B+树磁盘实现
 社区干货
社区干货
打造新一代云原生"消息、事件、流"统一消息引擎的融合处理平台 | 社区征文
实现了单机处理海量队列的能力。队列数量可以无限扩展,以进一步释放云存储的潜力。LSM(Log-Structured Merge)原理RocketMQ引入了LSM(Log-Structured Merge)的KV(Key-Value)索引时,它改变了消息队列的存储方式和索引结构。- **传统的消息队列**:通常使用的是基于B+树的索引结构,这种结构在插入和删除操作时存在频繁的磁盘IO,限制了消息队列的吞吐量和性能。- **升级的消息队列**:LSM索引采用了一种更高效的存储方式。它...
火山引擎大规模机器学习平台架构设计与应用实践
分布式目录树服务:为平铺的 TOS 文件建立目录树结构;可支撑百万 QPS,专为小文件优化。这里我们用一个实验来证明整体损耗情况。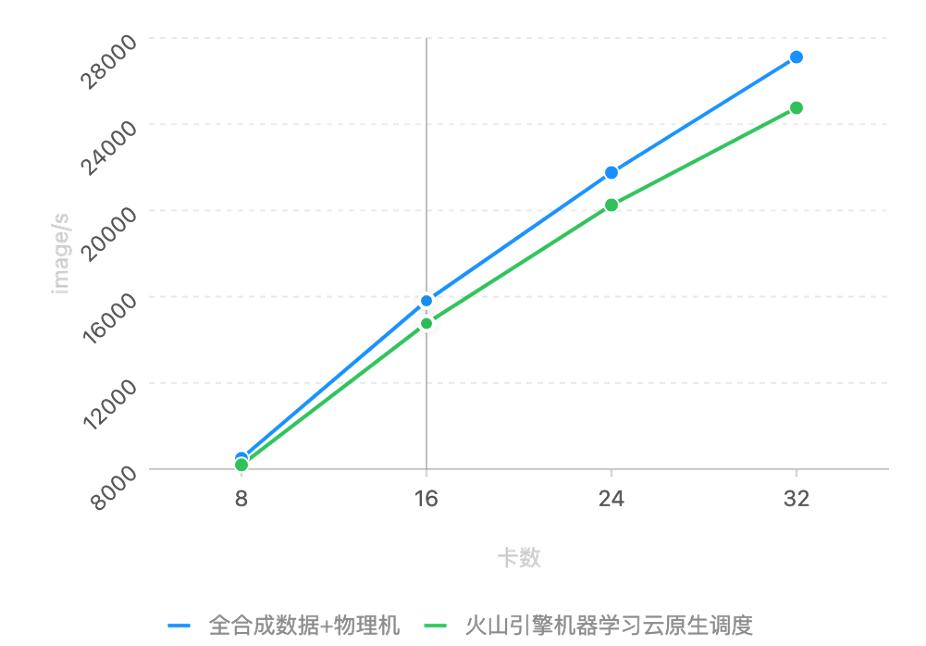该实验是一个多机多卡的分布式训练场景。图中的蓝线表示没有任何的文件 IO,因为数据都是 mock 的,不需要从磁盘上读。另外它基于物理机,所以没有虚拟化的...
万字长文带你漫游数据结构世界|社区征文
[](https://markdownpicture.oss-cn-qingdao.aliyuncs.com/blog/20220108122738.png)这就是跳表了,跳表的定义如下:> 跳表(SkipList,全称跳跃表)是用于有序元素序列快速搜索查找的一个数据结构,跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。它在性能上和红黑树,AVL树不...
用 Weave Net 打开跨主机容器互联大门 | 社区征文
Weave 通过 UDP 封装实现 L2 Overlay。数据封装支持两种模式:- 运行在 user space 的 sleeve mode:通过 pcap 设备在 Linux bridge 上截获数据包并由 wRouter 完成 UDP 封装,支持对 L2 traffic 进行加密,还支... BoltDB 将数据保存在一个单独的内存映射的文件里。它没有 wal、线程压缩和垃圾回收;它仅仅安全地处理一个文件。BoltDB 使用一个单独的内存映射的文件,实现一个写入时拷贝的 B+树,这能让读取更快。而且,BoltDB 的...
 特惠活动
特惠活动
 B+树磁盘实现
-优选内容
B+树磁盘实现
-优选内容
 B+树磁盘实现
-相关内容
B+树磁盘实现
-相关内容
Katalyst Memory Advisor:用户态的 K8s 内存管理方案
无法实现有效的超卖。针对上述问题,字节跳动将其在大规模在离线混部过程中积累的精细化的内存管理经验,总结成了一套用户态的 Kubernetes 内存管理方案 Memory Advisor,并在资源管理系统 Katalyst 中开源。本文将... 由于访问内存的速度比访问磁盘快很多,Linux 使用内存的策略比较贪婪,采取尽量分配,当内存水位较高时才触发回收的策略。 **内存分配**内核的内存分配方式主要包含 2 种:* **快速内存分配** :首先尝试进行...
