没有被选中的cuda设备
 社区干货
社区干货
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如... 用户需要根据自身操作系统以及网络条件来选择相关配置项,生成不同的安装命令,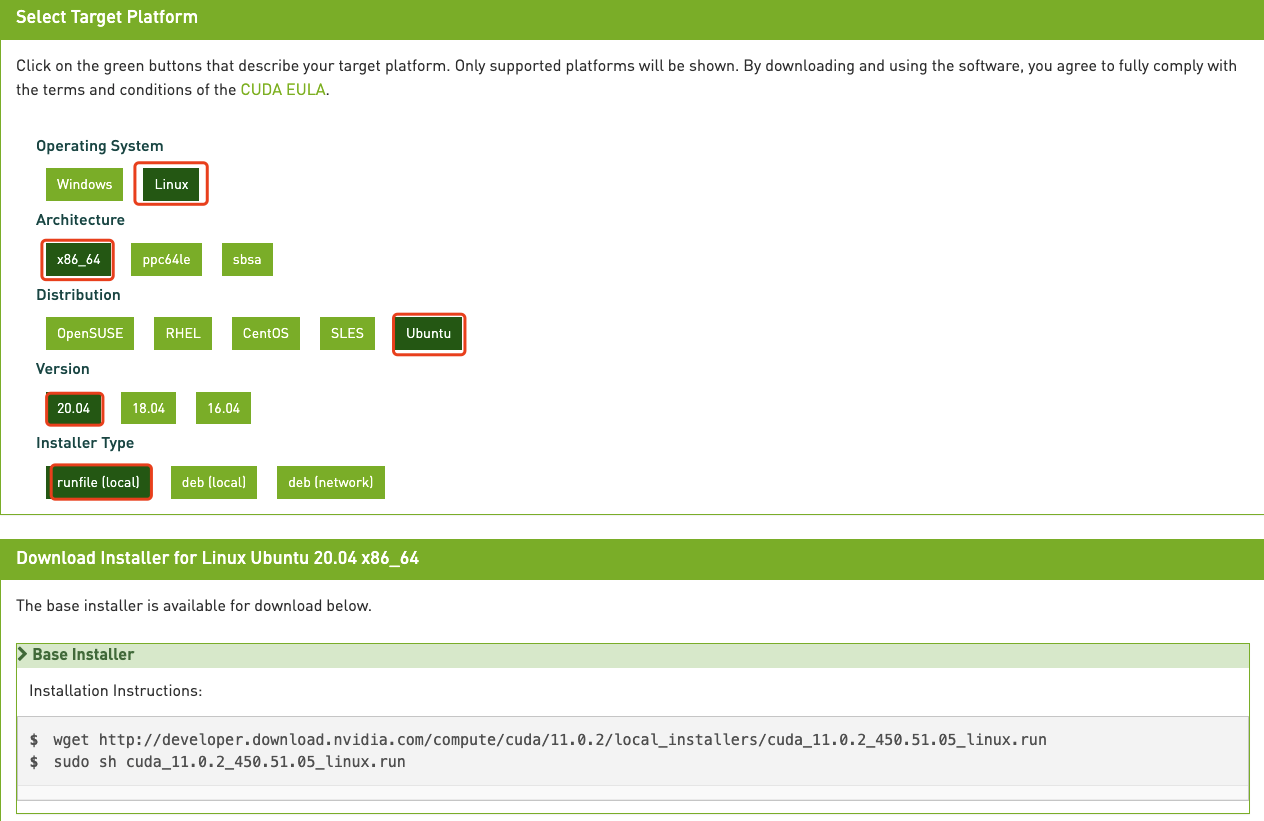此处演示为Ubu...
GPU在Kubernetes中的使用与管理 | 社区征文
硬件加速设备类型有多种,比如说GPUs、NICs、FPGAs,而且它们的厂商也不止一家,Kubernetes要想挨个支持是不现实的,所以Kubernetes就把这些硬件加速设备统一当做`扩展资源`来处理。Kubernetes在Pod的API对象里并没有提供像CPU那样的资源类型,它使用我们刚说到的`扩展资源`资源字段来传递GPU信息,下面是官方给出的声明使用nvidia硬件的示例:```apiVersion: v1kind: Podmetadata: name: cuda-vector-addspec: restartPo...
AI ASIC 的基准测试、优化和生态系统协作的整合|KubeCon China
没有通用芯片上复杂的电路逻辑,而同样的芯片面积的情况下,ASIC 能给算力预留的芯片面积则更大,也更容易做出算力更高的产品;而相应的,AI ASIC 在通用性上,受限于架构,就不如 CPU、GPU,一般而言只能运行 AI 负载,不能... 如何选择适合的产品本身就是一个问题。这点相信对于使用 GPU 产品的公司很难领会,但面临市场上五花八门的 AI 加速芯片,如何选择适合业务的产品本身就会是一个问题。 **第二点,不可控性高** 。和 GPU 不一样,AI...
大模型:深度学习之旅与未来趋势|社区征文
如何在大量的优化策略中根据硬件资源条件自动选择最合适的优化策略组合,是值得进一步探索的问题。此外,现有的工作通常针对通用的深度神经网络设计优化策略,如何结合 Transformer 大模型的特性做针对性的优化有待进... device = torch.device("cuda" if torch.cuda.is_available() else "cpu") input_tensors = input_tensors.to(device) model.to(device) with torch.no_grad(): outputs = model(input_t...
