数据智能体
数据智能体






- 文档首页
 数据智能体智能营销 Agent非结构化数据打标创建并配置非结构化数据打标任务配置处理结果输出
数据智能体智能营销 Agent非结构化数据打标创建并配置非结构化数据打标任务配置处理结果输出

数据输出是指您在创建可视化建模任务的过程中的数据输出与保存的环节。当前支持将打标结果输出为VeCDP的数据集或VeCDP的标签。 输出为数据集是指在完成数据输入-数据处理之后,需要对任务结果以数据集的形式保存,以便后续进行可视化查询与展现等;输出为标签是指将数据输出到标签体系,并允许用户自定义数据处理流程,最终将处理结果集成至标签系统中。本文为您介绍如何配置处理的结果输出。
若提取结果用于分析,可以将数据输出到数据集,支持输出到Hive/ByteHouse。
在可视化建模的编辑界面,点击算子的添加按钮,在输出类型中,点击选择输出-输出数据集。
在输出数据集的配置页面配置相关参数。
参数
说明
名称/描述
自定义名称及描述。
开放项目
配置将数据集开放给其他项目,则数据集管理员可在其他项目的可视化建模任务中将其作为数据源使用。
CDP应用
支持CDP应用打标,在输出数据集的同时定义数据集的应用场景,基于不同场景可以自动匹配不同的存储逻辑,自动约束格式,避免重复抽取数据。
注:由于CDP下游部分应用存在特殊查询逻辑,请根据需要选择合适的应用场景。- 普通数据集: 不做特殊限定,可作为数据源在可视化建模内重复参与生产加工,但是无法注册数据档案或配置IDM。
- IDMapping图谱配置: 用于配置IDMapping图谱,仅支持输出Hive数据集,且一般要求每天分区存储全量数据。
- 数据档案-业务明细/行为事件档案: 用于注册明细/行为数据档案,该类数据集需必填主体基准OneID字段,且系统会自动将OneID字段作为分片键存储且不可变更,可提前在画布流程中添加IDM算子转换生成基准ID(OneID)字段,一般要求每天分区存储增量数据。
- 数据档案-主体属性档案: 用于注册主体属性的数据档案,该类数据集需必填主体基准OneID字段,且系统会自动根据OneID字段进行去重,保证属性值唯一,可提前在画布流程中添加IDM算子转换生成基准ID(OneID)字段,一般要求每天存储全量数据。
