冗余分布式NFS文件系统和复制因子> 1。对于Kafka部署是否安全?
 社区干货
社区干货
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.03
Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100%开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。## **产... 用户可以查看历史集群的作业执行日志和记录。 - 支持 EMR Flume 读写对象存储 TOS、大数据文件系统 CFS。 - 产品总览页面交互和展示信息优化,对集群类型、欠费提醒进行优化。 - 上线华东上海 Re...
火山引擎上云迁移指南(二):迁移实施
云堡垒机和云安全中心。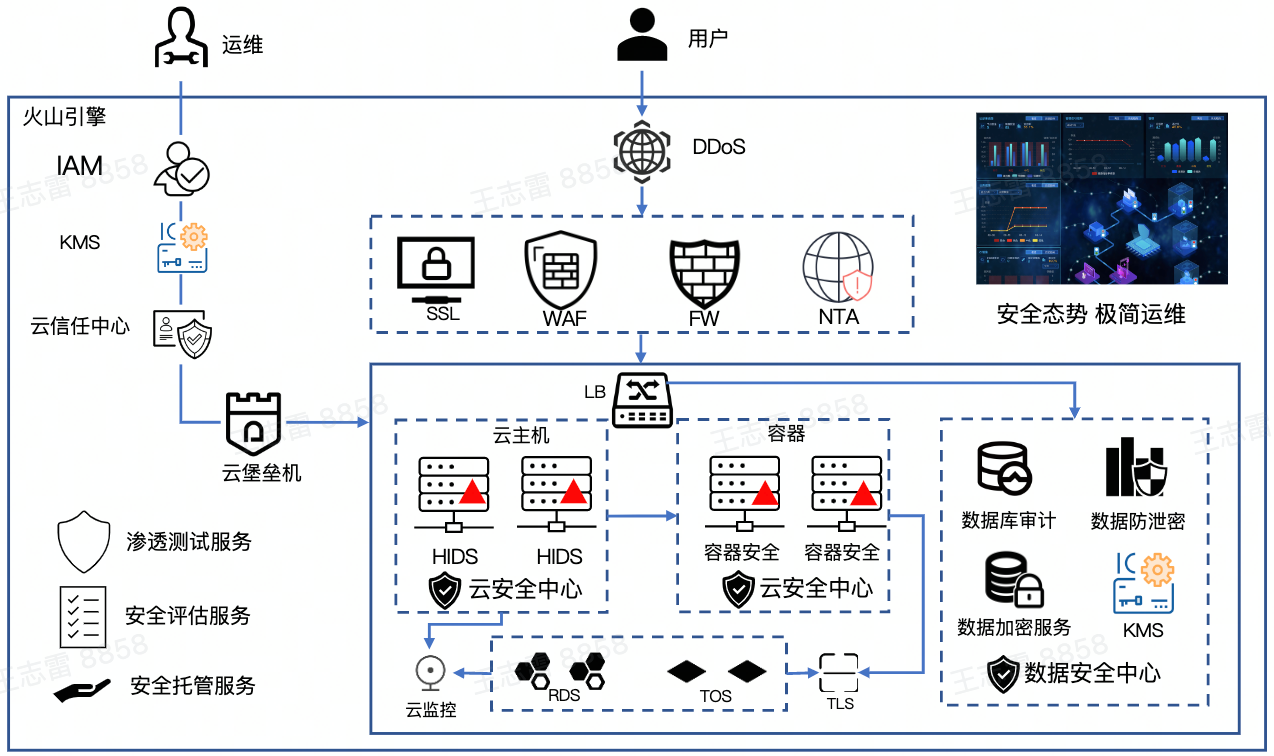## 应用迁移客户业务应用通常部署物理机、虚拟机和容器上,应用的上... 而是只传输两个文件的不同部分。- **源端支持场景** - Linux本地文件系统 - NFS文件 - 第三方云NAS- **迁移流程**  特惠活动
特惠活动
 冗余分布式NFS文件系统和复制因子> 1。对于Kafka部署是否安全?-优选内容
冗余分布式NFS文件系统和复制因子> 1。对于Kafka部署是否安全?-优选内容
 冗余分布式NFS文件系统和复制因子> 1。对于Kafka部署是否安全?-相关内容
冗余分布式NFS文件系统和复制因子> 1。对于Kafka部署是否安全?-相关内容
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计...
