hive数据仓库的用户接口
 社区干货
社区干货
干货 | 看 SparkSQL 如何支撑企业级数仓
> 企业级数仓架构设计与选型的时候需要从开发的便利性、生态、解耦程度、性能、 安全这几个纬度思考。本文作者:惊帆 来自于数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce...
ByConity 技术详解之 Hive 外表和数据湖
随着大数据处理需求的不断增加,更低成本的存储和更统一的分析视角变得愈发重要。数据仓库作为企业核心决策支持系统,如何接入外部数据存储已经是一个技术选型必须考虑的问题。也出于同样的考虑,ByConity 0.2.0 中发布了一系列对接外部存储的能力,初步实现对 Hive 外表及数据湖格式的接入。# 支持 Hive 外表随着企业数据决策的要求越来越高,Hive 数据仓库已成为了许多组织的首选工具之一。通过在查询场景中结合 Hive, ByConity...
Hive SQL 底层执行过程 | 社区征文
第一节先介绍 Hive 底层的整体执行流程,然后第二节介绍执行流程中的 SQL 编译成 MapReduce 的过程,第三节剖析 SQL 编译成 MapReduce 的具体实现原理。### 一、HiveHive是什么?Hive 是数据仓库工具,再具体点就... 我们先来看下 Hive 的底层执行架构图, Hive 的主要组件与 Hadoop 交互的过程: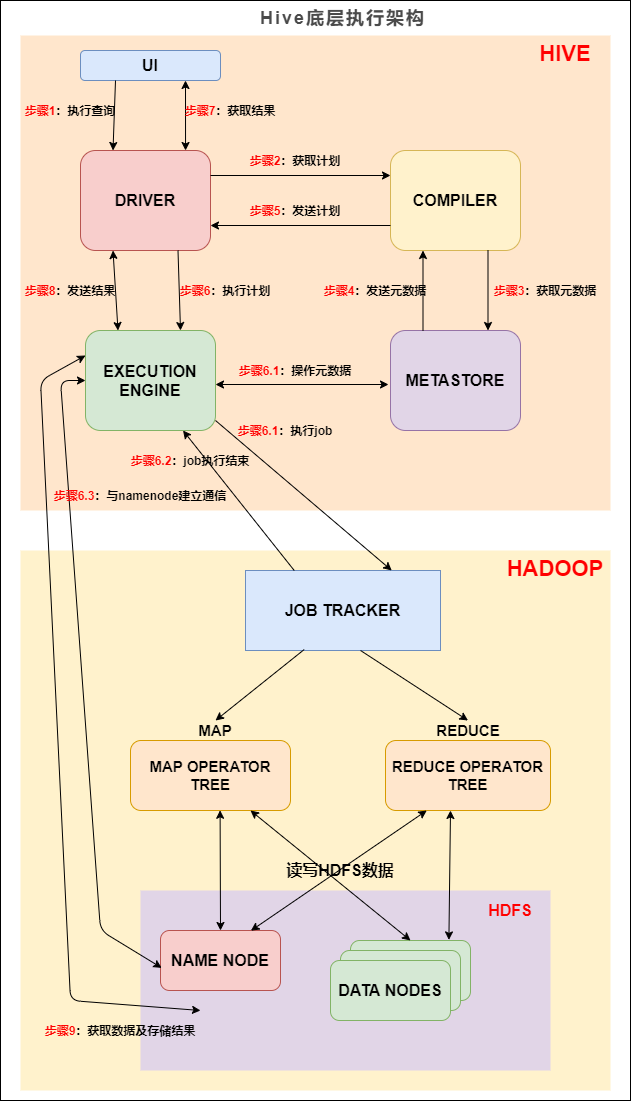在 Hive 这一侧,总共有五个组件:1. UI:用户界面。...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 数据仓库就越好;- 在保证属性列值的质量方面所花的时间越多,数据仓库就越好。> **维度表是进入事实表的入口**丰富的维度属性给出了丰富的分析切割能力。维度给用户提供了使用数据仓库的接口, 最好的属性是文本...
