mysql取出大表某一列所有值
 社区干货
社区干货
分布式数据库TiDB的设计和架构
MySQL、SQLServer、NoSQL、NewSQL等,那么目前数据库圈最火的分布式关系型数据库之一TiDB你了解吗?相信很多同学以前听说过TiDB,也知道是一款国人研发的数据库,但你知道TiDB到底是如何实现的?它跟其他数据库产品相比,它的核心优势是什么?此次夜校分享,xiaoyu向大家介绍了数据库发展史、TiDB 设计、架构及生态及TiDB在得物的应用。# 数据库技术发展演进**2008年以前**2008 年以前应用最为广泛的是单机关系型数据库(SQL),能很...
[数据库论文研读] HTAP行列混存 & 智能转换
OLAP应用则一般为列存因为OLTP和OLAP的差异,现有的数据分析系统(或者说数据分析的pipeline)一般是部署两套独立的系统。OLTP系统用于执行事务,要求低时延 & 高吞吐,而OLAP系统用来执行历史数据分析(查询),最终出报... 俗称列存,就是将表里面的一列(一个字段)的数据存到一起,一个文件里存的都是同一列的,有N列就存成N个文件。DSM对read-only的workload比较友好,无论是读一列还是读多列,因为读一列就是读一整个文件,但是对write-on...
揭秘|字节跳动基于Hudi的实时数据湖平台
除了提供 Hudi 社区的所有功能外,还支持基于数据湖的元数据管理系统、行列级别的并发更新、Bucket Index和Append模式等特性。## 字节跳动实时数据湖平台应用场景### 01-典型 Hudi Pipeline 场景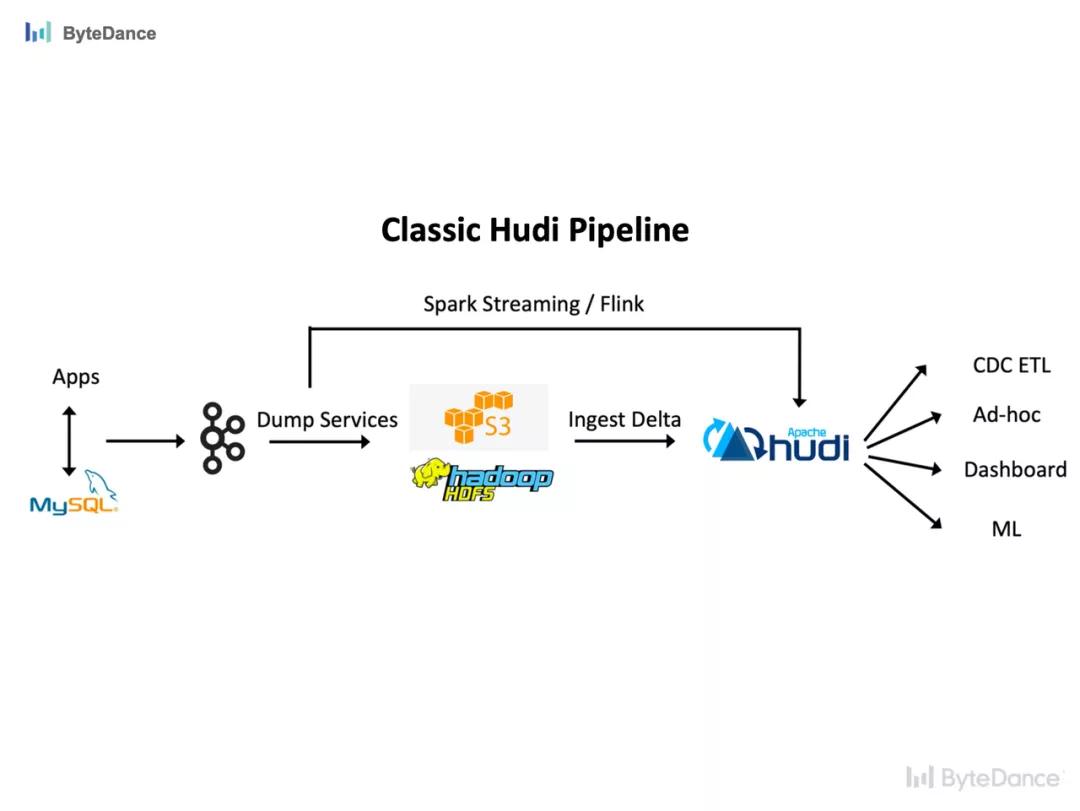一个典型的 pipeline 是,MySQL 侧的 binlog 生产到 Kafka:- **实时场景**直接通过 Spark Str...
揭秘|字节跳动基于Hudi的实时数据湖平台
除了提供 Hudi 社区的所有功能外,还支持基于数据湖的元数据管理系统、行列级别的并发更新、Bucket Index和Append模式等特性。 LAS**字节跳动实时数据湖平台应用场景** ... MySQL 侧的 binlog 生产到 Kafka:* **实时场景** 直接通过 Spark Streaming 或 Flink 消费这部分更新数据,写入数据湖,供下游业务使用。* **批量场景**会先将 binlog 通过 dump service 存储到 HDFS上,再按照...
