p104支持cuda吗
 社区干货
社区干货
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 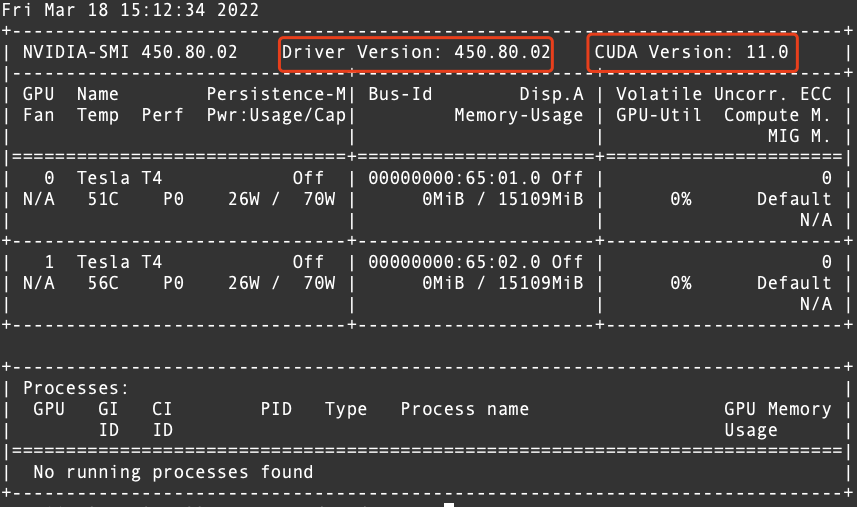 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
AI ASIC 的基准测试、优化和生态系统协作的整合|KubeCon China
而且支持相应的维度越界检查。除了 -1 轴之外,其他维度支持任意 stride 访存,此外,GEMM、TPC、DMA 的指令序列是独立的,pipeline 运行时是 latency 会被隐藏起来。此外,TPC 也添加了 AI 负载常见的激活函数,作为... 而各家 ASIC 由于具备类似 CUDA 的开发生态,往往都需要单独适配,且各家 ASIC 往往都会自带一套自身的软件栈,从使用方式,硬件管理,监控接入等层面,都需要额外开发。这些相比沿用 GPU,都是额外成本。...
GPU推理服务性能优化之路
典型的CUDA代码执行流程:a.将数据从Host端copy到Device端。b.在Device上执行kernel。c.将结果从Device段copy到Host端。以上流程也是模型在GPU推理的过程。在执行的过程中还需要绑定CUDA Stream,以流的形式执行。## 2.2 传统Python推理服务瓶颈## 2.2.1 传统Python推理服务架构由于Python在神经网络训练与推理领域提供了丰富的库支持,加上Python语言自身的便利性,所以推理服务大多用Python实现。CV算法的推理引擎大...
GPU在Kubernetes中的使用与管理 | 社区征文
Kubernetes要想挨个支持是不现实的,所以Kubernetes就把这些硬件加速设备统一当做`扩展资源`来处理。Kubernetes在Pod的API对象里并没有提供像CPU那样的资源类型,它使用我们刚说到的`扩展资源`资源字段来传递GPU信息,下面是官方给出的声明使用nvidia硬件的示例:```apiVersion: v1kind: Podmetadata: name: cuda-vector-addspec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https:...
 特惠活动
特惠活动
 p104支持cuda吗-优选内容
p104支持cuda吗-优选内容
 p104支持cuda吗-相关内容
p104支持cuda吗-相关内容
预置镜像列表
CUDA平台提供的 CUDA 镜像基于 nvidia/cuda 系列镜像构建,提供的 CUDA 版本包括 11.7.0、11.6.0、11.3.0、11.1.1。 内含 GPU 加速工具库、编译器、开发工具和 CUDA 运行时环境,适合通用的高性能计算场景。 镜像的主要特性: 支持平台的高性能网络基础设施,提供了 nccl-tests 用于测试。 支持不同版本的 Python ,涵盖 3.7 到 3.10 。 内置常用开发工具,如 git, rclone, vim 。 pip 、 conda 和 apt 使用国内镜像源。 内置 CUDNN 8...
