hbase原理与实践源码
 社区干货
社区干货
【送书福利】5 本大数据热门好书!
原理和应用技巧进行了详细解读,可帮助读者深度理解并全面掌握 ClickHouse 运行原理并进行实践开发。本书采用 **浅显易懂的语言+大量演示案例+大量示意图例** 的形式呈现,以求让读者在最短的时间内,以最舒服的方式,获得最核心的知识。书中的理论观点来自作者在 OLAP 领域 10 余年的工作思考与总结;功能与实操的素材来自作者在工作中对 ClickHouse 的深度应用与实践;原理解析部分的素材来自对大量专业文献的钻研与源码级的调试...
基于国产化环境的金融级业务系统性能优化实践|社区征文
我分享的主题是基于国产化环境的金融级业务系统性能优化实践。# 一、项目背景项目是一个金融级的业务系统,架构是基于微服务设计理念的分布式架构,环境上支持国产化软硬件、操作系统以及分布式数据库,具有高性能... 它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续...
字节跳动 NoSQL 的探索与实践
列存:以 HBase 为代表; - 图、时序等新兴的数据库也都属于 NoSQL 范畴。如今 NoSQL 在字节跳动有非常广泛的应用:数万 NoSQL 应用实例,10W+ 台物理服务器资源,字节跳动超过 90% 的在线服务都是 NoSQL 系统提供的。### NoSQL 产品矩阵![]()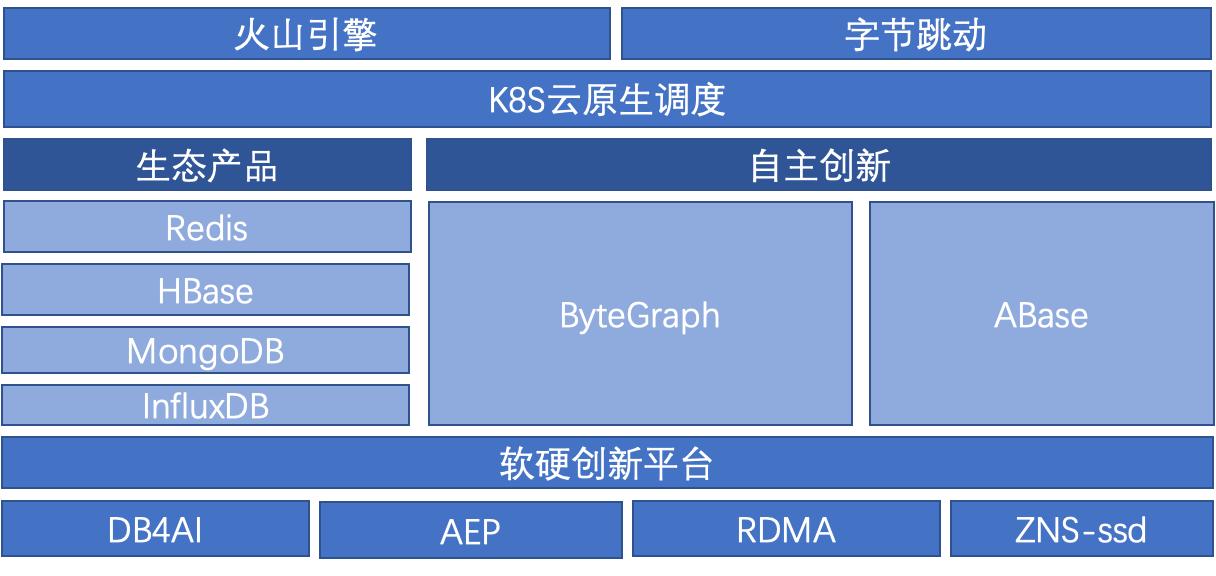上图是字节跳动 NoSQL 的产品矩阵。我们对内对...
9年演进史:字节跳动 10EB 级大数据存储实战
# 背景## **HDFS** **简介**HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:- 和本地文件系统一样的目录... 从集群规模和数据量来说,HDFS 平台在公司内部已经成长为总数十万台级别服务器的大平台,支持了 10 EB 级别的数据量。**当前在字节跳动,** **HDFS** **承载的主要业务如下:**- Hive,HBase,日志服务,Kafka 数据...
 特惠活动
特惠活动
 hbase原理与实践源码-优选内容
hbase原理与实践源码-优选内容
 hbase原理与实践源码-相关内容
hbase原理与实践源码-相关内容
字节跳动 NoSQL 的探索与实践
HBase、MongoDB 和 InfluxDB。此外自研的平台上提供了 ByteGraph 和 ABase,这两者和字节跳动的业务息息相关,也是内部业务重度依赖的两大产品。## 字节跳动 NoSQL 的最新实践字节跳动的大部分业务数据可归纳为以下几种类型:- 用户之间的关系:比如关注好友等;- 内容:视频、文章、广告等;- 用户和内容的连接:用户发布内容之后的评论、点赞、转发等,自媒体还会关注广告点击及分成收益等数据。这三种数据关联到一起就会形...
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
在实践中我们意识到,跟某种数据源相关联的能力,应该尽可能收敛到一起,这可以极大的降低后续的维护成本。对于一种元数据类型定义,也在这种考虑的范围之内。火山引擎 DataLeap 研发人员调整了Apache Atlas加载类型文... 其底层存储支持HBase/Cassadra/BerkeleyDB等KCV结构的存储,同时,使用ElasticSearch作为索引查询支持。当火山引擎 DataLeap 研发人员将越来越多的元数据接入系统,图存储中的点和边分别到达百万和千万量级,读写性能...
功能发布历史
支持托管 DRM 证书管理平台的访问密钥和 FairPlay 证书。 2024-03-18 DRM 管理 控制台指南 新增 DRM 配置,支持为指定的 AppName 配置并开启 DRM 加密。 2024-03-18 DRM 配置 最佳实践 新增直播 DRM 加密最佳实践。... 2023-09-04 回调配置 客户端 SDK 更新客户端 Demo 源码及快速跑通 Demo 的介绍。 2023-09-01 跑通Android Demo 跑通 iOS Demo 2023 年 7 月变更 说明 发布时间 相关文档 产品计费 计费方式由日结改为月结时,...
我的大数据学习总结 |社区征文
深入研究Yarn和求执行引擎Spark。此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和操作系统原理。后面再系统学习关系数据库MySQL和数据仓库理论。学习分布式原理和架构也很重要。这个学习顺序参考了... 这个实践例子帮助我真正理解了SparkSQL的运作机制。再比如如何进行大数据的实时计算和分析。以实时交易数据分析为例,需要对每笔交易进行实时计算和分析,找出异常交易模式。这里使用Spark Streaming来处理这个...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
进一步的理解和信任数据。另外,Data Catalog系统中的各类元数据,也会向上服务于数据开发、数据治理两大类产品体系。在大数据领域,各类计算和存储系统百花齐放,概念和原理又千差万别,对于元数据的采集、组织、理... Meta Store:存放全量元数据和血缘关系,当前使用的是HBase- Index Store:存放用于加速查询,支持全文索引等场景的索引,当前使用的是ElasticSearch- Model Store:存放推荐、打标等的算法模型信息,使用HDFS,...
干货 | 这样做,能快速构建企业级数据湖仓
**构建企业级数据湖仓最佳实践** 接下来我们通过几个案例来看看基于火山引擎EMR构建的企业级数据湖仓最佳实践。**案例 1:多元化分析平台**多元化分析指兼具离线分析场景与交互式分析... 并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型...
干货|Hudi Bucket Index 在字节跳动的设计与实践
> 由字节跳动数据湖团队贡献的 RFC-29 Bucket Index 在近期合入 Hudi 主分支,本文详细介绍 Hudi Bucket Index 产生的背景与实践经验。