- 数据档案-业务维度档案: 用于注册业务维度数据档案,该类数据集需必填维度主键字段,且系统会将每个分片节点(服务器)存储全量数据并对主键字段进行去重,不可直接用于CDP其他任何模块,一般要求每天分区存储全量数据。
- 数据档案-会话档案: 用于注册会话档案,该类数据集需必填会话id字段,一般是增量分区表。
类型
可选择ByteHouse或者Hive。
- Hive:需要数据生命周期(必选) 与 分区(可选)。
- ByteHouse:需要选择集群、排序键、抽样字段、表类型、数据生命周期和分区。
数据生命周期
抽取至系统存储中数据的有效保留天数,非分区表根据数据更新时间保留数据,日期分区则根据分区日期保留数据,生命周期外的数据每天0点会自动清除,默认值为7天。
分区
可选日期或其他取值可枚举的字段作为分区,一级分区必须为date类型,若无合适字段,可以选择“系统默认分区”(对天、周、 月级别例行同步任务的取值为任务例行执行的前一天,对小时、分钟级别例行同步任务取值为任务例行执行当天, 对手动运行的任务的取值为运行时选择的业务时间),二级分区可选小时或其他取值可枚举的字段作为分区(必须在高级设置打开动态分区)。
集群
选择数据集存储的集群。
排序键
将最常用作过滤条件的字段设置为排序键,可以使查询会更快。可以设置多个字段为排序键,第1个字段作用最大,其余依次递减,建议不超过3个。不能使用分区字段作为排序键。
抽样字段
在可视化查询模块中可按此字段抽样进行查询,只支持int,float,string类型的字段。
表类型
可选择普通表或者分桶表。普通表是常规的数据存储形式,结构相对简单直接。而分桶表是将数据按照特定规则分到不同的桶中,以提高查询性能等。
依赖配置:数据源依赖通过依赖配置,可结合上游数据的就绪状态,判断并开启定时同步任务。在依赖配置中,对于Hive和Bytehouse数据源,系统可自动获取上游配置的依赖信息,进行展示。如需修改或自定义配置依赖关系,可选择自定义配置。具体操作,请参见输出到数据集。
