中位数中位数算法为什么要将数组分成大小为5的块,如果我们将其分成大小为4的分组会对时间复杂度产生影响吗?
 社区干货
社区干货
万字长文带你漫游数据结构世界|社区征文
如果我们能了解数据结构,找到较为适合当前问题场景的数据结构,将数据之间的关系表现在存储上,计算的时候可以较为高效的利用适配的算法,那么程序的运行效率肯定也会有所提高。常用的4种数据结构有:- 集合:只有... 其余位表示值- 反码:正数的补码反码是其本身,负数的反码是符号位保持不变,其余位取反。- 补码:正数的补码是其本身,负数的补码是在其反码的基础上 + 1### 为什么有了原码还要反码和补码?我们知道加减法是高...
Kubernetes 观测:基于 eBPF 的云原生深度可观测性实践
哪些组件会受到影响?* 海量的观测数据及告警应该如何关联?这些问题,也正是真正困扰技术团队的问题。根据可观测性模型理论,要能够回答这些问题,核心要实现的 2 个必要维度便是:**拓扑**和 **时间**。... 比如基于 L4 拓扑,我们只能感知到一些网络层的异常情况,当需要观测应用层具体错误码或者哪个接口异常的场景,就无从入手了。因此,我们还需要额外实现 L7 的拓扑能力。L7 协议流量追踪会比 L4 复杂度更高,需要额...
节省90%编译时间,这是字节跳动开源的基于Rust的前端构建工具
主要分析项目依赖,然后生成一个模块依赖图;第二个阶段 seal 阶段,主要是做代码产物优化以及最终产物生成。 产物优化主要包括 tree-shaking 和 bundle-splitting, code-splitting 以及 minify。 tree-shaking 使用类似垃圾回收 mark-sweep 算法,遍历所有可能被执行的代码,将所有不会被执行的代码删除。 code-splitting 通过重新将模块进行组合,使用一些策略将其分割生成若干 chunk,最终达到更快速的...
Redis String 实现 ID 生成器,底层为啥用 SDS 存储数据?| 社区征文
`alloc - len` 就等于 char 类型的 buf 数组未使用的字节数(Redis 7.0 已经去掉了表示未使用字节数 free 字段)。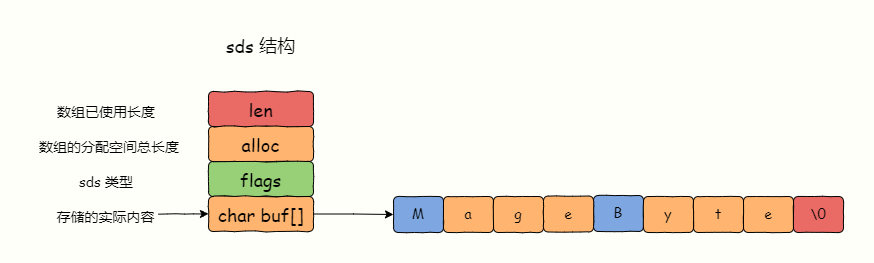图 2-2**SDS 也遵循 C 字符串以空字符“\0”结尾的惯例,保存空字符的大小不计算在 SDS 的 len 属性中。**此外,添加空字符串“\0” 到字符串末尾等操作,都是由 SDS 函数自动完成的。**O(1) 时间复杂度获取字符串长度**SD...
 特惠活动
特惠活动
 中位数中位数算法为什么要将数组分成大小为5的块,如果我们将其分成大小为4的分组会对时间复杂度产生影响吗?
-优选内容
中位数中位数算法为什么要将数组分成大小为5的块,如果我们将其分成大小为4的分组会对时间复杂度产生影响吗?
-优选内容
 中位数中位数算法为什么要将数组分成大小为5的块,如果我们将其分成大小为4的分组会对时间复杂度产生影响吗?
-相关内容
中位数中位数算法为什么要将数组分成大小为5的块,如果我们将其分成大小为4的分组会对时间复杂度产生影响吗?
-相关内容
火山引擎DataLeap数据调度实例的 DAG 优化方案
在平台中,一个核心的功能为任务的调度,会根据任务设置的调度频率(月级,日级,小时级等)运行任务,从而生成对应的实例。在数仓研发中,不同的表之间会存在依赖关系,而产生表数据的任务实例,也会因此存在依赖关系。只... 在原始数据中,是以一个数组的形式返回节点信息及依赖关系。所以,需要对数据进行处理形成图所需要的数据,同时,利用多个 map 对数据进行存储,方便后续对数据进行检索,减少时间复杂度。将其拆分到几个互相独立的文件中 。 这些文件应该具有原子特... 因为用于 node 服务端,文件都在本地,同步导入即使卡住对主线程影响也不大。而 ES Module 是异步导入,因为用于浏览器,需要下载文件,如果也采用同步导入会对渲染有很大影响。**ES 模块为什么要设计成静态的?**将...
