k-最近邻算法中分类和回归的区别是什么?
 社区干货
社区干货
2022下半年《软考-系统架构设计师》备考经验分享
我自己报考的是系统架构设计师,下面主要介绍系统架构设计师的备考方法。### 1、核心考点及复习建议#### 1.1 计算机基础知识(20%)对于计算机类科班的同学来说,这一部分主要就是在学校里学习的内容,主要包括:计算机组成与体系结构(计算机组成、指令系统、流水线技术、存储体系、总线等)、操作系统(进程与PV操作、存储管理、设备管理、文件管理等)、数据库系统(设计范式、关系代数、SQL、数据架构、并发控制等)、计算机网络(常见...
保姆级人工智能学习成长路径|社区征文
大家好,我是 herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池安全恶意程序检测第一名,科大讯飞恶意软件分类挑战赛第三名,CCF恶意软件家族分类第4名,科大讯飞阿尔... 对机器学习和深度学习拥有自己独到的见解。今天给大家分享的是保姆级人工智能学习成长路径,希望能对大家有所帮助,特别是处于迷茫期的同学们。# 0. 前言 最近有很多小伙伴想学习人工智能,其中不少同学渴望从事...
技术人的 2023 总结之无处不在的 AI|社区征文
=&rk3s=8031ce6d&x-expires=1714666836&x-signature=nr8FmFoYLQ5VZJ8ykCv0mZv2QDA%3D)最近一直想写一篇关于 2023 年所见所闻的文章,来记录一下 2023 年这一年的收获和感受。刚好在微信群看到了 InfoQ 社区与火山引... 写算法,写文章等,为大家的工作带来了极大的便利。随后 ChatGPT 继续飞速进化,短短时间就从初代 ChatGPT 经过了 GPT-2.5,GPT-3 到了 GPT-4,那么什么是 GPT-4 呢,这里顺道让 GPT-4 给出一个合理的解释 特惠活动
特惠活动
 k-最近邻算法中分类和回归的区别是什么?-优选内容
k-最近邻算法中分类和回归的区别是什么?-优选内容
 k-最近邻算法中分类和回归的区别是什么?-相关内容
k-最近邻算法中分类和回归的区别是什么?-相关内容
QCon高分演讲:火山引擎容器技术在边缘计算场景下的应用实践与探索
肯定比直接去访问客户中心要更短,响应时延一般都会在100毫秒以内。- 第二个就是带宽层面。传统的RTC或者一些服务直接回源到中心,它的回源带宽成本是比较高的。这个时候当你把一些策略和执行的算法放到边缘上执行... 进行区分和分类。当资源被标准化之后,我们会引入一层PaaS的资源管控层,这一层我们重点构建了第一个能力,就是解决第一个问题:海量资源的纳管问题。整个技术其实我们也是基于Kubernetes技术打造的。后面我会重点去...
客户端 SDK
参看: 视频自定义渲染 功能简述 API 获取本地视频流 setLocalVideoSink 停止获取本地视频流 unsetLocalVideoSink 获取远端视频流 setRemoteVideoSink 停止获取远端视频流 unsetRemoteVideoSink 设置渲染类型 setRe... 接口参看: 平台 Windows macOS Electron 接口 setVideoCaptureRotation setVideoCaptureRotation: setVideoCaptureRotation 根据进房时选择的业务场景自动适配音频降噪算法,满足多种场景下不同的降噪需求。支持...
干货|解析云原生数仓ByteHouse如何构建高性能向量检索技术
在搜索过程中,通过相同的一个模型把查询项转化成对应的向量,并进行一个近似度的匹配就可以实现对非结构化数据的查询。 在技术原理层面,向量检索主要是做一个 K Nearest Neighbors (K最近邻,简称 KNN) 计... 这类索引通常还会结合一些量化算法来使用,包括 SQ、PQ等。 **●**第四种是Graph-based, 把向量按照相似度构建成一个图结构,检索变成一个图遍历的过程。常用算法是HNSW。它基于关系查询,并以构建索引时...
