hbase原理与实践pdf
 社区干货
社区干货
【送书福利】5 本大数据热门好书!
与应用实战》涵盖了ClickHouse 的时代背景、发展历程、核心概念、基础功能、运行原理、实践指导等多个维度的内容,尤其是在 **ClickHouse 最核心的部分——MergeTree 表引擎与分布式方面** ,书中对其实现原理和应用... 功能与实操的素材来自作者在工作中对 ClickHouse 的深度应用与实践;原理解析部分的素材来自对大量专业文献的钻研与源码级的调试与解读。**《关键迭代:可信赖的线上对照实验》** 特惠活动
特惠活动
 hbase原理与实践pdf-优选内容
hbase原理与实践pdf-优选内容
 hbase原理与实践pdf-相关内容
hbase原理与实践pdf-相关内容
9年演进史:字节跳动 10EB 级大数据存储实战
# 背景## **HDFS** **简介**HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:- 和本地文件系统一样的目录... 从集群规模和数据量来说,HDFS 平台在公司内部已经成长为总数十万台级别服务器的大平台,支持了 10 EB 级别的数据量。**当前在字节跳动,** **HDFS** **承载的主要业务如下:**- Hive,HBase,日志服务,Kafka 数据...
干货|Hudi Bucket Index 在字节跳动的设计与实践
> 由字节跳动数据湖团队贡献的 RFC-29 Bucket Index 在近期合入 Hudi 主分支,本文详细介绍 Hudi Bucket Index 产生的背景与实践经验。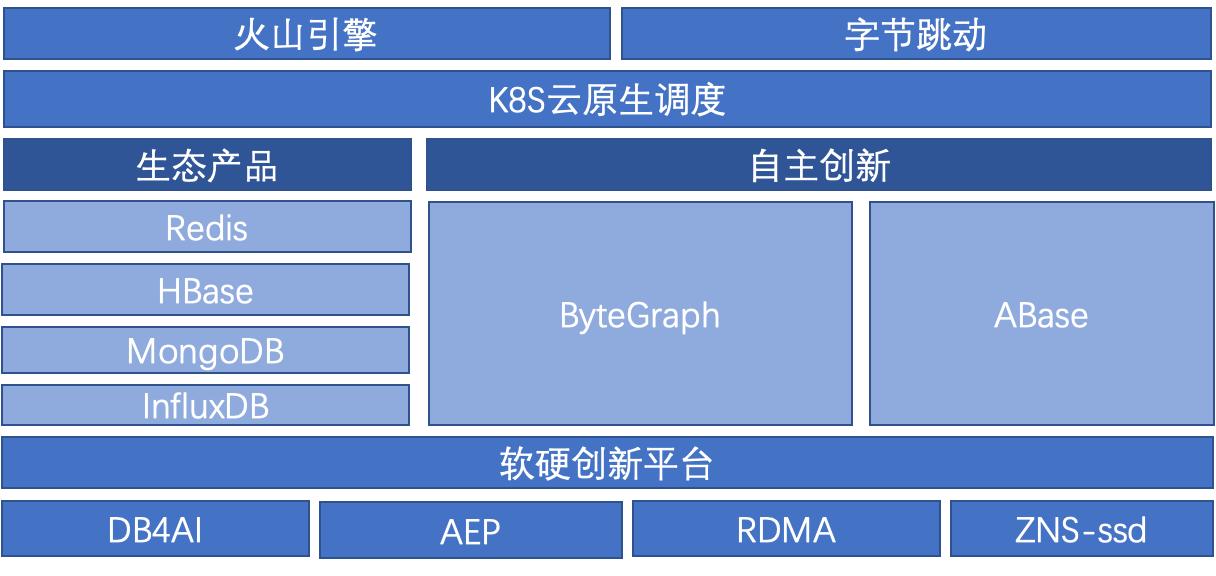上图是字节跳动 NoSQL 的产品矩阵。我们对内对...
干货 | 这样做,能快速构建企业级数据湖仓
**构建企业级数据湖仓最佳实践** 接下来我们通过几个案例来看看基于火山引擎EMR构建的企业级数据湖仓最佳实践。**案例 1:多元化分析平台**多元化分析指兼具离线分析场景与交互式分析... 并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型...
「火山引擎」数据中台产品双月刊 VOL.04
HBase 的必选组件;Impala、Kudu、ClickHouse、Doris、StarRocks 等服务的核心指标接入监控和告警管理;HBase 中的表支持 Snappy 压缩;Hive,组件行为与开源保持一致,不再支持中文的表字段名;Doris,版本升级至1.1.5;H... 算数和用数,实现降本增效、辅助决策。本次分享聚焦字节跳动数据中台实践,从算数(计算引擎优化)到用数(智能化决策场景)切入,并结合金融领域解决方案和实践案例,为大家带来数据中台建设思考。- **议题一:从业务出...
