没有被列入HSTS预加载的情况下?
 社区干货
社区干货
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
绝大多数情况下我们只关心任务的最终状态,而无需关心引起状态变化的具体 event。因此,我们可以只将 `KVStore` 持久化下来,而不需要存储大量冗余的 event 信息。此外,`KVStore`原生支持了 Kryo 序列化,性能明显于 J... 读取`UIMetaFile`,反序列化出`UIMetaStore`。- 去掉了`FsHistoryProvider`的路径扫描逻辑;每次 UI 访问,根据 appid 和路径规则,直接去读取 UIMetaFile 解析。这使得 UIService 无需预加载所有文件元信息,不需要...
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
绝大多数情况下我们只关心任务的最终状态,而无需关心引起状态变化的具体 event。因此,我们可以只将 `KVStore` 持久化下来,而不需要存储大量冗余的 event 信息。此外,`KVStore`原生支持了 Kryo 序列化,性能明显于 J... 直接去读取 UIMetaFile 解析。这使得 UIService 无需预加载所有文件元信息,不需要随着任务数量增加提高服务器配置,方便了水平扩展。优化1. #### **避免重复写**由于每个 stage 完成都会触发写...
火山引擎DataLeap:「数据血缘」踩过哪些坑?来看看字节跳动内部进化史
第三版血缘存储模型相对于前两版的升级点如下:* 以任务为中心。黄色圆圈为任务节点,数据加工逻辑产生血缘,因此我们把数据加工逻辑抽象为任务节点,血缘的建立则以任务为媒介,任务成为血缘中心。也就是说,表1、表2、表3之间的血缘,是通过任务 a 完成构建。假设没有任务 a ,则三个表之间的血缘也不存在。* 表血缘和字段血缘模型统一,在字段血缘之间没有具体任务的情况下,我们会抽象出虚拟的任务来统一模型。由此,任务和任务之间...
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
如下图所示。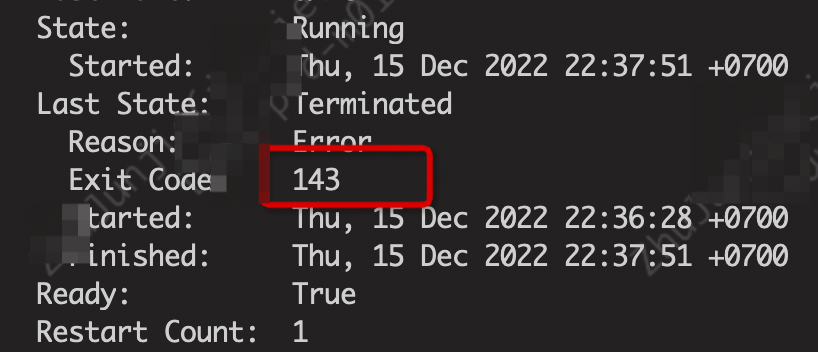> 【探针配置参数调整】在系统负载过高的时候以及针对于对于响应速度和吞吐不同场景的服务需要分别去处理和考虑对应的参数,而不能同日而语!这就是我们常规的探针配置,主要关注的就是:timeout(超时时间)、间隔、失败阈值。三者贯穿的概念就是在**间隔**N秒情况下,当**超时**/失败的次数...
 特惠活动
特惠活动
 没有被列入HSTS预加载的情况下?-优选内容
没有被列入HSTS预加载的情况下?-优选内容
 没有被列入HSTS预加载的情况下?-相关内容
没有被列入HSTS预加载的情况下?-相关内容
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
如下图所示。> 【探针配置参数调整】在系统负载过高的时候以及针对于对于响应速度和吞吐不同场景的服务需要分别去处理和考虑对应的参数,而不能同日而语!这就是我们常规的探针配置,主要关注的就是:timeout(超时时间)、间隔、失败阈值。三者贯穿的概念就是在**间隔**N秒情况下,当**超时**/失败的次数...
干货|以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路
数据加载、SQL 工作表、计算组、查询历史和角色管理等几大模块。分别具有如下作用: * 数据库表管理:用于创建和管理数据库、数据表以及视图等数据对象* 数据加载:用于从不同的离线和实时数据源如对象存储、Kafka 等地写入数据* SQL 工作表:在界面上编辑、管理并运行 SQL 查询* 计算组:创建和管理虚拟的计算资源,用于执行数据查询等操作* 查询历史:用于查看 SQL 的历史执行记录、状态和查询详情等 test_data = pd.read_csv('test.csv')# 实例化 tokenizer 和模型tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')model = BertForSequen...
字节跳动云原生 Spark History 服务的实现与优化
绝大多数情况下我们只关心任务的最终状态,而无需关心引起状态变化的具体 event。因此,我们可以只将 KVStore 持久化下来,而不需要存储大量冗余的 event 信息。此外,KVStore原生支持了 Kryo 序列化,性能明显于 Js... 直接去读取 UIMetaFile 解析。这使得 UIService 无需预加载所有文件元信息,不需要随着任务数量增加提高服务器配置,方便了水平扩展。**优化**1. **避免重复写** 由于每个 stage 完成都会触发写 UIMeta 文...
干货|ClickHouse进阶:性能提升20倍!深度解析Projection优化实践
预聚合是OLAP系统中常用的一种优化手段,在通过在加载数据时就进行部分聚合计算,生成聚合后的中间表或视图,从而在查询时直接使用这些预先计算好的聚合结果,提高查询性能。 实现这种预聚合方法大多都使用... 混合读取不同projection的数据。* ### **2.原始表Schema更新**当对原始表添加新字段(维度或指标 ),对应projection 不包含这些字段,这时候为了利用projection一般情况下需要删除projection重新做物化...
揭秘|UIService:字节跳动云原生 Spark History 服务
绝大多数情况下我们只关心任务的最终状态,而无需关心引起状态变化的具体 event。因此,我们可以只将 `KVStore` 持久化下来,而不需要存储大量冗余的 event 信息。此外,`KVStore`原生支持了 Kryo 序列化,性能明显于 J... 直接去读取 UIMetaFile 解析。这使得 UIService 无需预加载所有文件元信息,不需要随着任务数量增加提高服务器配置,方便了水平扩展。 ## 2.3 **优化**### **2.3.1 避免重复写**由于每个 stage 完成都会触发写...
LAS Spark+云原生:数据分析全新解决方案
Operator 模式的概念允许在不修改 Kubernetes 核心代码的情况下,通过为自定义资源关联控制器来扩展集群的功能。Operator 充当了 Kubernetes API 的客户端,同时也是自定义资源的控制器。部署 Operator 的常见方法... 直接去读取 UIMetaFile 解析。这使得 UIService 无需预加载所有文件元信息,不需要随着任务数量增加提高服务器配置,方便了水平扩展。通过构建 UIService,我们极大的节省了 Spark UI 相关 event 的存储空间,并有效...
揭秘字节跳动云原生 Spark History 服务 UIService
绝大多数情况下我们只关心任务的最终状态,而无需关心引起状态变化的具体 event。因此,我们可以只将 KVStore 持久化下来,而不需要存储大量冗余的 event 信息。此外,KVStore 原生支持了 Kryo 序列化,性能明显于 Json... 2. 去掉了`FsHistoryProvider`的路径扫描逻辑;每次 UI 访问,根据 appid 和路径规则,直接去读取 UIMetaFile 解析。这使得 UIService 无需预加载所有文件元信息,不需要随着任务数量增加提高服务器配置,方便了水平扩...
