flink多次调用registerProcessingTimeTimer的行为
 社区干货
社区干货
干货|字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化(2)
本文分两次连载,[第一篇主要介绍Flink Checkpoint 以及 MQ dump 写入流程。](http://mp.weixin.qq.com/s?__biz=MzkwMzMwOTQwMg==&mid=2247490866&idx=1&sn=ff8e0bce2bce0eaea87cfafcaba4c6f6&chksm=c0996c07f7eee... 但是由于删除操作的重复执行造成创建的两个文件被删除。| src\_path | method | operation\_cost\_ms | toDateTime(local\_timestamp\_ms) | result || /xx/\_DUMP\_TEMPORARY/cp-4608/task-2/date=202...
字节跳动流式数据集成基于 Flink Checkpoint 两阶段提交的实践和优化背景
Operator 收到信号以后会调用相应的函数进行 Notify 的操作。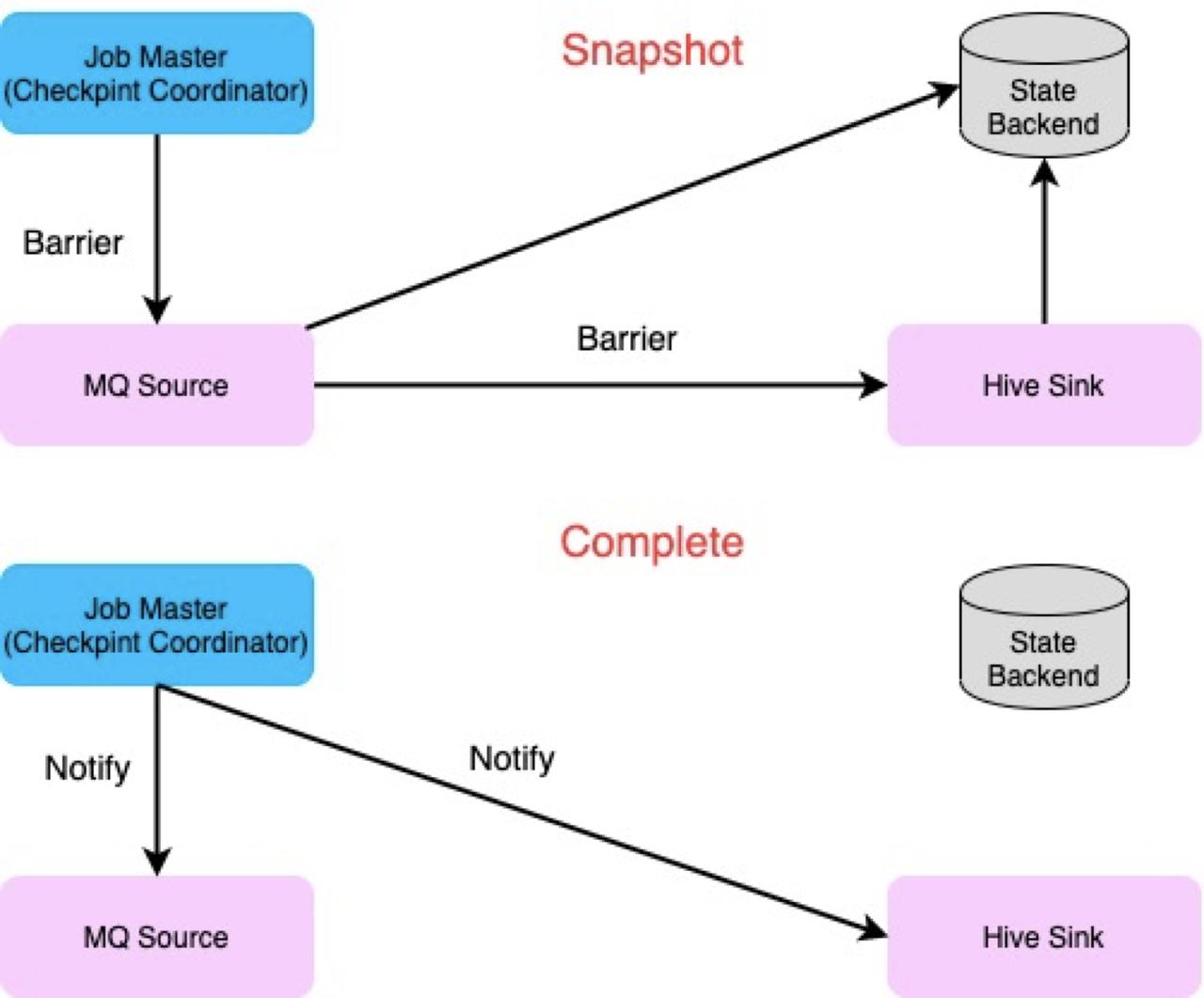而在任务失败后,任务会从上一个 Checkpoint state 中进行恢复,进而实现 Exactly Once 或者 At Least Once 语义。# MQ dump 写入流程梳理MQ dump 利用 Flink Checkpoint 机制和 2PC(Two-phase Commit) 机制实现了 Exactly Once 语...
