逻辑模型是不是数据库图
 社区干货
社区干货
字节跳动自研万亿级图数据库 & 图计算实践
并将介绍图计算相关实践。 自研图数据库(ByteGraph)介绍 从数据模型角度看,图数据库内部数据是有向属性图,其 **基本元素是 Graph 中的点(Vertex)、边(Edge)以及其上附着的属性** ;作为一个工具,图数据对外提供的接口都是围绕这些元素展开。**图数据库本质也是一个存储系统**,它和常见的 KV 存储系统、MySQL 存储系统相比,主要区别在于目标数据的逻辑关系不同和访问模式不同,对于数据内在...
抖音大规模实践,火山引擎向量数据库是这样炼成的
如何用好大模型是当前各行各业瞩目的焦点。向量数据库作为大模型“记忆体”,不仅能够为其提供数据存储,而且能通过数据检索、分析让大模型进行知识增强,成为生成式 AI 应用开发新范式的重要组成部分。用图片搜索图片或者文本搜索文本时,在数据库中存储和对比的并不是图片和视频片段,而是通过深度学习等算法将其提取出来的“特征”,“特征”提取的过程称为 Embedding,提取出的“特征”用数学中的向量来表示。向量化的目的是为了...
抖音大规模实践,火山引擎向量数据库是这样炼成的
AI时代,如何用好大模型是当前各行各业瞩目的焦点。向量数据库作为大模型“记忆体”,不仅能够为其提供数据存储,而且能通过数据检索、分析让大模型进行知识增强,成为生成式AI应用开发新范式的重要组成部分。用图片搜索图片或者文本搜索文本时,在数据库中存储和对比的并不是图片和视频片段,而是通过深度学习等算法将其提取出来的“特征”,“特征”提取的过程称为 Embedding,提取出的“特征”用数学中的向量来表示。向量化的目的是...
分布式数据库TiDB的设计和架构
也知道是一款国人研发的数据库,但你知道TiDB到底是如何实现的?它跟其他数据库产品相比,它的核心优势是什么?此次夜校分享,xiaoyu向大家介绍了数据库发展史、TiDB 设计、架构及生态及TiDB在得物的应用。# 数据库技术发展演进**2008年以前**2008 年以前应用最为广泛的是单机关系型数据库(SQL),能很好的解决复杂的数据运算及表间处理,多用于银行、电信等传统行业复杂业务逻辑场景中,以 Oracle 为代表。此类数据库挑战在于成本...
 特惠活动
特惠活动
 逻辑模型是不是数据库图-优选内容
逻辑模型是不是数据库图-优选内容
 逻辑模型是不是数据库图-相关内容
逻辑模型是不是数据库图-相关内容
分布式数据库在抖音春晚活动中的应用
既然传统的大型数据库系统架构有这样一些问题,自然而然我们就会想着寻找另一条出路。那分布式数据库是不是我们要寻找的答案?目前看来,我们确实是在这条路上走得越来越远了。## 分布式数据库架构简介主流的分布... 最后我们会基于逻辑计划生成物理计划,物理计划描述的是我们怎么实际跟存储打交道,拉取哪些数据,需要做哪些具体的运算。- 接下来执行引擎就出场了(目前比较主流的是 volcano 模型),执行引擎把已经生成好的物理计...
一文读懂火山引擎云数据库产品及选型
根据卡内基梅隆大学维护的全球数据库信息库(dbdb.io)显示,数据库系统种类已经多达 870 种,可谓是欣欣向荣,让人眼花缭乱。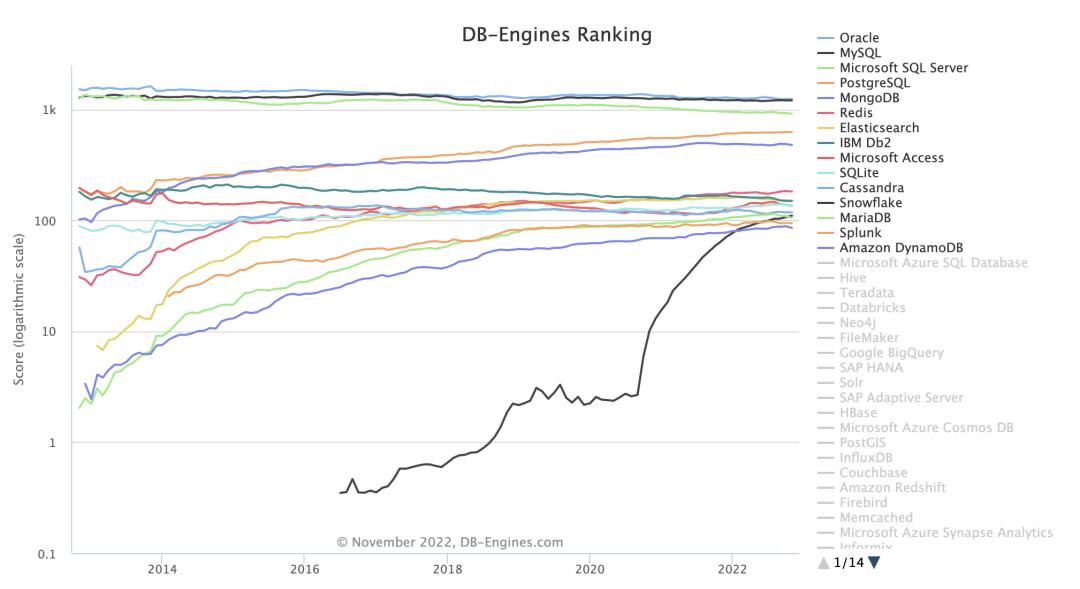纵观整个数据库发展史,关系型数据库系统是历史最悠久并且使用最广泛的一类数据库系统,其理论基础是基于 IBM 研究员 E.F.Codd 博士在 1970 年提出的“关系模型(Relational m...
[数据库系统] 业界列式存储浅析
行存的实现一般是将一行数据完整的从头到尾连续存储(超长的字段一般会单独存储,行内记录逻辑地址),连续多行构成一个页,页的尾部通常会存储索引来解决record不定长时的快速查找问题,数据排列结构如下图所示: