K-means聚类中,我需要对具有数值的分类变量进行缩放吗?
 社区干货
社区干货
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
对我而言,最高兴的就是**新冠疫情**已经不是那么可怕了,大家不需要再担心天天怎么去排队做核酸了,哈哈......,相信你也有同感吧!**同时也见证了足球史上非常伟大的一幕,梅老板终于圆梦,举起了期盼已久的大力神杯**,... 例如docker stop 或者 docker-compose down , docker stop 也可能会出 137 的exit code (当程序不恰当处理SIGTERM错误)> 后面我没就通过以上的这些exit code的分类和归纳,就像相应的问题处理。在这里无论是137、...
【Flocking算法】海王的鱼塘是怎样炼成的 | 社区征文
变量neighborDistance,这个是聚合的距离。假如两只鱼之间的距离<=neighborDistance,那么它就属于这个集群,我们要想办法把这只鱼加到集群里面来。那如何让加入的鱼满足整体,不至于脱离呢?这时候就需要鱼群的中心位... 直到我将目标移出柱子,鱼群才开始远离。## 九、总结Flocking算法是群居动物的合作行为,通过个体间的相互作用实现整体的目标。本文实现的只是一个简单的🐟集群模拟,仅仅是模式识别领域数据聚类的一个算法分支,...
【MindStudio训练营第一季】基于MindX的U-Net网络的工业质检实践作业
Atlas 200 AI加速模块具有极致性能、超低功耗的特点,可以在端侧实现物体识别、图像分类等;Atlas 300I推理卡提供超强AI推理性能,以超强算力加速应用,可广泛应用于推理场景。在软件方面,为了帮助开发者跨越AI应用落... 开发者只需根据自身场景需要,按需下载即可;最后是面向行业应用的SDK,华为已经在昇腾社区发布了面向智能制造场景的mxManufacture SDK和mxVision SDK,聚焦于工业质检场景,能够以很少的代码量、甚至于零代码完成制造行...
【MindStudio训练营第一季】基于U-Net网络的图像分割的MindStudio实践
或过程数据(如缩放后的图像)。> MindX SDK基础概念介绍:" || { warn "Failed to check path/to/run.sh" ; exit ; } ; pwd)...
 特惠活动
特惠活动
 K-means聚类中,我需要对具有数值的分类变量进行缩放吗?
-优选内容
K-means聚类中,我需要对具有数值的分类变量进行缩放吗?
-优选内容
 K-means聚类中,我需要对具有数值的分类变量进行缩放吗?
-相关内容
K-means聚类中,我需要对具有数值的分类变量进行缩放吗?
-相关内容
居家办公更要高效 - 自动化办公完美提升摸鱼时间 | 社区征文
有时候需要给大量数据做分析,要对 excel 表格和 csv 中数据整理操作必不可少。所以,作为爱动手的程序猿怎么能放过炫技的时刻呢。能用代码批量解决的绝不操作两次,神器在手,天下我有,代码一粘,两手一摊,一劳永逸。... # 每个尺寸的缩放系数为8,这将为我们生成分辨率提高64倍的图像。 zoom_x = 8.0 zoom_y = 8.0 trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate) pm = page.getPixmap(matrix=trans, alpha=False) ...
数字大屏-堆叠条形图
堆叠条形图是一种以条形的长度为变量来展示数据的统计图,通常用来表示数据在不同时间或者不同条件下的变化。堆叠条形图支持用户将数据在数字大屏中进行堆叠显示。 2. 快速入门 选择组件-图表中的堆叠条形图,大屏中心将出现一个堆叠条形图组件。 在底部查询栏中的数据可视化中选择数据来源,并配置轴、分拆等字段。 配置堆叠条形图样式。 在大屏上拖动堆叠条形图调整位置,缩放堆叠条形图调整大小。 3. 功能介绍 3.1 样式-整体视...
AI 和机器学习:探索智能科技的未来 | 社区征文
AI技术的目标之一是通过创建具有人类智能特征的系统来解决复杂问题。而机器学习(Machine Learning)是AI的一个分支。它通过分析数据来教会计算机学习而不通过明确编程。通过例如聚类、分类和回归等算法从示例数据中... from sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score# 加载生产设备数据data = pd.read_csv('production_data.csv')# 准备特征和目标变量X = data.drop('main...
