以二进制形式读写文件
 社区干货
社区干货
如何使用 SAR 监控Linux 中的系统性能
并将采样结果以二进制形式存入当前目录下的文件monitor中,使用命令`sar -u -o monitor 1 5`如图所示。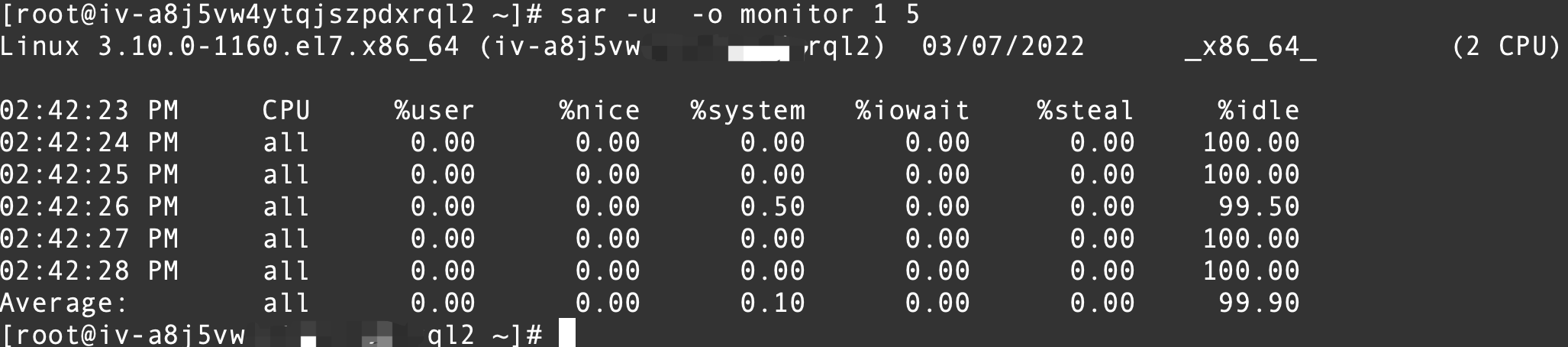其中-o表示以二进制的格式把结果存入到monitor文件中,不能使用cat,more,less等查看。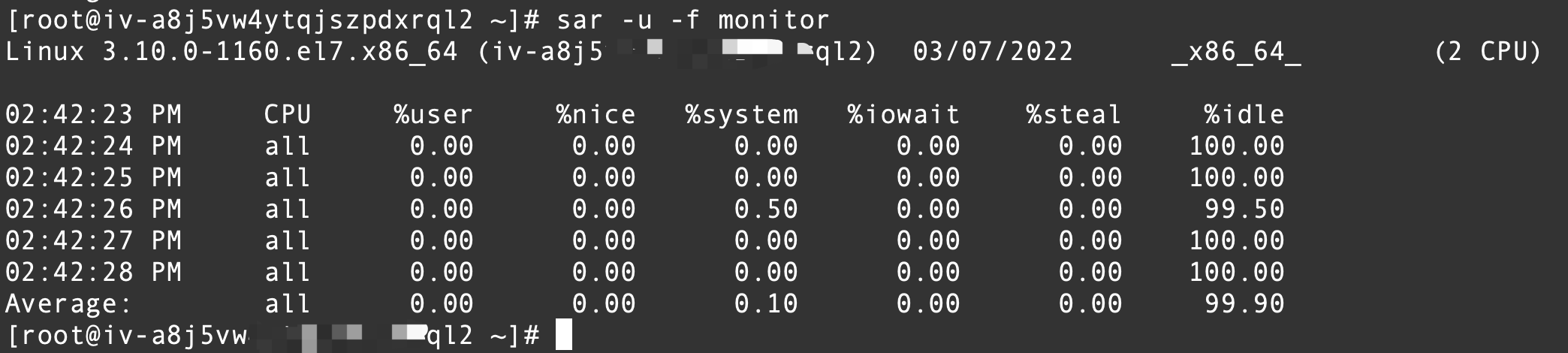...
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
Magic Number 用于文件类型标识校验。 - Body 是 UIMetaStore 的主体数据,使用连续存储。每一个 UI 相关的类实例,会序列化成四个片段:类名长度(4 byte long 类型)+ 类名(string 类型)+ 数据长度(4 byte long 类型)+ 序列化的数据(二进制类型)。在读取时顺序读取,每个元素先读取长度信息,再根据长度读取后续相应数据进行反序列化。 - 使用 Spark 原生的 KVStoreSerializer 序列化,可以保证前后兼容性。 ### 2.2.2...
dubbo系列之-序列化
protobuf 协议需要有.proto 文件和转换工具支持([https://github.com/protocolbuffers/protobuf/releases](https://github.com/protocolbuffers/protobuf/releases)),我们这里为了简单采用protostuff进行测试,他们两者生成的二进制数据结构格式完全相同的,可以说protostuff是一个基于Protobuf的序列化工具,protostuff通过schema的形式简化了复杂的自定义过程。 protobuf采用T-L-V (Tag-Length-Value)作为存储方式,既压缩后的...