AI ASIC 的基准测试、优化和生态系统协作的整合|KubeCon China
而且支持相应的维度越界检查。除了 -1 轴之外,其他维度支持任意 stride 访存,此外,GEMM、TPC、DMA 的指令序列是独立的,pipeline 运行时是 latency 会被隐藏起来。此外,TPC 也添加了 AI 负载常见的激活函数,作为... 而各家 ASIC 由于具备类似 CUDA 的开发生态,往往都需要单独适配,且各家 ASIC 往往都会自带一套自身的软件栈,从使用方式,硬件管理,监控接入等层面,都需要额外开发。这些相比沿用 GPU,都是额外成本。...
GPU实例部署paddlepaddle-gpu环境
本文介绍 GPU 实例部署深度学习Paddle环境。 前言 在ECS GPU实例上部署深度学习Paddle环境。 关于实验 预计实验时间:20分钟级别:初级相关产品:ECS受众: 通用 环境说明 本文测试规格如下:实例规格:ecs.pni2.3xlargeGPU 类型:Tesla A100 80G显存容量:81920MiB实例镜像:velinux - 1.0 with GPU DriverNVIDIA-SMI:470.57.02NVIDIA Driver version:470.57.02CUDA version:11.4CUDA Toolkit version:11.2Python version:Python 3.7.3pa...
GPU-部署Baichuan大语言模型
模型支持FP16、INT8、INT4三种精度,可以在GPU实例上部署并搭建推理应用。该模型对GPU显存的需求如下: 精度 显存需求 推荐实例规格 GPU显卡类型 FP16 27 GB ecs.g1ve.2xlarge V100 * 1(单卡32 GB显存) INT8 17 GB ecs.gni2.3xlarge A10 * 1(单卡24 GB显存) INT4 10 GB ecs.gni2.3xlarge A10 * 1(单卡24 GB显存) 软件要求注意 部署Baichuan大语言模型时,需保证CUDA版本 ≥ 11.8。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。...
GPU推理服务性能优化之路
典型的CUDA代码执行流程:a.将数据从Host端copy到Device端。b.在Device上执行kernel。c.将结果从Device段copy到Host端。以上流程也是模型在GPU推理的过程。在执行的过程中还需要绑定CUDA Stream,以流的形式执行。## 2.2 传统Python推理服务瓶颈## 2.2.1 传统Python推理服务架构由于Python在神经网络训练与推理领域提供了丰富的库支持,加上Python语言自身的便利性,所以推理服务大多用Python实现。CV算法的推理引擎大...
VirtualBox制作ubuntu14镜像
实验介绍CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。 Pytorch使... 其他根据自己需求选择 根据需要选择 步骤三:设置ssh远程登录由于VirtualBox不支持鼠标,也不知道快捷键复制粘贴,为了方便后续操作,推荐ssh登录远程虚拟机 选择虚拟机,选择“设置” 选择网络,点击“高级” 选择...
GPU在Kubernetes中的使用与管理 | 社区征文
Kubernetes要想挨个支持是不现实的,所以Kubernetes就把这些硬件加速设备统一当做`扩展资源`来处理。Kubernetes在Pod的API对象里并没有提供像CPU那样的资源类型,它使用我们刚说到的`扩展资源`资源字段来传递GPU信息,下面是官方给出的声明使用nvidia硬件的示例:```apiVersion: v1kind: Podmetadata: name: cuda-vector-addspec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https:...
探索大模型知识库:技术学习与个人成长分享 | 社区征文
以支持多样性的关系和属性。**4.知识补充和更新:** 搭建知识库后,需要持续进行知识的补充和更新。这可以通过自动化的方法,如基于规则或机器学习的实体关系抽取,以及人工审核和编辑来完成。可能遇到的瓶颈问题:... device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)for epoch in range(10): train_loss = train(model, train_loader, criterion, optimizer) test_loss, test_...
从构建到落地,火山方舟助力大模型生态持续繁荣
持续在探索基于NVIDIA新一代硬件支持的可信计算环境、基于联邦学习的数据资产分离等多种方式的安全互信计算方案,以满足大模型在不同业务场景的数据安全要求。NVIDIA开发与技术部亚太区总经理李曦鹏表示,NVIDIA与火山引擎过往合作成果丰硕,共同合作的GPU推理库ByteTransformer在IEEE国际并行和分布式处理大会(IPDPS 2023)上获得最佳论文奖,双方还联合开源了高性能图像处理加速库CV-CUDA,并在大规模稳定训练、多模型混合部署等方面...
