kafkaubuntu安装配置
 社区干货
社区干货
Kafka 消息传递详细研究及代码实现|社区征文
Kafka Documentation 中 *[Producer Configs](https://kafka.apache.org/documentation/#producerconfigs)* 里有相关配置说明:[**compression.type**](url)生产者生成的数据的压缩类型。通过使用压缩,可以节省网络带宽和Kafka存储成本。type: stringdefault: nonevalid values: [none, gzip, snappy, lz4, zstd]importance: high [**retries**](url)生产者发送消息失败或出现潜在暂时性错误时,会进行的重试次...
聊聊 Kafka:Topic 创建流程与源码分析 | 社区征文
## 一、Topic 介绍Topic(主题)类似于文件系统中的文件夹,事件就是该文件夹中的文件。Kafka 中的主题总是多生产者和多订阅者:一个主题可以有零个、一个或多个向其写入事件的生产者,以及零个、一个或多个订阅这些事件的消费者。可以根据需要随时读取主题中的事件——与传统消息传递系统不同,事件在消费后不会被删除。相反,您可以通过每个主题的配置设置来定义 Kafka 应该保留您的事件多长时间,之后旧事件将被丢弃。Kafka 的性能在...
Kafka@记一次修复Kafka分区所在broker宕机故障引发当前分区不可用思考过程 | 社区征文
包括不限于改Kafka,主题创建删除,Zookeeper配置信息重启服务等等,于是我们来一起看看... Ok,Now,我们还是先来一步步分析它并解决它,依然以”化解“的方式进行,我们先来看看业务进程中线程报错信息:```jsor... 怀疑是Kafka某个节点有问题-失联-假死?## 思考过程从这个表象来看,某台机器有过宕机事件,宕机原因因环境而异,但Kafka的高可用性HA我们是耳熟能详的,为啥我们搭建的Kafka集群由多个节点组成,但其中某个节点宕掉...
Kafka数据同步
用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。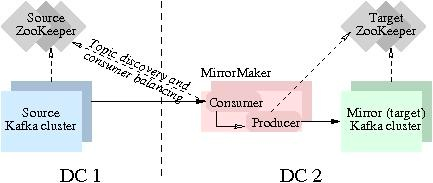本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的Source Kafka版本为2.12,基于本地机器搭建。现实生产环境会更加复杂,如果您有迁移类的需求,欢迎咨询[技术支持服务](https://console.volcengine.com...
 特惠活动
特惠活动
 kafkaubuntu安装配置-优选内容
kafkaubuntu安装配置-优选内容
 kafkaubuntu安装配置-相关内容
kafkaubuntu安装配置-相关内容
使用Logstash消费Kafka中的数据并写入到云搜索
Kafka 中的数据,并写入到云搜索服务中。 关于实验 预计部署时间:20分钟级别:初级相关产品:消息队列 - Kafka & 云搜索受众: 通用 环境说明 如果还没有火山引擎账号,点击此链接注册账号 如果您还没有VPC,请先点击链接创建VPC 消息队列 - Kafka 云搜索 云服务器ECS:Centos 7 在 ECS 主机上准备 Kafka 客户端的运行环境,提前安装好Java运行环境 在 ECS 主机上安装 Logstash 实验步骤 步骤一:准备 Logstash 配置文件Logstash 配...
使用 Kafka 协议上传日志
日志服务支持通过 Kafka 协议上传和消费日志数据,基于 Kafka 数据管道提供完整的数据上下行服务。使用 Kafka 协议上传日志功能,无需手动开启功能,无需在数据源侧安装数据采集工具,基于简单的配置即可实现 Kafka Pr... 设置索引的详细说明请参考配置索引。 示例 通过 Logstash 上传日志Logstash 内置 Kafka 输出插件(logstash_output_kafka),可以通过 Kafka 协议采集数据。在通过 ELK 搭建日志采集分析系统的场景下,只需修改 Logs...
