NLP的工作流程是什么?
 社区干货
社区干货
CVer从0入门NLP——GPT是如何一步步诞生的|社区征文
# CVer从0入门NLP——GPT是如何一步步诞生的|社区征文## 写在前面> Hello,大家好,我是小苏👦🏽👦🏽👦🏽>之前的博客中,我都为大家介绍的是计算机视觉的知识,随着ChatGPT的走红,越来越多的目光聚焦到NLP领域,... 是一个意思啦,接下来我们来看每条数据,即这个(3,2)维的向量,以第一条为例:这个3表示输入序列长度,表示每条数据又有三个小部分构成,分别为[-0.0657, -0.9015]、[-0.0324, -0.5666]、[-0.2630, 2.4861]。这是什么意思...
图谱构建的基石: 实体关系抽取总结与实践|社区征文
三元组的过程称为关系抽取(relation extraction)。一般情况下,我们会尽量把关系抽取抽象成若干三元组的抽取,而不会做n元组(n>3)的抽取。在NLP中,实体关系抽取则是致力于从自然语言文本中识别出实体对并判断实体间特定语义关系的任务,输入的是一句文本,输出的是SPO三元组(Subject-Predicate-Object)。举例说明:例:渣津龙岗坪商周遗址位于渣津镇东郊河对岸台地上(水车村)。据许智范撰写的《江西考古资料汇编·修水发现二处古...
2021 年我的NLP技术应用“巡径”之旅|社区征文
**我的技术回顾与展望-2021 年我的NLP技术应用“巡径”之旅******# **开启文本挖掘的AI探索**随着建筑数字化概念的兴起,我所研究领域之一:建筑设施智能化应用今年来也开始从基础建筑信息化建设向基于人工智能、大数据分析为核心的智能化、数字化场景的进化过程中。在建筑设施智能化数据应用过程中每天都会产生大量文本数据诸如:维保工单、应急指南、维修手册之类文本数据,如果将公司数据类型80%的文本数据进行应用,通过文...
火山引擎大规模机器学习平台架构设计与应用实践
NLP 等。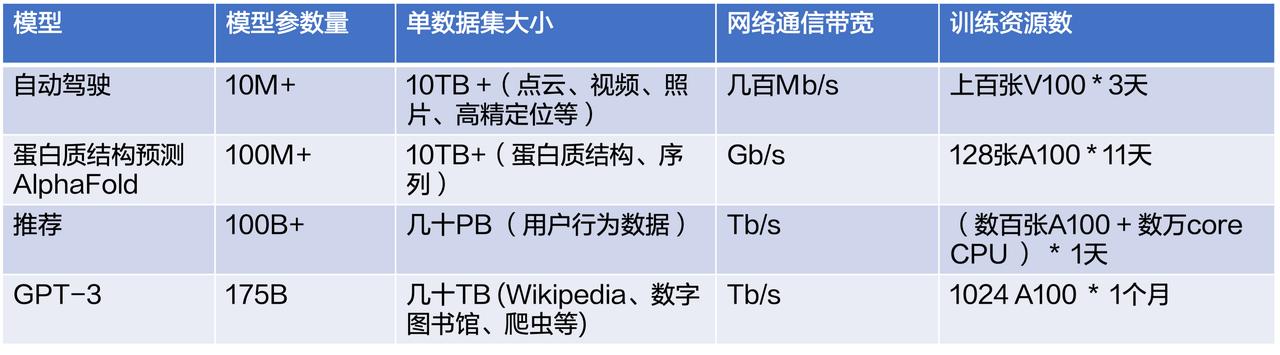可以看到不同应用场景下的参数和数据集、模型训练过程中的网络通信... 直接通过程序读 TOS 往往不太方便,需要有一层缓存的能力。因此我们加了一层 CloudFS 来提供程序和 TOS 之间的透明缓存加速。CloudFS 提供了:- FUSE Client:提供 Posix 文件系统接口,支持模型训练场景常用 API;...
 特惠活动
特惠活动
 NLP的工作流程是什么?
-优选内容
NLP的工作流程是什么?
-优选内容
 NLP的工作流程是什么?
-相关内容
NLP的工作流程是什么?
-相关内容
人工智能之自然语言处理技术总结与展望| 社区征文
灵活应用到自己的工作生活中。# 2. 预训练语言模型 预训练语言模型本质上属于自监督学习。那什么是自监督学习呢?自监督学习是在无须提供人工标注数据的基础上,通过数据上构造的监督信号进行学习。本质上它属于上文中提到的科学的利用大量未标记数据的范畴。但它的巧妙之处在于,在数据本身上构建监督信号,则省去了人工标注数据的过程。 2018年在NLP领域出现了非常著名的BERT模型,它是利用无监督的数据,以自监督的形式...
字节跳动智能音频信号处理的应用实践
## 音频信号处理发展趋势从我这些年的工作过程中,我把音频信号处理分为了三个大的部分:- 最基础的部分是算法,包括自适应滤波器、阵列信号处理以及心理声学和深度学习等算法技术。- 算法基础可以保证上层关... 是在视频场景下声场重建技术的应用。除此之外,我们在多播小说场景中的声场环境重建也有一些应用实践。### 多播小说声场环境打造多播小说相比于单播小说的一个最大区别就是它会用一个小说篇章的 NLP 来对小说中...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
我们建立了两大训练平台:推荐广告训练平台和通用的 CV/NLP 训练平台。推荐广告平台每周训练规模达到上万个模型,而 CV/NLP 平台的训练规模更是每周高达 20 万个模型。如此庞大的模型训练规模背后离不开海量的训练样... 我们可以在相对较短的时间内完成训练过程并进行 A/B 测试验证。另外,**特征工程** **越来越自动化、** **端到端** **化**。在传统的机器学习中,特征工程是非常重要的一环,通常需要大量的人工、时间和精力来处理数...
使用 AI 模型
当您在 AI 节点上部署模型服务后,您可以开始体验模型。本文介绍体验模型的基本流程。 准备工作 部署模型服务目前提供了名为sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2的公共模型。部署该模型后,可以通过句子、段落或整个文档的嵌入(embedding),来描述文本的语义内容,这些嵌入可作为其他 NLP 任务的输入特征。该模型具有多语言能力,能够支持广泛的国际化应用场景。如何部署服务,请参见启动模型。 安装opensear...
如何在火山引擎中使用 NVIDIA Clara 平台--以 AutoDock 为例
NLP、医学图像和医疗设备提供 SDK、容器等工具集。这些工具有助于快速启动AI模型开发并加速工作流程。 按需使用,降低成本: 火山引擎机器学习平台提供的海量算力,可以供企业按需使用、按量付费,尤其在业务快速发展... 使用场景作为医疗保健和生命科学领域的应用程序框架,NVIDIA Clara 为开发人员、数据科学家、生物信息学家、人工智能工程师和研究人员提供了多个软件库、SDK 和应用程序。在火山引擎机器学习平台中创建训练任务时...
万字长文带你弄透Transformer原理|社区征文
我先来简单说说我们为什么采用transformer结构,即transformer结构有什么优势呢?在NLP中,在transformer出现之前,主流的框架是RNN和LSTM,但这些框架都有一个共同的缺陷,就是程序难以并行化。举个例子,我们期望用RNN来进行语言的翻译任务,即输入`I Love China`,输出`我爱中国`。对于RNN来说,要是现在我们要输出`中国`,就必须先输出`我`和`爱`,这个过程是难以并行的,即我们必须先得到一些东西才能进行下一步。 **【注:这里不知大家能...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
我们建立了两大训练平台:推荐广告训练平台和通用的 CV/NLP 训练平台。推荐广告平台每周训练规模达到上万个模型,而 CV/NLP 平台的训练规模更是每周高达 20 万个模型。如此庞大的模型训练规模背后离不开海量的训练样... 我们可以在相对较短的时间内完成训练过程并进行 A/B 测试验证。另外, **特征工程** **越来越自动化、** **端到端** **化**。在传统的机器学习中,特征工程是非常重要的一环,通常需要大量的人工、时间和精...
工作原理
在您的业务域名www.test.com接入全站加速服务后,在您的用户发起 HTTP 请求时,全站加速加快客户端请求内容分发的流程如下: 用户请求获取源站域名www.test.com下的动态内容或静态内容,先向本地DNS发起域名解析的请求。 本地DNS检查缓存中是否有www.test.com的IP地址记录。如果有IP记录,系统将IP地址记录返给终端用户。跳转第6步。 如果没有IP记录,系统将通过权威DNS服务器查询。跳转第3步。 权威 DNS 服务器解析www.test.com时,将...
火山引擎VeDI最新分享:消费行业的数据飞轮从“四更”开始
=&rk3s=8031ce6d&x-expires=1716049291&x-signature=P%2BNLpauevK1gkJUaXLlYp8PK%2FQc%3D)聚焦更细分的消费行业企业,他们在数字化过程中具有三个明显的共性特征——“业务形态广”、“触达人群多”、“数据来源杂... 在数据资产层首先做的是实现数据的治理,企业在建设数据资产过程中,必须要通盘了解组织,了解规范和流程等,也就是做好数据治理咨询。 2. 其次,在做好贴近业务的数据治理咨询后,下一步才是数据研发和治理,进...