 特惠活动
特惠活动
 没有被选中的cuda设备-优选内容
没有被选中的cuda设备-优选内容
 没有被选中的cuda设备-相关内容
没有被选中的cuda设备-相关内容
AI ASIC 的基准测试、优化和生态系统协作的整合|KubeCon China
没有通用芯片上复杂的电路逻辑,而同样的芯片面积的情况下,ASIC 能给算力预留的芯片面积则更大,也更容易做出算力更高的产品;而相应的,AI ASIC 在通用性上,受限于架构,就不如 CPU、GPU,一般而言只能运行 AI 负载,不能... 如何选择适合的产品本身就是一个问题。这点相信对于使用 GPU 产品的公司很难领会,但面临市场上五花八门的 AI 加速芯片,如何选择适合业务的产品本身就会是一个问题。 **第二点,不可控性高** 。和 GPU 不一样,AI...
NVIDIA驱动FAQ
选择已预装GPU驱动的GPU版公共镜像,详情请参见使用预装GPU驱动的GPU版镜像。 在已有实例上安装GPU驱动若您在创建GPU实例时未选择自动安装GPU驱动,为确保您能够正常使用GPU实例,请参考安装GPU驱动和安装CUDA工具包... CUDA版本。 如何查询GPU显卡的详细信息?不同操作系统的GPU实例,查看GPU显卡信息的操作如下: Linux操作系统,您可以执行nvidia-smi命令,查看GPU显卡的详细信息。 Windows操作系统,您可以在设备管理器中查看GPU显卡的...
大模型:深度学习之旅与未来趋势|社区征文
如何在大量的优化策略中根据硬件资源条件自动选择最合适的优化策略组合,是值得进一步探索的问题。此外,现有的工作通常针对通用的深度神经网络设计优化策略,如何结合 Transformer 大模型的特性做针对性的优化有待进... device = torch.device("cuda" if torch.cuda.is_available() else "cpu") input_tensors = input_tensors.to(device) model.to(device) with torch.no_grad(): outputs = model(input_t...
【高效视频处理】一窥火山引擎多媒体处理框架-BMF|社区征文
它还支持不同框架如CUDA和OpenCL之间的异构计算。从这些建议简单实验开始, 开发者就可以感受到BMF模块化设计及其强大的处理能力。同时,它提供Python、C++和Go三种语言接口,语法简洁易用,无门槛上手。通过这些基础... 跨数据类型跨设备的数据流转 ackend、以及常用的跨设备 reformat、color space conversion(转换)、tensor 算子等 SDK。- **模块层:** 包含了具备各种原子能力的模块,提供多种语言的模块开发机制,用户可根据自身...
GPU推理服务性能优化之路
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。CUDA的架构中引入了主机端(host, cpu)和设备(device, gpu)的概念。CUDA的Kernel函数既可以运行在主机端,也可以运行在设备端。同时主机端与设备端之间可以进行数据拷贝。CUDA Kernel函数:是数据并行处理函数(核函数),在GPU上执行时,一个Kernel对应一个Grid,基于GPU逻辑架构分发成众多thread去并行执行。CUDA ...
字节跳动端智能工程链路 Pitaya 的架构设计
随着算法设计和设备算力的发展, **AI 的端侧应用** 逐步从零星的探索走向 **规模化应用** 。行业里,FAANG、BAT 都有众多落地场景,或是开创了新的交互体验,或是提升了商业智能的效率。 **Client AI**是字节跳... 当前系统资源占用情况进行择优选择与调度。* 高性能:支持多核并行加速和低比特计算(int8,int16,fp16),降低功耗的同时提升性能,整体性能在业界持续保持领先。**4.3 端智能核心配套能力****4.3.1 端监控**...
我的AI学习之路----拥抱Tensorflow 拥抱未来|社区征文
但这并没有关系,因为时间无言,相遇即缘!😜 # 写在前面2020年10月08日,我正式接触编程的第一天。那天我记得很清楚,那是我第一次从学长口中听说到Python,和大多数理科生一样,我不喜欢去写东西,从小写一篇作文半天... 3.CUDA8.04.cuDNN5.Python 3.5**需要注意的是,CUDA8.0是NVIDIA显卡才能安装的,不安装CUDA8.0的话,TensorFlow只能用电脑的CPU来计算了,计算速度会大打折扣。## 2.TensorFlow安装过程### 2.1 安装anaconda进...
关于对Stable Diffusion 模型性能优化方案分享 主赛道 | 社区征文
要确保模型在端侧设备上的高效运行,需要面对一系列挑战,包括性能瓶颈和资源利用率。通过模型优化方案,参赛者将深入挖掘Stable Diffusion技术的性能潜力,结合oneAPI技术堆栈,实现在指定硬件平台上的部署优化,为生成图任务提供更高效、更稳定的解决方案。本篇文章就我参与的比赛的一些心得感受,优化思路作为分享内容呈现给大家,这和上一篇不同,是一个全新的优化方向,本人也在比赛中实现了部分内容,话不多说,现就就开始今天的分享!...
字节跳动端智能工程链路 Pitaya 的架构设计
随着算法设计和设备算力的发展,**AI 的端侧应用**逐步从零星的探索走向**规模化应用**。行业里,FAANG、BATZ 都有众多落地场景,或是开创了新的交互体验,或是提升了商业智能的效率。**Client AI**是字节跳动产研架... **高通用**:支持**CPU/** **GPU** **/** **NPU** **/** **DSP** **/** **CUDA**等处理器、可以结合处理器硬件情况、当前系统资源占用情况进行**择优选择与** **调度**。 - **高性能**:支持**多核并行加速**和...