 特惠活动
特惠活动
 hive数据仓库的用户接口-优选内容
hive数据仓库的用户接口-优选内容
 hive数据仓库的用户接口-相关内容
hive数据仓库的用户接口-相关内容
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 数据仓库就越好;- 在保证属性列值的质量方面所花的时间越多,数据仓库就越好。> **维度表是进入事实表的入口**丰富的维度属性给出了丰富的分析切割能力。维度给用户提供了使用数据仓库的接口, 最好的属性是文本...
观点|SparkSQL在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台EMR团队EMR 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式...
SparkSQL 在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及元数据中心...
数据集常见 FAQ
造成数据同步时,类型转换不正常。 解决办法: 修改hive表的字段类型之后,需要重新灌入数据到hive表; 然后到DataWind这边编辑、保存对应的数据集,再重新同步数据。 说明 编辑、保存数据集是用来更新数据集模型中的字段类型,这一步操作会导致类型变更的字段那一列数据丢失,重新同步数据后正常。 kafka 接入数据集报错 OLAP 接口异常可能原因: 字段格式不允许 排查建议: 当前不支持嵌套json,不支持修改map字段列。 如非以上情况,Kaf...
概述
Hive 是一款基于 Hadoop 的数据仓库架构,可以通过 HiveQL(类 SQL 语言)对分布式存储中的大型数据集进行提取、转化和加载(ETL)操作,以及元数据管理。关于Hive的的更多的介绍,可以参考Apache Hive官网。 1 Hive 组件... Hive MetaStore Hive MetaStore 是 Hive 元数据管理模块,该模块将 database、table、column 等元数据信息存储到数据库中。该模块也被Spark引擎所依赖。同时提供 Thrift 接口,供 MetaStroe 客户端直接操作元数据信...
数据集
接口说明本接口可以创建数据集,数据集可以用于任务的输出节点。请求地址 POST https://{domain}/aeolus/prep/userOpenAPI/v1/dataset请求参数 参数名称 类型 默认值 必填 说明 name string 是 appId int 是 项目ID ownerEmailPrefix string 是 用户名 dataSetSourceId int 0 否 数据集来源id, 默认0 clusterName string 是 集群名 dbName string 是 库名 tableName string 是 表名 dataSourceType string 是 hive dataSe...
字节跳动 EMR 产品在 Spark SQL 的优化实践
因此字节EMR产品需要将数据湖引擎集成到Spark SQL中,在这个过程碰到非常多的问题。**首先在与Iceberg集成的时候**,对体验和易用的问题进行了优化,用户在使用Spark SQL过程中,需要手动输入很多指令,并且需要找到对... **兼容Hive语义:** 由于大部分B端客户早期是基于Hive构建的数据仓库,后续逐步全部替换为Spark SQL,中间必然面临大量的系统迁移,而由于Hive与Spark SQL语义不尽相同,重写SQL实现的工作量非常大,因此在字节EMR产...
干货|字节跳动EMR产品在Spark SQL的优化实践
用户在使用Spark SQL过程中,需要手动输入很多指令,并且需要找到对应的spark-iceberg 依赖包,这个也是目前集成Iceberg最常用的方案。**我们的解决方式是在预先安装的过程中,提前把iceberg的相关jar包放到spark jar... 由于大部分B端客户早期是基于Hive构建的数据仓库,后续逐步全部替换为Spark SQL,中间必然面临大量的系统迁移,而由于Hive与Spark SQL语义不尽相同,重写SQL实现的工作量非常大,因此在字节EMR产品中的Spark SQL Server...
干货|字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化(2)
> > > 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务。其中一个典型场景是 Kafka/ByteMQ/RocketMQ -> HDFS/Hive 。Kafka/ByteMQ/RocketMQ... 用户任务配置的并发为 8,也就是说执行过程中有 8 个task在同时执行。 **Flink日志查看**排查过程中,我们首先查看 Flink Job manager 和 Task manager 在 HDFS 故障期间的日志,发现在 Checkpoint id...