我的技术年终总结——机器学习 |社区征文
(算法从数据中分析规律)- **预测**:利用训练后的算法完成任务(根据学习的规律为未知数据进行分类和预测) 通过周志华老师西瓜书上面的描述为下图: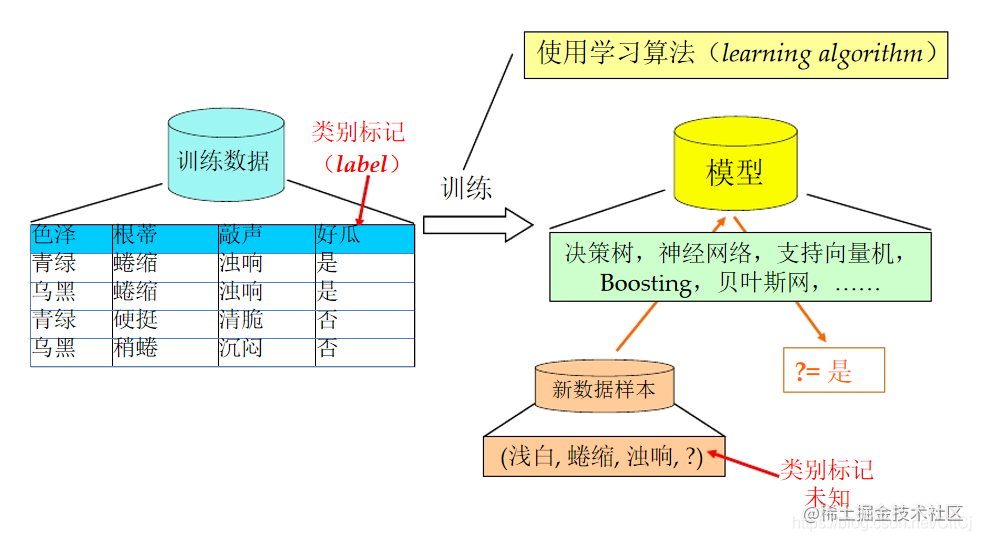## 二、机器学习能做什么? ### 数据集上 一个重要问题: 原书籍已经变成分散且混杂的多个书页,如何拼接相邻的书页? 人工完成...
使用pytorch自己构建网络模型总结|社区征文
> 🍊作者简介:[秃头小苏](https://juejin.cn/user/1359414174686455),致力于用最通俗的语言描述问题>> 🍊专栏推荐:[深度学习网络原理与实战](https://juejin.cn/column/7138749154150809637)>> 🍊近期目标:写好... (https://www.cs.toronto.edu/~kriz/cifar.html),使用这个数据的原因是这个数据比较轻量,基本上所有的电脑都可以跑。CIFAR10数据集里是一些32X32大小的图片,这些图片都有一个自己所属的类别(如airplane、cat等),如...
火山引擎工具技术分享:用AI完成数据挖掘,零门槛完成SQL撰写
算法建模和数据分析工作,也是一个提效的好办法。 同时,对于专业数仓团队来说,相同主题的数据内容面临“重复建设,使用和管理时相对分散”的问题——究竟有没有办法在一个任务里同时生产,同主题不同内容的数据... 拖入样本数据和全部数据作为数据输入1. 拖入分类算法,如XGB算法用于模型训练1. 拖入预测算子,搭建模型与全部数据的关系进行预测1. 实际数据和预测结果结合输出数据集,从而分析全部用户数据的意向分布...
工业大数据分析与应用——知识总结 | 社区征文
关系数据库、NoSQL数据库、云数据库等,实现对结构化、半结构化和非结构化海量数据的存储和管理。* 数据处理与分析:利用分布式并行编程模型和计算框架,结合**机器学习和数据挖掘**算法,实现对海量数据的处理和分析... IaaS三者之间的关系1) 从用户体验角度分析:从用户体验角度而言,它们之间关系是独立的,因为它们面对的是不同类型的用户。**SaaS主要面对的是普通用户,PaaS主要的用户是开发人员**。2) 从技术角度分析:云计算的服...
OLAP引擎也能实现高性能向量检索,据说QPS高于milvus!
在搜索过程中,通过相同的一个模型把查询项转化成对应的向量,并进行一个近似度的匹配就可以实现对非结构化数据的查询。在技术原理层面,向量检索主要是做一个 K Nearest Neighbors (K最近邻,简称 KNN) 计算,目标是... 这类索引通常还会结合一些量化算法来使用,包括 SQ、PQ等。- 第四种是Graph-based, 把向量按照相似度构建成一个图结构,检索变成一个图遍历的过程。常用算法是HNSW。它基于关系查询,并以构建索引时以及构建向量之...
解析云原生数仓 ByteHouse 如何构建高性能向量检索技术
在搜索过程中,通过相同的一个模型把查询项转化成对应的向量,并进行一个近似度的匹配就可以实现对非结构化数据的查询。在技术原理层面,向量检索主要是做一个 K Nearest Neighbors (K 最近邻,简称 KNN) 计算,目... 这类索引通常还会结合一些量化算法来使用,包括 SQ、PQ 等。* 第四种是 Graph-based, 把向量按照相似度构建成一个图结构,检索变成一个图遍历的过程。常用算法是 HNSW。它基于关系查询,并以构建索引时以及构建向量之...