「火山引擎」数据中台产品双月刊 VOL.05
分布式数据自治- 底座组件升级至V1.9,支持语言切换全英文版本**【公有云-功能迭代更新】**- 数据开发:支持临时查询功能,新增 EMR Doris SQL 查询类型,EMR MapReduce 任务类型,基于 EMR 引擎提供 MapReduc... 新增软件栈 3.2.1:Doris升级至1.2.1;Kafka升级至2.8.1;Hudi升级至0.12.2;Flink升级至1.16.0,引入StarRocks、Doris、HBase和ByteHouse Connector,支持MySQL Sink,优化多个配置,达到开箱即用;支持avro,csv,debez...
2022 年每个开发者必知的云原生趋势 | 社区征文
云原生和在云上跑的传统应用不同。一些传统应用是基于SOA(Service-Oriented Architecture,面向服务架构)架构来搭建的,然后再被放到云上。这些传统应用没有充分运用到云的优势。因为云作为一种分布式架构,它的原住... 一份基准代码可以多份部署,可通过版本控制进行追踪。**反例**:多个无关项目、数百万行代码全部放到一个仓库;对于差异需求,直接复制项目仓库单独开发,同时维护多个仓库代码。2. Dependencies-显示和隔离的**依赖...
基于 ByteHouse 构建实时数仓实践
实时数据分析和 Ad-hoc 数据分析等各种应用场景。 ### ByteHouse 优势一:实时数据高吞吐的接入能力面对业务大数据量的产生,需要高效可靠实时数据的接入能力,为此我们自研了 Kafka 数据源接入表引擎 HaKafk... 1. 支持基于 RBO 优化能力,即支持:列裁剪、分区裁剪、表达式简化、子查询解关联、谓词下推、冗余算子消除、Outer-JOIN 转 INNER-JOIN、算子下推存储、分布式算子拆分等常见的启发式优化能力;1. 支持基于 CBO 优...
干货|解析云原生数仓ByteHouse如何构建高性能向量检索技术
对于向量检索性能通常要求比较高。其次,向量检索通常需要与属性过滤等操作结合计算。最后,向量检索通常会与其他属性结合查询,比如以图搜图等场景,最终需要的,是相似的图片路径或文件。 构建向量数据库时,一... 比如基于 Kafka 的实时导入,Insert sql,python sdk等。 基本查询是一个定式:select 需要的列信息,增加一个 order by + limit 的指令。查询支持与标量信息结合的混合查询,以及针对 distance 的 range 查询。...
火山引擎云存储选型指南 x 自动驾驶场景最佳实践
如果您有计划将业务应用部署或迁移到火山引擎,可以参考文章内容选择最合适的云存储产品或者产品组合,为上层业务打造坚实的、高性价比的存储平台。# 云存储产品选型方法论## 存储选型考量在选型之前,我们应该... 面向大数据生态场景的分布式文件系统,底层多基于对象存储构建 | 适合存放任意类型的非结构化数据,具有海量、安全、低成本、高可靠特性的分布式存储 || 接口协议 | 虚拟块设备协议 | NFS v3/v4、SMB | POSIX | HDF...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.05
分布式数据自治- 底座组件升级至V1.9,支持语言切换全英文版本 **【公有云-功能迭代更新】** - 数据开发:支持临时查询功能,新增 EMR Doris SQL 查询类型,EMR MapReduce 任务类型,基于 EMR 引擎提供 ... 新增软件栈 3.2.1:Doris升级至1.2.1;Kafka升级至2.8.1;Hudi升级至0.12.2;Flink升级至1.16.0,引入StarRocks、Doris、HBase和ByteHouse Connector,支持MySQL Sink,优化多个配置,达到开箱即用;支持avro,csv,debez...
干货 | 实时数据湖在字节跳动的实践
Hudi社区的解决方案是使用一个分布式存储来管理这个 Timeline 。Timeline 里面记录了每次操作的元数据,也记录了一些表的 schema 和分区的信息,通过同步到Hive Metastore来做元数据的展示。这个过程中我们发现了三个... 我们的思路是提供更灵活的冲突检查和数据合并策略。最基础的就是行级并发,** 首先两个独立的 writer 写入的数据在物理上就是隔离的,借助文件系统的租约机制也能够保证对于一个文件同时只有一个 writer。所以这个冲...