Spark AQE SkewedJoin 在字节跳动的实践和优化
拆分后的数据大小几乎和中位数一致,将长尾Task的影响降到最低。MapStage 执行结束之后,每一个 MapTask 会生成统计结果 MapStatus,并将其发送给 Driver。MapStatus维护了一个 Array[Long],记录了该 MapTask 中属于... 拆分后的两个 task 的 ShuffleRead 均为 100。我们可以看出,统计信息的大小的空间复杂度是 O(M*R),对于大任务而言,会占据大量的 Driver 内存,所以 Spark 原生做了限制,对于 MapTask,当下游 ReduceTask 个数大于某...
干货|一套架构框架满足流批数据质量监控
多出现在数据系统达到一定的复杂度后,同一指标会在多处进行计算,由于计算口径或者开发人员的不同,容易造成同一指标出现不同的结果。* **及时性**:在确保数据的完整性、准确性和一致性后,接下来就要保障数据能够及时产出,这样才能体现数据的价值。及时性很容易理解,主要就是数据计算出来的速度是否够快,这点在数据质量监控中可以体现在监控结果数据是否在指定时间点前计算完成。* **规范性**:指数据是否按照要求的规则进行存...
人生大事「我的 2022 技术总结与盘点」|社区征文
一年的时间感觉经历了人生中几件大事:`裁员` `被裁` `学习` `重新入职` `卖房` `看房` `迁移户口` `买房` `装修` # 工作## 裁员这里的裁员是指裁掉自己的下属😭。我曾经是一个开发团队的小Leader,随着2020年... 要一直不停的刷算法,这一点在下半年没有很好的坚持,反思自己,打脸.......### 算法[Swift 有序数组获取绝对值最小的数](!https://juejin.cn/post/7125764751623192607)[ Swift 获取无序的整数序列的中位数(堆...
SQL自定义查询(SaaS)
level的推荐取值范围为[0.01, 0.99],默认值level=0.5,即为计算中位数。 expr —— 表达式。 可选数值、日期或时间数据类型 median(expr)相当于是quantile(0.5)(expr)注意: 该函数采用Reservoir_sampling随机算法,因... 数组函数 arrayEnumerate(arr) 返回与源数组大小相同的数组,其中每个元素表示与其下标对应的原数组元素在原数组中出现的次数。常用用法类似hive中的开窗函数row_number()参数: arr 数组举例:查询2020年10月25日至1...
SQL自定义查询(SaaS)
level的推荐取值范围为[0.01, 0.99],默认值level=0.5,即为计算中位数。 expr —— 表达式。 可选数值、日期或时间数据类型 median(expr)相当于是quantile(0.5)(expr) 注意: 该函数采用Reservoir_sampling随机算法,... 数组函数 arrayEnumerate(arr) 返回与源数组大小相同的数组,其中每个元素表示与其下标对应的原数组元素在原数组中出现的次数。常用用法类似hive中的开窗函数row_number() 参数: arr 数组 举例:查询2020年10月25日...
5年迭代5次,抖音推荐系统演进历程
对于窗口类型的特征在字节内部有一些基于存储引擎的方案,整体思路是“**轻离线重在线**”,即把窗口状态存储、特征聚合计算全部放在存储层和在线完成。离线数据流负责基本数据过滤和写入,离线明细数据按照时间切分聚... 在线模块非常轻量级,只负责简单的在线 Serving,极大地简化了在线层的架构复杂度。在离线状态存储层。我们主要依赖 Flink 提供的**原生状态存储引擎 RocksDB**,充分利用离线计算集群本地的 SSD 磁盘资源,极大减轻在...
5年迭代5次,抖音推荐系统演进历程
对于窗口类型的特征在字节内部有一些基于存储引擎的方案,整体思路是“ **轻离线重在线**”,即把窗口状态存储、特征聚合计算全部放在存储层和在线完成。离线数据流负责基本数据过滤和写入,离线明细数据按照时间切... 在线模块非常轻量级,只负责简单的在线 Serving,极大地简化了在线层的架构复杂度。在离线状态存储层。我们主要依赖 Flink 提供的 **原生状态存储引擎 RocksDB**,充分利用离线计算集群本地的 SSD 磁盘资源,极大减轻...
