hbase连接初始化慢
 社区干货
社区干货
干货 | 看 SparkSQL 如何支撑企业级数仓
MapReduce 和 HBase,形成了早期 Hadoop 的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似 SQL 语法的分析入口,同时在编程态的支撑也不够友好,只有 Map 和 Reduce ... 开源或商业 BI 工具都支持通过标准 JDBC 的方式连接 Hive,可以支持数据探索的动作,极大的丰富了大数据生态圈下的组件多样性,同时也降低了使用门槛,可以让熟悉 SQL 的人员低成本迁移。基于这些设计非常好的特效,加...
干货 | ELT in ByteHouse 实践与展望
聚合完成后将结果写入 **HBase** 或MySQL中再去取数据,将数据取出后作展示。 Flink 还会去直接暴露中间状态的接口,即queryable state,让用户更好的使用状态数据。但是最后还会与批计算的结果完成对数,如... 连接复用、状态码传输、压缩等* **算子层*** 批量发送* 线程复用,减少线程数量* 带来的收益* 1. Cooridnator 更稳定、更高效* 聚合等**算子**拆分到 worker 节点执行* Cooridnator 节点只需要...
ELT in ByteHouse 实践与展望
将结果写入HBase或MySQL中再去取数据,将数据取出后作展示。Flink还会去直接暴露中间状态的接口,即queryable state,让用户更好的使用状态数据。但是最后还会与批计算的结果完成对数,如果不一致,需要进行回查操作,整... 复用连接池# adaptive scheduler这是在稳定性方面所做的特性。在OLAP场景中可能会发现部分数据不全或数据查询超时等,原因是每个计算节点是所有的query共用的,这样一旦有一个节点较慢就会导致整个query...
干货|DataLeap数据资产实战:如何实现存储优化?
排除了HBase和Cassandra;==================================================**●**从当前数据量与将来的可扩展性考虑,单机方案不可选,排除了BerkeleyDB;==============================================... 每个租户都会有各自的MySQL连接配置,启动之后会为各个租户分别初始化数据库连接,所有和JanusGraph的请求都会通过Context传递租户信息,以便在操作数据库时选择该租户对应的连接。 **具体代码:****●**...
 特惠活动
特惠活动
 hbase连接初始化慢-优选内容
hbase连接初始化慢-优选内容
 hbase连接初始化慢-相关内容
hbase连接初始化慢-相关内容
ELT in ByteHouse 实践与展望
如果Hadoop 系统中出报表较慢或聚合能力较差,可以去做一个数据的预计算,提前将配的指标的 cube 或一些视图算好。实际 SQL 查询时,可以直接用里面的 cube 或视图做替换,之后直接返回。* **流批一体派**:如Flink、Risingwave。在数据流进时,针对一些需要出报表或者需要做大屏的数据直接内存中做聚合。聚合完成后将结果写入HBase或MySQL中再去取数据,将数据取出后作展示。Flink 还会去直接暴露中间状态的接口,即queryable sta...
DataLeap 数据资产实战:如何实现存储优化?
排除了 HBase 和 Cassandra;- 从当前数据量与将来的可扩展性考虑,单机方案不可选,排除了 BerkeleyDB;- 同样因为人力成本,需要做极大量开发改造的方案暂时不考虑,排除了 Redis。 最终我们挑选了 MySQL ... **具体实现**:每个租户都会有各自的 MySQL 连接配置,启动之后会为各个租户分别初始化数据库连接,所有和 JanusGraph 的请求都会通过 Context 传递租户信息,以便在操作数据库时选择该租户对应的连接。**具体代码**...
ByConity 技术详解之 ELT
如果Hadoop系统中出报表较慢或聚合能力较差,可以去做一个数据的预计算,提前将配的指标的cube或一些视图算好。实际SQL查询时,可以直接用里面的cube或视图做替换,之后直接返回。- **流批一体** **派**:如 Flink、Risingwave。在数据流进时,针对一些需要出报表或者需要做大屏的数据直接内存中做聚合。聚合完成后,将结果写入HBase或MySQL中再去取数据,将数据取出后作展示。Flink还会去直接暴露中间状态的接口,即queryable state,让...
