hbase存100m图片
 社区干货
社区干货
干货 | 这样做,能快速构建企业级数据湖仓
数据通过离线的方式存到数据湖仓。离线数据可以通过 Spark 进行特征抽取及特征工程,并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型服务中。在在线方面,数据通过 Kafka 流入 Flink 进行在线特征抽取,然后把在线特征放在 Redis。同时在线部分的增量数据可用 TensorF...
基于国产化环境的金融级业务系统性能优化实践|社区征文
它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续产品SeaQuest。SeaQuest将Neoview从其专有的硬件,和专有的NonStop OS操作系统中移植到通用的x86服务器和通用的Linux操作系统上。2014年,乘着大数据的浪潮,SeaQuest将底层的数据存储和访问引擎移植到HBase/Hadoop上,...
字节跳动 NoSQL 的探索与实践
列存:以 HBase 为代表; - 图、时序等新兴的数据库也都属于 NoSQL 范畴。如今 NoSQL 在字节跳动有非常广泛的应用:数万 NoSQL 应用实例,10W+ 台物理服务器资源,字节跳动超过 90% 的在线服务都是 NoSQL 系统提供的。### NoSQL 产品矩阵![]()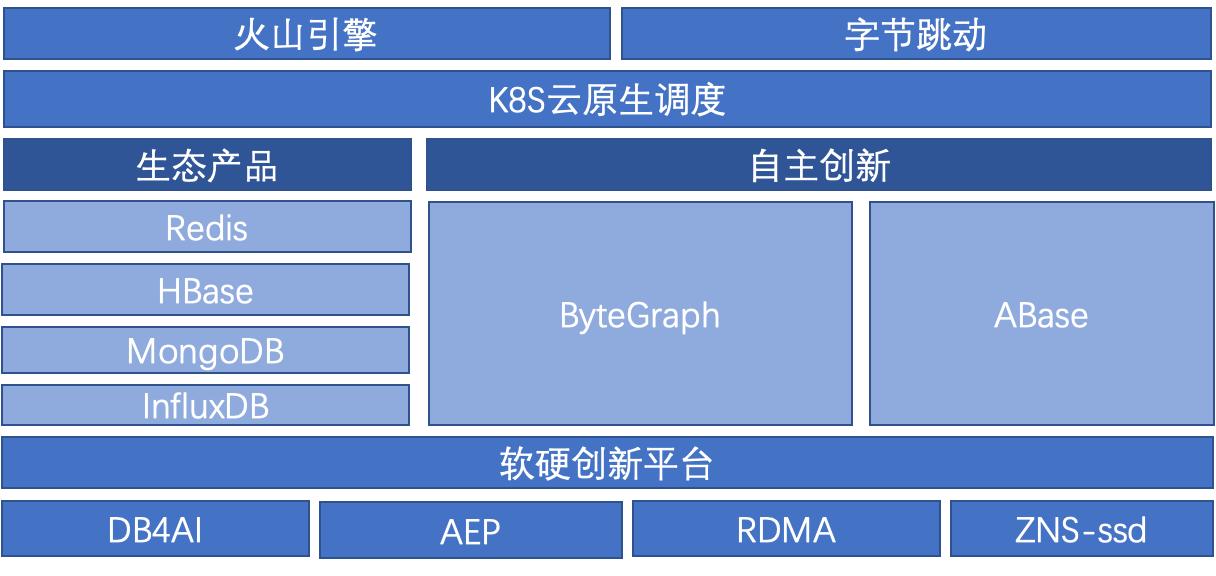上图是字节跳动 NoSQL 的产品矩阵。我们对内对...
20000字详解大厂实时数仓建设 | 社区征文
实时数仓的数据源存储不同:**- 在建设离线数仓的时候,目前滴滴内部整个离线数仓都是建立在 Hive 表之上。但是,在建设实时数仓的时候,同一份表,会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车...
 特惠活动
特惠活动
 hbase存100m图片-优选内容
hbase存100m图片-优选内容
 hbase存100m图片-相关内容
hbase存100m图片-相关内容
EMR-2.2.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - Z... 存算分离场景下,优化Spark引擎和MapReudce的写入性能。 已知问题通过Sqoop从SQL Server导入数据时,存在编码异常问题,如果需要使用此功能可联系售后处理,预计会在后续版本进行优化; 使用Dolphin Scheduler调度Pre...
EMR-3.6.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... hive_metastore 3.1.3 Hive元数据存储服务。 hive_server 3.1.3 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 3.1.3 Hive命令行客户端。 hdfs_namenode 3.3.4 用于跟踪HDFS文件名和数据块的服务。 hdf...
EMR-3.6.2 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... hive_metastore 3.1.3 Hive元数据存储服务。 hive_server 3.1.3 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 3.1.3 Hive命令行客户端。 hdfs_namenode 3.3.4 用于跟踪HDFS文件名和数据块的服务。 hdf...
基于国产化环境的金融级业务系统性能优化实践|社区征文
它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续产品SeaQuest。SeaQuest将Neoview从其专有的硬件,和专有的NonStop OS操作系统中移植到通用的x86服务器和通用的Linux操作系统上。2014年,乘着大数据的浪潮,SeaQuest将底层的数据存储和访问引擎移植到HBase/Hadoop上,...
字节跳动 NoSQL 的探索与实践
列存:以 HBase 为代表; - 图、时序等新兴的数据库也都属于 NoSQL 范畴。如今 NoSQL 在字节跳动有非常广泛的应用:数万 NoSQL 应用实例,10W+ 台物理服务器资源,字节跳动超过 90% 的在线服务都是 NoSQL 系统提供的。### NoSQL 产品矩阵![]()上图是字节跳动 NoSQL 的产品矩阵。我们对内对...
20000字详解大厂实时数仓建设 | 社区征文
实时数仓的数据源存储不同:**- 在建设离线数仓的时候,目前滴滴内部整个离线数仓都是建立在 Hive 表之上。但是,在建设实时数仓的时候,同一份表,会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车...
字节跳动 NoSQL 的探索与实践
> 本文整理自火山引擎开发者社区技术大讲堂第三期演讲,主要介绍了 NoSQL 的前世今生和发展脉搏,以及字节跳动 NoSQL 的实践。**作者:王佳毅|火山引擎存储&数据库解决方案负责人**## NoSQL 应用的现状什么是 ... HBase 为代表;- 图、时序等新兴的数据库也都属于 NoSQL 范畴。如今 NoSQL 在字节跳动有非常广泛的应用:数万 NoSQL 应用实例,10W+ 台物理服务器资源,字节跳动超过 90% 的在线服务都是 NoSQL 系统提供的。### ...
EMR-3.9.0发布说明
环境信息版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 系统环境应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 ... HBase组件中新增ThriftServer服务。 更改、增强和解决的问题【组件】Spark组件版本由3.3.3升级为3.5.1。 【组件】StarRocks组件版本由3.1.6升级为3.2.3,支持Assume role方式访问对象存储TOS,以及访问Paimon数据。...
字节跳动基于 Hudi 的机器学习应用场景
我们需要面临以下挑战:基于 HDFS 这种不可变的文件存储,如何实现低成本低读写放大的数据修改。在没有使用数据湖之前,用户做离线特征调研之前需要复制样本,修改并另存一份。其中消耗了巨大的计算和存储资源,伴随样本量的增大,这样的方案将消耗数个 EB 的存储,使得迭代变得不可能。我们基于 Hudi 实现了 ColumnFamily 的能力。这个方案受到了经典 BigTable 存储 Apache HBase 的启发,将 IO pattern 不同的数据使用不同的文件进行...
