NLP二元分类模型为每个单词输出一个类别。
 社区干货
社区干货
图谱构建的基石: 实体关系抽取总结与实践|社区征文
# 引言作为一个专注于NLP的算法技术团队,我们一直致力于知识智能在各业务场景的价值落地,随着NLP技术的逐渐演变:从词表为王到词向量,再到以BERT为代表的预训练模型,再到最近横空出世的ChatGPT,让“技术赋能业务”... 在NLP中,实体关系抽取则是致力于从自然语言文本中识别出实体对并判断实体间特定语义关系的任务,输入的是一句文本,输出的是SPO三元组(Subject-Predicate-Object)。举例说明:例:渣津龙岗坪商周遗址位于渣津镇东郊...
人工智能之自然语言处理技术总结与展望| 社区征文
NLP(自然语言处理)。而要实现真正的人工智能,就必须能够实现认知智能,所以研究和学习自然语言处理技术就显得至关重要。 自然语言处理是计算机科学、信息工程、人工智能、语言学这几个学科的交叉学科,是通过计算机来解决人类自然语言的问题,尤其是通过编程去处理和分析大量的自然语言数据。如果将自然语言处理领域进行细分,那么它包括自然语言理解(NLU)、自然语言生成(NLG)两大子领域。细分领域包括文本分类、命名实体识别、...
文本向量化模型新突破——acge_text_embedding勇夺C-MTEB榜首
文本向量化模型的突破与检索增强生成RAG的联系?# 一、文本向量化模型新突破——acge模型## 1.1、文本向量化模型文本向量化模型是自然语言处理(NLP)中的一项核心技术,它可以将单词、句子或图像特征等高维的离散... 当文本信息被转换为向量形式后,输出的结果能够进一步地为多种后续任务提供有力支持,如: - **搜索**:向量化使得搜索引擎能够根据查询字符串和文档之间的向量相似性来排名搜索结果,排名靠前的结果通常与查询字符串...
集简云2月更新合集:新增权限管理、流程分享功能,集成18款应用,更新8款应用
火山引擎内容分析是基于业内先进的NLP技术,提供丰富的文本分析能力,包括文章关键词提取、文章摘要生成、文章情感倾向分析、文本纠错等,可应用于个性化推荐、话题聚合、文章搜索等场景。  特惠活动
特惠活动
 NLP二元分类模型为每个单词输出一个类别。
-优选内容
NLP二元分类模型为每个单词输出一个类别。
-优选内容
 NLP二元分类模型为每个单词输出一个类别。
-相关内容
NLP二元分类模型为每个单词输出一个类别。
-相关内容
火山引擎在机器写作和机器翻译方面的最新进展
我们通常会有一个输入,输入也是一个序列,我们要针对这个输入做一个输出,例如机器翻译,给定一个输入的英文句子(X),我们要输出一个目标语言中文的句子(Y),所以我们要对 YX 这样一个条件概率去建模,同样可以用之前提到的 Transformer 模型来对这个概率建模。 把深度生成模型按照方法类别去归一个类,大致可以分成这样几类:按照自然估计的方法可以分成概率密度有没有显式密度(explicit density),以及隐式密度(implicit density)。显式...
集简云2月更新合集:新增权限管理、流程分享功能,集成18款应用,更新8款应用
火山引擎内容分析是基于业内先进的NLP技术,提供丰富的文本分析能力,包括文章关键词提取、文章摘要生成、文章情感倾向分析、文本纠错等,可应用于个性化推荐、话题聚合、文章搜索等场景。 和视觉专家模块。ViT编码器:在 CogVLM-17B 中,我们采用预训练的 EVA2-CLIP-E。MLP 适配器:MLP 适配器是一个两层的 MLP(SwiGLU),用于将 ViT 的输出映射到与词嵌入的文本特征相同...
CogVLM:智谱AI 新一代多模态大模型
致力于开发更加强大的多模态大模型。 基于对视觉和语言信息之间融合的理解,我们提出了一种新的视觉语言基础模型 CogVLM。CogVLM 可以**在不牺牲任何 NLP 任务性能的情况下,实现视觉语言特征的深度融合。**我们... 预训练大语言模型(GPT-style)和视觉专家模块。**ViT编码器:** 在 CogVLM-17B 中,我们采用预训练的 EVA2-CLIP-E。**MLP 适配器:** MLP 适配器是一个两层的 MLP(SwiGLU),用于将 ViT 的输出映射到与词嵌入的文本特...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
通过配合相关规则及其他语义模型,能够对一些简单常见的用户问题转换成相应的SQL。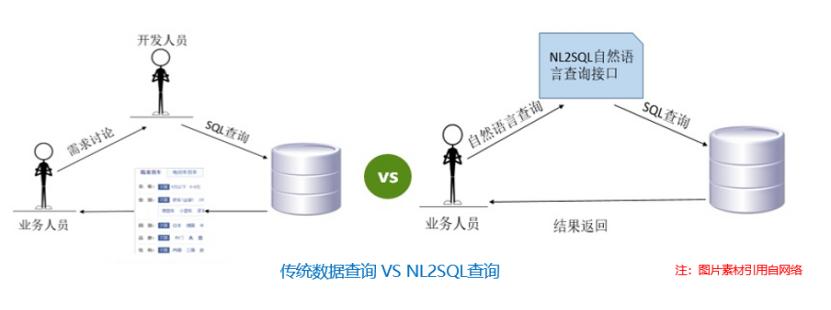... 条件符号类型,条件值] }}下面看一个实际案例:(1)业务问题为净资产收益率达到25以上或者季度每股盈余达到2以上的有哪些证券?(2)对应的SQL为`select col_1 from Table_43b0a2f31d7111e9b86df40f24344a0...
中原银行小微流水智能分析探索与实践|社区征文
授信审批以及评分卡模型调优等场景。### 3.1 算法逻辑少样本自然语言处理指的是NLP任务只附带少量的标记样...
从 QoS 到 QoE,RTC 的用户体验该如何评判?
卡顿相关类还是其他类别的主观体验的评价。