一文读懂火山引擎云数据库产品及选型
宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以 Neo4j 为代表)**。虽然这些类型都属于 NoSQL 数据库范畴,但是不同类型的 NoSQL 数据库所适用的场景各有不... OLTP 与 OLAP 系统之间通常会使用 ETL 进行连接。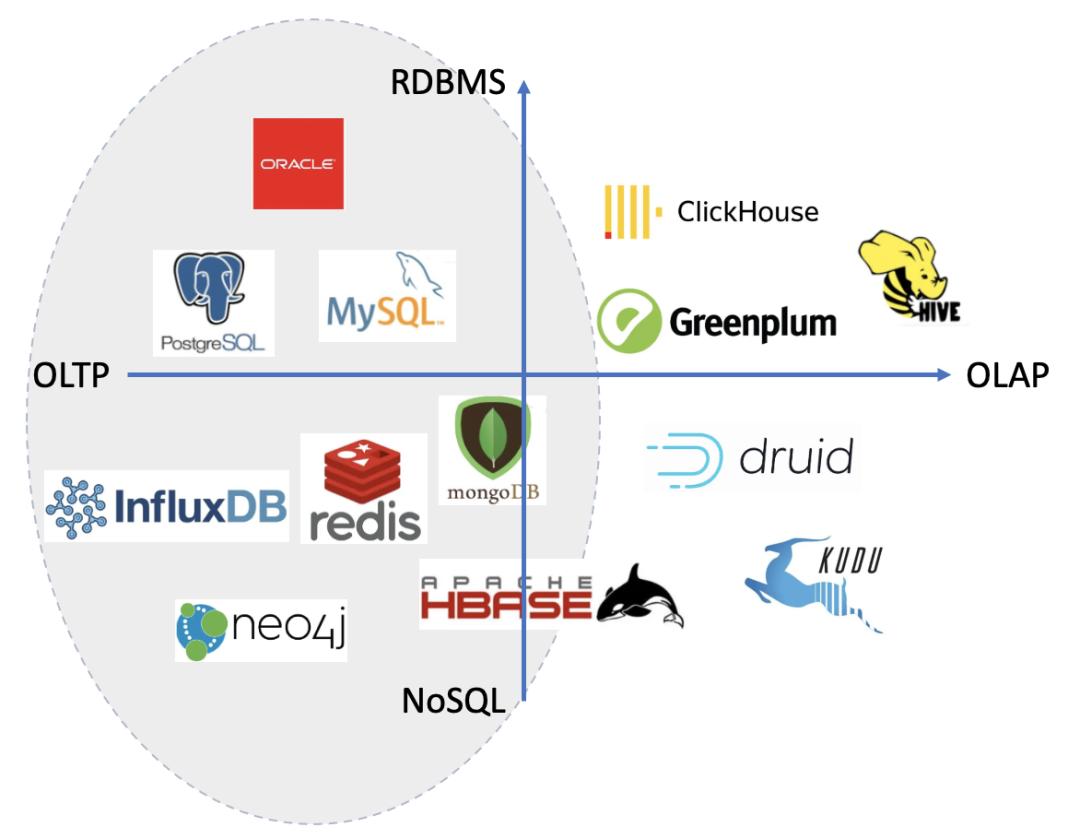**本文主要侧重于 OLTP 系统的...
错误码
计费项不存在 ErrorAccountChargeGenChannelOrder InternalError.GenChannelOrder 创建按路计费订单失败 ErrorAccountCreateAccountFailedPermissionGetErr InternalError.InitPermission 权限初始化失败 ErrorAcc... 创建语音对讲媒体通道错误 ErrorVoiceTalkReleaseMedia InternalError.VoiceTalkReleaseMedia 1:释放语音对讲媒体通道错误 ErrorVoiceTalkAudioSendUrl InternalError.VoiceTalkAudioSendUrl 1:生成语音发送链接错...
创建集群
NoSQL数据库场景: HBase:高可靠性、高性能、面向列、可伸缩的分布式存储系统。 搜索场景: OpenSearch:分布式搜索和分析引擎,解决用户结构化数据探索的需求。 数据科学场景: TensorFlow:端到端开源机器学习平台... 下拉选择需链接的外置数据源。操作详见元数据链接。 高级配置 自定义配置 集群创建前,可以通过json文件定义集群组件的参数配置,将组件的配置导入集群中。输入参数的格式如下:[{"serviceName": "xxx", "fileName...
为什么在数据同步任务中,全量初始化任务长时间内无进展?
可能有以下原因导致任务长时间内无进展: 可能原因一:当待同步的表为无主键的表,全量初始化任务会比较慢。建议您为源库需同步的表增加主键后再进行同步。 可能原因二:在创建数据同步任务时,开启了流式数据 ETL 功能,由于 ETL 数据过滤耗时比较长,可能会出现全量初始化任务长时间无进展。
YARN Node Label介绍与最佳实践
然后在节点管理为TaskGroup-2节点组扩容一个节点等到新增节点状态从“初始化中”变成“运行中”后,进入访问链接>YARNResourceManager UI>Node Label的列表,查看TaskGroup-2下的两个节点都打上“batch”标签。在Nod... storm "表示Queue可以访问标签 hbase 和 storm。 yarn.scheduler.capacity..accessible-node-labels..capacity 设置Queue可以访问属于 分区内节点资源的百分比。每个父级下的直接子级的 容量总和必须等于 100。默...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 慢节点问题,更细粒度服务分级问题,成本问题和元数据瓶颈进一步凸显。我们在架构上也向着包括多租户体系构建、重构数据节点和元数据分层等方向进一步演进。这些演进涉及到非常多优化点,我们将在下文中给出详细的慢...