支持对常见数据源(Hive JDBC、Maxcompute)进行检测依赖。填写依赖表、分区信息及依赖类型。可以根据当前任务逻辑中数据表的情况选择合理的依赖方式,系统默认依次推荐【任务依赖 > 系统自定义依赖 > 数据源分区检测依赖】:- 任务依赖:根据产出数据表的可视化建模或数据集任务状态建立依赖关系。
- 数据源分区检测依赖:根据数据源的分区数据产出情况建立依赖关系。
- 系统自定义依赖:通过系统管理员创建依赖API的方式来建立依赖,通常用于同三方数据平台相关任务建立依赖,API的逻辑由系统管理员定义,详情可咨询系统管理员。
注意
对于非分区表,系统暂时无法推荐出依赖系统自定义依赖和数据源分区探测依赖。
高级配置。
HIVE数据源的数据集需选择运行队列和队列中的运行优先级。选择队列,对应的HIVE查询将在指定队列上执行后再导入数据集。队列选择会影响数据集同步时长,但不影响可视化查询效果。
运行参数: 支持根据需求设置数据集同步的运行参数,以保障同步成功或同步性能等。
若提取结果需用于圈群,可以输出为标签。将数据输出到标签体系,并允许用户自定义数据处理流程,最终将处理结果集成至标签系统中。
在可视化建模的编辑界面,点击算子的添加按钮,在输出类型中,点击选择输出-输出标签。
在输出标签的配置页面配置相关参数。
参数
参数说明
主体
选择VeCDP中配置的主体,即ID-Mapping OneID的目标对象
源ID类型
主体在ID-Mapping图谱中的某一类ID的ID Code
对应字段
选择数据源中对应ID-Mapping源ID类型的字段作为数据输入
标签配置
标签提交后会在标签体系自动构建相关标签,保存任务后真正生效
标签字段
选择需要定义为标签的字段名,暂不支持Map等特殊类型字段
标签名称
定义标签可被理解的名称,中文名或英文名
标签描述
定义标签可被理解的描述信息
在线服务
打开后,标签可在高速OpenAPI内查询相关数据,实现高并发查询
高级配置
合理的运行参数配置可辅助提高任务运行效率,仅在前置节点存在「数据清洗」算子或输出数据集配置「CDP基准ID字段」时高级参数有效。
依赖配置。