 特惠活动
特惠活动
 mysql取出大表某一列所有值-优选内容
mysql取出大表某一列所有值-优选内容
 mysql取出大表某一列所有值-相关内容
mysql取出大表某一列所有值-相关内容
表管理
因此建议您不要在数据库工作台 DBW 做大表的结构或索引调整。 当列存在索引或外键设置时,无法对列进行修改。如需调整,请先删除索引或外键。 如需修改外键信息,请先修改外键名称。 重命名表 不支持在系统库上重... 创建表登录云数据库 MySQL 版数据交互台。 在数据交互台页面的可视化操作区域,将鼠标指向表后,选择 ... < 创建表。 在创建表@{数据库名称} 页签中,配置以下参数信息。 配置基本信息,如下表所示。 参数 说明 表...
表管理
因此建议您不要在数据库工作台 DBW 做大表的结构或索引调整。 当列存在索引或外键设置时,无法对列进行修改。如需调整,请先删除索引或外键。 如需修改外键信息,请先修改外键名称。 重命名表 不支持在系统库上重... 创建表登录云数据库 veDB MySQL 版数据交互台。 在数据交互台页面的可视化操作区域,将鼠标指向表后,选择 ... < 创建表。 在创建表@{数据库名称} 页签中,配置以下参数信息。 配置基本信息,如下表所示。 参数 说...
分布式数据库TiDB的设计和架构
MySQL、SQLServer、NoSQL、NewSQL等,那么目前数据库圈最火的分布式关系型数据库之一TiDB你了解吗?相信很多同学以前听说过TiDB,也知道是一款国人研发的数据库,但你知道TiDB到底是如何实现的?它跟其他数据库产品相比,它的核心优势是什么?此次夜校分享,xiaoyu向大家介绍了数据库发展史、TiDB 设计、架构及生态及TiDB在得物的应用。# 数据库技术发展演进**2008年以前**2008 年以前应用最为广泛的是单机关系型数据库(SQL),能很...
表管理
因此建议您不要在数据库工作台 DBW 做大表的结构或索引调整。 当列存在索引或外键设置时,无法对列进行修改。如需调整,请先删除索引或外键,再添加索引或外键。 删除表 表被删除后无法恢复。同时,在删除表的过程中... 设置默认值。 精度 (可选)设置精度。 小数点 (可选)设置列的小数点位置。 校验规则 (可选)从下拉列表中选择列的校验规则。 备注 (可选)填写列的备注信息。备注信息建议与您的业务相关。 说明 当需要删除某一列时,您...
一致性级别
例如对大表执行 DDL(如加字段)操作或大批量插入数据的时候,数据同步延迟会非常高,从而导致无法从只读节点中读取到最新数据。读写分离代理功能无法解决由于延迟导致的查询不一致问题。 读写节点有数据写入后,相关的更新会同步到只读节点,其中数据同步的延迟时间与写入压力有关。云数据库 veDB MySQL 版通过提供不同的一致性级别,来保证业务访问数据库的数据一致性要求。 说明 一致性级别从最终一致性的调整到会话一致性或全局一致...
DataWind 产品使用问题排查方法
倒推获取授权一般就可解决;另一种权限问题是: 有时会在可视化查询的界面看到某些图表里存在灰色胶囊字段,这种是因为图表中使用了他人在数据集上保存为个人数据集字段。 针对权限问题,可见权限体系操作手册 2. 数据... 出现极端的小表套大表的逻辑模型,导致笛卡尔积呈几何倍数增长,从而引起数据膨胀检测触发了阈值而系统中止; 小表套大表即:左表和右表根据连接字段关系,数据呈现1:N的映射关系,且N>=50;如常见的 Prudoct Type join S...
[数据库论文研读] HTAP行列混存 & 智能转换
OLAP应用则一般为列存因为OLTP和OLAP的差异,现有的数据分析系统(或者说数据分析的pipeline)一般是部署两套独立的系统。OLTP系统用于执行事务,要求低时延 & 高吞吐,而OLAP系统用来执行历史数据分析(查询),最终出报... 俗称列存,就是将表里面的一列(一个字段)的数据存到一起,一个文件里存的都是同一列的,有N列就存成N个文件。DSM对read-only的workload比较友好,无论是读一列还是读多列,因为读一列就是读一整个文件,但是对write-on...
揭秘|字节跳动基于Hudi的实时数据湖平台
除了提供 Hudi 社区的所有功能外,还支持基于数据湖的元数据管理系统、行列级别的并发更新、Bucket Index和Append模式等特性。## 字节跳动实时数据湖平台应用场景### 01-典型 Hudi Pipeline 场景一个典型的 pipeline 是,MySQL 侧的 binlog 生产到 Kafka:- **实时场景**直接通过 Spark Str...
揭秘|字节跳动基于Hudi的实时数据湖平台
除了提供 Hudi 社区的所有功能外,还支持基于数据湖的元数据管理系统、行列级别的并发更新、Bucket Index和Append模式等特性。 LAS**字节跳动实时数据湖平台应用场景** ... MySQL 侧的 binlog 生产到 Kafka:* **实时场景** 直接通过 Spark Streaming 或 Flink 消费这部分更新数据,写入数据湖,供下游业务使用。* **批量场景**会先将 binlog 通过 dump service 存储到 HDFS上,再按照...