揭秘|字节跳动基于Flink SQL的流式数据质量监控(下)实践细节
字节跳动数据质量平台对于批处理数据的质量管理能力已经十分丰富,提供了包括表行数、空值、异常值、重复值、异常指标等多种模板的数据质量监控能力,也提供了基于spark的自定义监控能力。另外,该平台还提供了数据对... 上线了一系列基于Flink StreamSQL的流式数据质量监控。DataLeap流式数据质量监控的技术架构以Kafka数据源为例,流式数据质量监控的技术架构及流程图如下所示: 特惠活动
特惠活动
 flink多次调用registerProcessingTimeTimer的行为
-优选内容
flink多次调用registerProcessingTimeTimer的行为
-优选内容
 flink多次调用registerProcessingTimeTimer的行为
-相关内容
flink多次调用registerProcessingTimeTimer的行为
-相关内容
ES 数据写入方式:直连 VS Flink 集成系统
(Online Transaction Processing)系统相媲美的。也正因如此,通常它的数据都来源于其他存储系统同步而来,做二次过滤和分析的。这就引入了一个关键节点,即 ES 数据的同步写入方式,本文介绍的则是 MySQL 同步 ES 方式。将 MySQL 数据写入 ES,首先想到的一定是消费 Binlog 直连 ES 写入,这种方式简单明了,然而如果稍微考量维度多一点,就会发现该方式的一些弊端。因此还有另外一个方式,即 **【RocketMQ + Flink Consumer +...
DataLeap的Catalog系统近实时消息同步能力优化
# 摘要字节数据中台DataLeap的Data Catalog系统通过接收MQ中的近实时消息来同步部分元数据。Apache Atlas对于实时消息的消费处理不满足性能要求,内部使用Flink任务的处理方案在ToB场景中也存在诸多限制,所以团队... 处理中的队列堆顶 > 处理完的队列堆顶:异常情况,通常是数据回放到某些中间状态,将处理完的队列堆顶出堆。注意:当发生Consumer的Rebalance时,需要将对应Partition的队列清空## KeyBy与Delay Processing的支...
Flink 使用 Proton
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.OnCheckpointRollingPolicy;import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;import org.apache.f...
字节跳动基于Apache Atlas的近实时消息同步能力优化 | 社区征文
并编写了Flink任务承担这部分工作,比较好的解决了扩展性和性能问题。然而,到2021年年中,团队开始重点投入私有化部署和火山公有云支持,对于Flink集群的依赖引入了可维护性的痛点。在仔细的分析了使用场景和需求,并... 同一Group内的Consumer数据不会重复消费。- Consumer:消费消息的最小单位,属于某个Consumer Group。- Partition:Topic中的一部分数据,同一Partition内消息有序。同一Consumer Group内,一个Partition只会被...
EMR Flink 数据写入 Bytehouse
集群提交 Flink SQL 和 Flink jar 任务,将数据写入到 ByteHouse 集群的方法。 2 EMR Flink 数据写入ByteHouse(云数仓版)2.1 前提条件已创建火山引擎 EMR 集群。具体操作,请参见 E-MapReduce 快速入门-火山引擎 已... TimerTask() { @Override public void run() { System.out.printf("source is pulled %s times\n", pullCoun...
干货|字节跳动基于Apache Atlas的近实时消息同步能力优化
内部使用Flink任务的处理方案在ToB场景中也存在诸多限制,所以 **团队自研了轻量级异步消息处理框架,支持了字节内部和火山引擎上同步元数据的诉求。本文定义了需求场景,并详细介绍框架的设计与实现。**> > > >... **KeyBy与Delay Processing的支持**因源头的Topic和消息格式有可能不可控制,所以MQ Consumer的职责之一是将消息统一封装为Event。根据需求,会从原始消息中拼装出Event Key,对Key取Hash后,相同结果的...
EMR-3.1.0版本说明
环境信息 系统环境版本 环境 OS veLinux (Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSearch集... 其中StarRocks版本为2.4.1: StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库。StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。用户无需经过复杂的预处理,就可以用 StarRoc...
火山引擎DataLeap基于Apache Atlas自研异步消息处理框架
内部使用Flink任务的处理方案在ToB场景中也存在诸多限制,所以**团队自研了轻量级** **异步** **消息处理框架,支持了字节内部和** **火山引擎** **上同步元数据的诉求。本文定义了需求场景,并详细介绍框架的设计与实... 同一Group内的Consumer数据不会重复消费。- Consumer:消费消息的最小单位,属于某个Consumer Group。- Partition:Topic中的一部分数据,同一Partition内消息有序。同一Consumer Group内,一个Partition只会被...
集群类型
支持的集群类型以及各集群相关的操作。 集群 描述 重要操作 Hadoop Hadoop生态圈的基础服务组件,HDFS,YARN,MapReduce组件。 提供离线数据分析,Hive、Spark、Tez。 提供实时数据分析,Flink、SparkStreaming。 ... Doris基础使用 Hudi数据湖分析 Doris连接Tableau StarRocks 新一代极速全场景 MPP (Massively Parallel Processing) 数据库,采用了全面向量化引擎,让用户的数据分析变得更加简单和敏捷。 StarRocks基础使用...