数据源依赖通过依赖配置,可结合上游数据的就绪状态,判断并开启定时同步任务。在依赖配置中,对于Hive和Bytehouse数据源,系统可自动获取上游配置的依赖信息,进行展示。如需修改或自定义配置依赖关系,可选择自定义配置。具体操作,请参见输出标签。
高级配置。
HIVE数据源的数据集需选择运行队列和队列中的运行优先级。选择队列,对应的HIVE查询将在指定队列上执行后再导入数据集。队列选择会影响数据集同步时长,但不影响可视化查询效果。合理的运行参数配置可辅助提高任务运行效率,仅在前置节点存在「数据清洗」算子或输出数据集配置「CDP基准ID字段」时高级参数有效。
将打标结果,输出到外部存储。通过可视化建模将加工好的数据输出至系统之外的数据存储中,从而实现数据资产的输出能力构建。更多信息请参见外部输出。
说明
是否允许输出,可咨询数据连接的所有者,如系统支持输出,可在联系火山引擎技术人员打开开关。
目前支持的外部存储:
数据源 | 支持版本 | 环境 |
|---|---|---|
MaxCompute | 1.20.2 | 私部&SaaS |
OceanBase Oracle / Mysql | 1.20.2 | 私部 |
Oracle | 1.20.2 | 私部 |
BytehouseCE | 1.22.2 | 私部&SaaS |
MySQL | 1.20.2 | 私部 |
- 在可视化建模的编辑界面,点击算子的添加按钮,在输出类型中,点击选择外部输出。
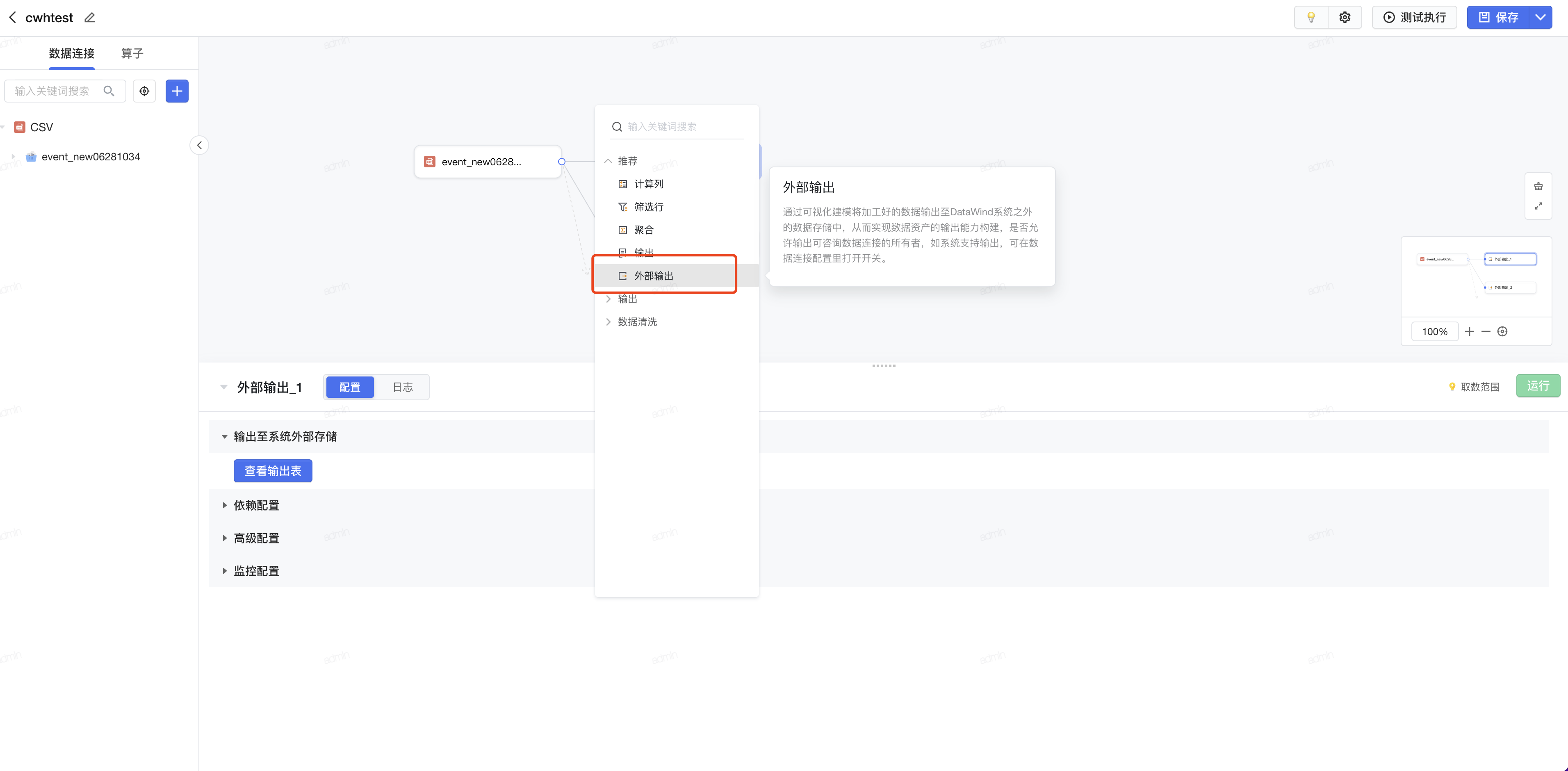
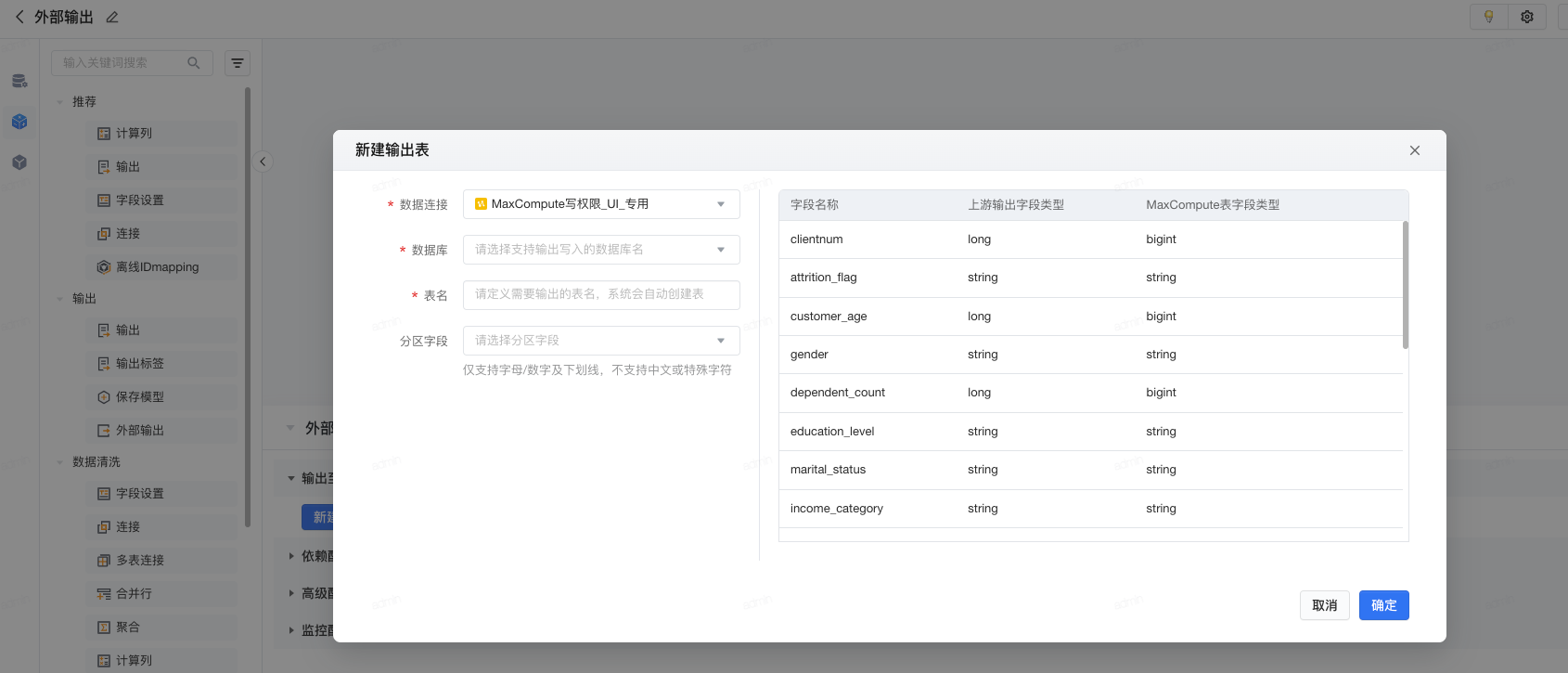
- 选择创建好的数据连接,并填写库表信息即可。
- 可视化建模任务配置完成后,点击测试执行,在测试执行结果栏中查看输出结果并进行调优。
- 任务调试完成后,保存任务配置,点击左上角返回可跳转到任务详情。返回可视化建模页面,点击当前任务的运行,可以手动运行。
将上述可视化建模输出的任务进行数据集导出或者标签输出,用于BI看板分析。对于解析的标签和数据集结果进行业务逻辑验证,保证符合目标预期,如果有问题,可返回大模型应用设计步骤进行提示词优化等操作。