原生消息引擎** **(** **简称** **BMQ** **)** ,... **流量削峰** - 若同一时间有大量客户端请求应用服务(如商品秒杀场景),此时容易因请求流量不可控,而导致应用服务短时间无法及时处理,造成系统崩溃。引入BMQ消息系统后,可将高并发请求缓存至消息队列中逐一...
第一现场|字节跳动开源BitSail:重构数据集成引擎,走向云原生化、实时化
项目源码和内核,对批处理相关的机制做了大量改进,才让批作业得以比较平稳地跑起来。2020-2021 年数据集成引擎演进到 V2.0 版本,团队基于 Flink 构造了 MQ-Hive 的实时数据集成通道,用于将消息队列中的... 消息队列缓存等能力。这与典型的基于 ELT 模式的数据集成框架(如 Airbyte、DataX 或 Sqoop)存在一些区别,因此定位也有所不同。而 Apache SeaTunnel 是一个相对还在快速变化的项目,它的架构基于 Spark 和 Flink 之上...
「火山引擎数据中台产品双月刊」 VOL.07
四款数据中台产品的功能迭代、重点功能介绍、平台最新活动、技术干货文章等多个有趣、有料的模块内容。## **产品迭代一览**### **大数据研发治理** **套件** **DataLeap**- **【** **公有云** **-华南区服... 队列权重。 - 运维管控能力大幅提升 - 底层平台:支持运行在基于国产芯片架构的服务器上,包括国产 ARM 架构-鲲鹏,以及其他架构(至少支持 Intel X86 架构)的服务器上。兼容主流的 Linux 操作系统,...
字节开源 Monoio :基于 io-uring 的高性能 Rust Runtime
Rust 可以生成足够高效且安全的机器码。但是一个应用程序除了计算逻辑以外往往还有 IO,特别是对于网络中间件,IO 其实是占了相当大比例的。 程序做 IO 需要和操作系统打交道,编写异步程序通常并不是一件简单的... 只有一个关联类型和一个 poll 方法。``` pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'\_>) -> Poll ; } pub enum Poll { Ready(T...