【AI人工智能】手把手教你,如何训练专属于自己的私人影院推荐助手
训练模型时并不需要用到,故不必加入output_list logid = line[0].strip().split(":")[1] time = line[1].strip().split(":")[1] ... 针对一些比较复杂的网络结构,可以使用Layer子类定义的方式来进行模型代码编写,在__init__构造函数中进行组网Layer的声明,#在forward中使用声明的Layer变量进行前向计算。子类组网方式也可以实现sublayer的复用,针...
[数据库论文研读] HTAP行列混存 & 智能转换
NSM对write-only的workload比较友好,因为每插入一行,就相当于在一个连续空间的末尾顺序写入所有数据,但是对read-only的workload比较不友好,特别是不需要读所有列的时候,相当于做大量的随机读。### DSM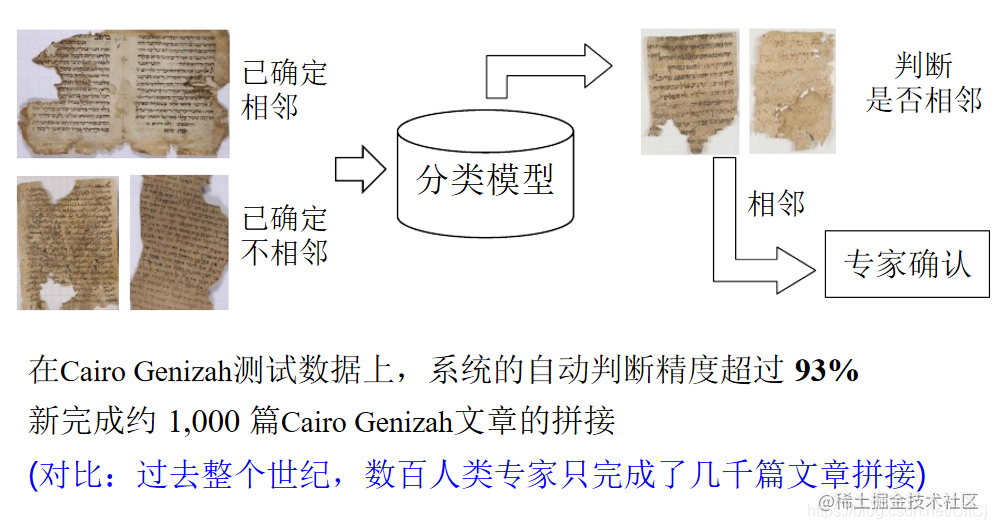回归、分类、聚类是机器学习最常见的三大任务。回归是一种数学模型,利用数据统计原理,对大量统计数据进行数学处理,确定因变量与某些自...
关于对Stable Diffusion 模型性能优化方案分享 主赛道 | 社区征文
具有在生成图像任务中表现出色的潜力。然而,在实际部署中,要确保模型在端侧设备上的高效运行,需要面对一系列挑战,包括性能瓶颈和资源利用率。通过模型优化方案,参赛者将深入挖掘Stable Diffusion技术的性能潜力,结... 配合Conditioning的DM产生新的变量,再通过VAE将生成的变量转换为图片**。例如赛题要求:1. Prompt输入:"a photo of an astronaut riding a horse on mars" 1. Negative Prompt输入:"low resolution, blurry...
浅谈AI机器学习及实践总结 | 社区征文
选择最准确的函数去描述数据集中自变量X1,X2....Xn 和因变量Y之间的因果关系。这个过程就称之为机器学习的训练也叫拟合。这里还需要明确几个概念,训练集、验证集、测试集训练集,最开始用来训练的数据集被称为训... 主要分类是根据机器学习在训练过程中是否有标签。- 监督学习:训练的数据集全部都有标签,根据标签的特点 监督学习可以分为两类问题:回归和分类,回归问题的标签是连续的数值,比如预测房价、股市等,分类问题的标签...
火山引擎在机器写作和机器翻译方面的最新进展
比如说这样一个句子的 The quick brown fox jumps over the lazy dog 句号,这里有 10 个字符,Modeling 的问题就是对这 10 个字符的联合概率去建模,也就任意一个句子长度为 L 的句子,我需要对整个 L 各字符对它算出... 在显式密度中另外一块是不可高效计算的密度(Intractable Density),也是今天需要重点介绍的一类模型,叫隐变量模型(Latent Variable Model),典型的代表有 DSSVAE、VTM 等,本场讲座也将会介绍。 假如说这个密度没有...