Kafka@记一次修复Kafka分区所在broker宕机故障引发当前分区不可用思考过程 | 社区征文
包括不限于改Kafka,主题创建删除,Zookeeper配置信息重启服务等等,于是我们来一起看看... Ok,Now,我们还是先来一步步分析它并解决它,依然以”化解“的方式进行,我们先来看看业务进程中线程报错信息:```jsor... 怀疑是Kafka某个节点有问题-失联-假死?## 思考过程从这个表象来看,某台机器有过宕机事件,宕机原因因环境而异,但Kafka的高可用性HA我们是耳熟能详的,为啥我们搭建的Kafka集群由多个节点组成,但其中某个节点宕掉...
通过 Kafka 消费火山引擎 Proto 格式的订阅数据
Python 通过示例代码中参数 api_version 指定服务端 Kafka 版本号。 Java 通过 maven pom.xml 文件中参数 version 指定服务端 Kafka 版本号。 按需安装运行语言环境。 运行语言 说明 Go 安装 Go,需使用 Go 1.13 ... Python 安装 Python,需使用 Python 2.7 或以上版本。您可以执行 python --version 查看 Python 的版本。 依次执行以下命令,安装 pip 依赖。 python pip install kafka-pythonpython pip install protobufpython...
Kafka 迁移上云(方案二)
1.1 迁移评估根据现有业务量和消息量估算所需的消息队列 Kafka版资源,例如业务读写流量峰值、磁盘容量和分区数等。不同规格的 Kafka 实例代表不同的计算能力及存储空间,请根据业务量合理评估资源需求。 1.2 准备相关资源确认资源需求之后,还需要准备相关资源,例如私有网络和子网、ECS云服务器和 Kafka 实例。 搭建环境。您需要创建私有网络和子网、购买 ECS 云服务器。迁移后您的服务需要和 Kafka 实例处于相同的区域(Region)和...
Kafka 迁移上云(方案一)
不同规格的 Kafka 实例代表不同的计算能力及存储空间,请根据业务量合理评估资源需求。 1.2 准备相关资源确认资源需求之后,还需要准备相关资源,例如私有网络和子网、ECS 云服务器和 Kafka 实例。 搭建环境。您需要创... 详细操作步骤请参考 创建 Kafka 实例 。 2 迁移元数据迁移元数据的步骤主要是在新的 Kafka 实例中创建与原 Kafka 集群相同的 Topic 和 Group 配置,包括 Topic 名称、分区数、副本数、消息保留时长等参数配置等...
Kafka
1. 概述 Kafka Topic 数据能够支持产品实时数据分析场景,本篇将介绍如何进行 Kafka 数据模型配置。 温馨提示:Kafka 数据源仅支持私有化部署模式使用,如您使用的SaaS版本,若想要使用 Kafka 数据源,可与贵公司的客户成功经理沟通,提出需求。 2. 快速入门 下面介绍两种方式创建数据连接。 2.1 从数据连接新建(1)在数据准备模块中选择数据连接,点击新建数据连接。(2)点击 Kafka 进行连接。(3)填写连接的基本信息,点击测试连接,显示连...
使用默认接入点连接实例
本文介绍在 VPC 网络环境下通过默认接入点连接 Kafka 实例,进行消息生产和消息消费的操作步骤。 背景信息消息队列 Kafka版提供 PLAINTEXT 协议的普通访问方式,即默认接入点。在 VPC 网络环境下通过默认接入点连接实例时,无需配置用户名及密码,直接访问即可。 前提条件已获取默认接入点信息,包括连接地址和端口号。详细信息请参考查看接入点。 已创建 Topic。操作步骤请参考创建 Topic。 已购买火山引擎 ECS,并成功安装 JDK、配置...
通过 Kafka 消费 Canal Proto 格式的订阅数据
Python 通过示例代码中参数 api_version 指定服务端 Kafka 版本号。 Java 通过 maven pom.xml 文件中参数 version 指定服务端 Kafka 版本号。 按需安装运行语言环境。 运行语言 说明 Go 安装 Go,需使用 Go 1.13 ... Python 安装 Python,需使用 Python 2.7 或以上版本。您可以执行 python --version 查看 Python 的版本。 依次执行以下命令,安装 pip 依赖。python pip install kafka-pythonpython pip install protobufpython p...