数据一致性离不开的checkpoint机制 |社区征文
## checkpoint如果系统每次收到写入请求后,等待数据完全写入持久化存储再返回结果,这样数据丢失的可能性大大减少,但是一般持久化操作都是磁盘IO操作(甚至网络IO操作),处理的耗时比较长,这样读写的效率就会很低。... (https://loser-wang.oss-cn-beijing.aliyuncs.com/blog/kafka%E9%AB%98%E6%B0%B4%E4%BD%8D/hw/%E6%95%B0%E6%8D%AE%E5%BA%933.png) 而对**介质故障**对恢复通过备份实现的。在某一时刻,对数据库在其他介质存储上产...
火山引擎大规模机器学习平台架构设计与应用实践
不需要从磁盘上读。另外它基于物理机,所以没有虚拟化的损耗。绿线是真实的训练场景,数据需通过 IO 读进来。它是基于云原生的系统,有一些网络虚拟化。从图中可以看到绿线和蓝线非常接近,说明我们整体的 IO 和虚拟... 这些算子的性能往往比好的开源实现有非常明显的提升。在 **通信上** :我们开源了 BytePS 的通信框架。BytePS 同时利用了 CPU 和 GPU 两种异构资源来加速通信,在对拓扑的探测上做了细致和智能的优化,并且支持异...
字节跳动 Spark Shuffle 大规模云原生化演进实践
groupByKey、Join、sortByKey 和 Repartition 的操作都会使用到 Shuffle。所以在大规模的 Spark 集群内,Spark Shuffle 经常会成为性能及稳定性的瓶颈;Shuffle 的计算也会涉及到频繁的磁盘和网络 IO 操作,解决办法是... =&rk3s=8031ce6d&x-expires=1714062047&x-signature=a5RWDvHoycnQjVQrrgRheu%2B2axU%3D)针对这种情况,我们提供的解决方案是控制每个容器或每个节点写入磁盘的 Shuffle 数据总量。这个功能可以从两个角度实现。首...
Redis String 实现 ID 生成器,底层为啥用 SDS 存储数据?| 社区征文
实现了你们领导平时经常对你们提出的既要又要还要的目标。先看 **C 语言字符串数组的结构**。比如通过 `char *s = "MageByte"`定义字符串变量。会存储主键值,主键越大,每个 Page 页可以存储的数据就越少,访问磁盘 I/O 的次数就会增加。Redis 集群能保证高可用和高性能,为了节省内存,ID 可以使用数字的形式,并且通过递增的方式...
干货 | ByteHouse:基于ClickHouse 的实时计算能力升级
字节内部每天新增的数据量就达到了 100 个TB。其次,在数据量大的基础上,仍要保有包含以下三个方向非常强的灵活性: **●****数据源头的灵活性。**也同时去支持批示数据和流式数据的导入,实现批流一体。... 数据存储都通过磁盘来进行**●****指数:**指数通过内存来进行(快但贵) 在服务画像的基础上,Katalyst 针对 CPU、内存、磁盘和网络等方面提供...
火山引擎云搜索服务升级云原生新架构;提供数十亿级分布式向量数据库能力
Kibana 等软件及常用开源插件。可以提供结构化、非结构化文本的多条件检索、统计、报表,帮助实现一键部署、弹性扩缩、简化运维,快速构建日志分析、信息检索分析等实际业务。 而伴随着 Serverless 的兴起和大... 还会将构建好的向量索引持久化到磁盘,索引更加稳定。结合 ESCloud 产品的倒排索引,可以将向量检索和全文检索的能力融合,实现更加强大的混合搜索(Hybrid Search)能力。在 ESCloud 的集群基础上,k-NN 向量数据库可以...
干货|从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
BvryKJy4MUnn44x6m1ByHtU%3D)**问题二:Kafka 消费能力不足**社区版本的 Kafka 表,内部默认只会有一个消费者,这样会比较浪费资源并且性能达不到性能要求。尝试优化过程:* 尝试通过增大消费者的个数来增大消费能力,但社区的实现是由一个线程去管理多个的消费者,多个消费者消费到的数据最后仅能由一个输出线程完成数据构建,所以这里没能完全利用上多线程和磁盘的潜力;* 尝试通过创建多张 Kafka Table 和 Ma...