万字长文带你漫游数据结构世界|社区征文
我们有了以下定义:> 数据结构是[计算机](https://baike.baidu.com/item/计算机/140338)存储、组织[数据](https://baike.baidu.com/item/数据)的方式。数据结构是指相互之间存在一种或多种特定关系的[数据元素](h... 在计算机中表示信息的最小的单位是二进制数中的一位,叫做**位**。也就是我们常见的类似`01010101010`这种数据,计算机的底层就是各种晶体管,电路板,所以不管是什么数据,即使是图片,声音,在最底层也是`0`和`1`,如果有...
 特惠活动
特惠活动
 以二进制形式读写文件
-优选内容
以二进制形式读写文件
-优选内容
 以二进制形式读写文件
-相关内容
以二进制形式读写文件
-相关内容
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
Magic Number 用于文件类型标识校验。 - Body 是 UIMetaStore 的主体数据,使用连续存储。每一个 UI 相关的类实例,会序列化成四个片段:类名长度(4 byte long 类型)+ 类名(string 类型)+ 数据长度(4 byte long 类型)+ 序列化的数据(二进制类型)。在读取时顺序读取,每个元素先读取长度信息,再根据长度读取后续相应数据进行反序列化。 - 使用 Spark 原生的 KVStoreSerializer 序列化,可以保证前后兼容性。 ### 2.2.2...
dubbo系列之-序列化
protobuf 协议需要有.proto 文件和转换工具支持([https://github.com/protocolbuffers/protobuf/releases](https://github.com/protocolbuffers/protobuf/releases)),我们这里为了简单采用protostuff进行测试,他们两者生成的二进制数据结构格式完全相同的,可以说protostuff是一个基于Protobuf的序列化工具,protostuff通过schema的形式简化了复杂的自定义过程。 protobuf采用T-L-V (Tag-Length-Value)作为存储方式,既压缩后的...
万字长文带你漫游数据结构世界|社区征文
我们有了以下定义:> 数据结构是[计算机](https://baike.baidu.com/item/计算机/140338)存储、组织[数据](https://baike.baidu.com/item/数据)的方式。数据结构是指相互之间存在一种或多种特定关系的[数据元素](h... 在计算机中表示信息的最小的单位是二进制数中的一位,叫做**位**。也就是我们常见的类似`01010101010`这种数据,计算机的底层就是各种晶体管,电路板,所以不管是什么数据,即使是图片,声音,在最底层也是`0`和`1`,如果有...
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
就完整读取对应的 event log 文件,进行解析。解析的过程就是一个回放过程(replay)。Event log 文件中的每一行是一个序列化的 event,将它们逐行反序列化,并使用 `ReplayListener`将其中信息反馈到 `KVStore` 中,还原... event log 可以达到几十 GB。 **字节内部 7 天的 event log 占用约 3.2** **PB** **的** **HDFS** **存储空间。*** #### **回放效率差,延迟高**History Server 采用回放解析 event log 的方式还原 ...
字节跳动基于 Parquet 格式的降本增效实践 | CommunityOverCode Asia 2023
我们采用了一种快速合并的方式,这种方式借鉴了 Parquet 社区所提供的 merge 工具,能够快速地将多个 Parquet 文件合并成一个,下面介绍一下它的实现原理。Parquet 文件的内部有很多内容,例如 Footer、RowGroup 等等。这些内容可以分为 2 类,一类是被压缩和编码后的实际数据,而另一类则是记录了数据是如何被编码和排列的元数据。快速合并的基本思路就是:直接 copy 实际数据所对应的原始二进制 Data(跳过编解码流程),再基于数据...
打造通用缓存层:字节跳动 Flink StateBackend 性能提升之路
序列化后的结果也会比以 Object 的形式存在内存中要小,因此支撑的状态规模比 FsStateBackend大。另外,RocksDBStateBackend 在 JVM 的 Heap 中没有额外的状态数据存储,对应的 GC 压力非常低。但是都是以二进制的形式... **对应多条数据的模式看作对于热点数据的访问,把这些热点数据进行缓存,这样就可以减少序列化和反序列化的开销。**编解码**:JSON 没有对应的 schema,只能依据自描述语义将读取到的 value 解释为对应语言的运行时对象,例如:JSON object 转化为 Go map[string]interface{};- ... 5. 将生成的二进制码注入到内存 cache 中并封装为 go function ([DL](https://github.com/bytedance/sonic/blob/fe56a21bf5d1aef425cbe94edce394e07d758994/internal/loader/loader.go#L36)) 6. 后续解析,直接根...
Kubectl 插件开发及开源发布分享 | 社区征文
利用其可以轻松的完成kubectl 插件的全上面周期管理,包括搜索、下载、卸载等。kubectl 其工具已经比较完善,但是对于一些个性化的命令,其宗旨是希望开发者能以独立而紧张形式发布自定义的kubectl子命令,插件的开发语言不限,需要将最终的脚步或二进制可执行程序以`kubectl-` 的前缀命名,然后放到PATH中即可,可以使用`kubectl plugin list`查看目前已经安装的插件。### 2.4 Github发布相关工具* Github Action如果你需要某个...
