BAT在一段时间内运行Python并在一定时间后终止它。
 社区干货
社区干货
弹性容器实例:基于 Argo Workflows 和 Serverless Kubernetes 搭建精细化用云工作流
它常被用来在 Kubernetes 集群上编排并行工作流,将工作流中的每一个任务实现为一个容器独立运行,具备轻量级、可扩展且易于使用的特点。Argo Workflows 常见于以下应用场景:- **批处理和数据分析**。企业收集... 在企业级场景下,由于可以在短时间内并发执行多个独立的工作流,每条工作流执行中的任务往往完成某一个特定的操作,运行时长变化很大,Argo Workflows 通常对底层容器环境的**资源弹性需求很高**。弹性容器 VCI 具备秒...
Pulsar 在云原生消息引擎领域为何如此流行?| 社区征文
可跨机房在集群间无缝地完成消息复制。 - 极低的发布延迟和端到端延迟。 - 可无缝扩展到超过一百万个 topic。 - 简单的客户端 API,支持 Java、Go、Python 和 C++。 - 主题的多种订阅模式(独占、共享和故障转移... 并在消费者上启用自动重试。当在消费者上启用自动重试时,如果消息没有被消费,则消息将存储在重试主题中,因此消费者在指定的延迟时间后将自动接收来自重试主题的失败消息。默认情况下,不启用自动重试功能。你可以...
字节跳动自研万亿级图数据库 & 图计算实践
生成执行计划;2. 并根据一定的路由规则(例如一致性哈希)找到目标数据所在的存储节点(bgkv),将执行计划中的读写请求发送给 多个 bgkv;3. 将 bgkv 读写结果汇总以及过滤处理,得到最终结果,返回给客户端。**bgd... 如果用批处理系统来运行图算法,就可能会引入大量的 Shuffle 来实现关系的连接,而 Shuffle 是一项很重的操作,不仅会导致任务运行时间长,并且会浪费很多计算资源。**图计算系统**图计算系统是针对图算法的特点...
字节跳动 MapReduce - Spark 平滑迁移实践
近一年内字节跳动 Spark 作业数量经历了从 100 万到 150 万的暴涨,天级数据 Flink Batch 从 20 万涨到了 25 万,而 MapReduce 的用量则处于缓慢下降的状态,一年的时间差不多从 1.4 万降到了 1 万左右,基于以上的用量... 且其中有很多是运行非常久的任务,可能运行了四五年,推动用户主动升级的难度很大。其次,从可行性上而言,有一半以上的作业都是 Hadoop Streaming 作业,包含了 Shell ,Python,甚至 C++ 程序,虽然 Spark 有一个 P...
 特惠活动
特惠活动
 BAT在一段时间内运行Python并在一定时间后终止它。-优选内容
BAT在一段时间内运行Python并在一定时间后终止它。-优选内容
 BAT在一段时间内运行Python并在一定时间后终止它。-相关内容
BAT在一段时间内运行Python并在一定时间后终止它。-相关内容
字节跳动 MapReduce - Spark 平滑迁移实践
近一年内字节跳动 Spark 作业数量经历了从 100 万到 150 万的暴涨,天级数据 Flink Batch 从 20 万涨到了 25 万,而 MapReduce 的用量则处于缓慢下降的状态,一年的时间差不多从 1.4 万降到了 1 万左右,基于以上的用量... 且其中有很多是运行非常久的任务,可能运行了四五年,推动用户主动升级的难度很大。其次,从可行性上而言,有一半以上的作业都是 Hadoop Streaming 作业,包含了 Shell ,Python,甚至 C++ 程序,虽然 Spark 有一个 P...
Flink on K8s 企业生产化实践|社区征文
并被所有Job共享的。Flink任务由Client提交,client做一些预备工作, 并在 Flink Client 上生成 JobGraph,这种方式的缺点是:一个Job导致的JobManager失败可能会导致所有的Job失败。### Per-Job 模式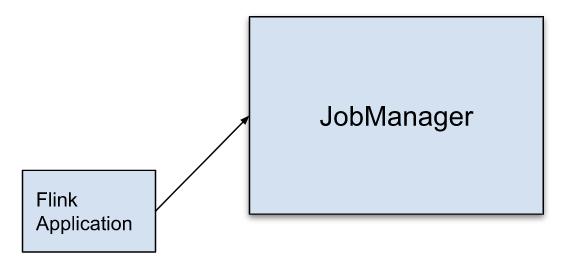*添加描述*为每次 Job 提交启动专用 JM,JM 将**只执行**此作业,然后退出。在 Flink Client 上...
浅谈AI机器学习及实践总结 | 社区征文
能够在浏览器中,通过编写python脚本 运行脚本,在脚本块下方展示运行结果。jupyter notebook 可以交互式的开发,再加上拥有丰富的的文本格式、可以图文并茂的展示结果,迅速的展现数据分析师的想法。## 安装Jupyt... 能帮你管理众多的Python库,支持Jupyter Notebook、Spyder等工具,还有许多科学包,通过可以从官网上直接下载安装Anaconda,启动Anaconda后 安装Juypter就比较简单,直接Anaconda界面上启动就好了,默认Anaconda会安装好...
社区征文|ChatGPT教我如何面试
并发起验证码验证,验证后就可以体验了。当然以上三步的具体操作步骤,网上有比较详细的文章,大家可以参考下。我把当初面试题归类为**技术题、发散题、编程题**三大类:技术题:Java、Python相关、Spring相关、L... ###### Q:Java中什么是内存泄漏?如何避免内存泄露?内存泄漏指的是程序在申请内存后,无法释放已用的内存。这样,随着程序运行的时间的增加,可用的内存会越来越少,最终可能导致程序崩溃。Java中可能导致内存泄漏的...
部署自定义模型
然后再部署对应的模型版本。否则,一体机将无法识别您部署的模型文件,导致模型服务无法正常运行。更多信息,请参见 ONNX 模型文件加密说明。 上传 ONNX 模型密码文件到一体机远程登录您计划部署 ONNX 加密模型文件的... 模型前后处理版本 选择要部署的模型前后处理版本。关于前后处理版本的详细说明,请参见为自定义模型创建版本。 服务配置 服务状态类型 固定为 无服务状态。 最大批处理大小 设置最大批处理数量。取值范围:0...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.06
数据开发:EMR Spark 支持 Python 输出、Shell\Python 任务支持使用独享资源组私有镜像、临时查询支持 EMR StarRocks SQL 查询任务类型、流式任务监控,支持 Webhook 报警方式、实时运维概览,新增任务监控大盘和资源使用分析、FinkSQL 任务新增支持输入参数 - 数据集成:Hive->Doris、LAS->ES、PostgreSQL->Hive、Mongo->Hive、MySQL->EMR StarRocks、PostgreSQL->Doris - 数据地图:支持接入 EMR StarRocks、支...
搭建Llama-2-7b-hf模型进行推理
使得超大模型在CPU上的部署成为可能。此外,xFasterTransformer提供了C++和Python两种API接口,涵盖了从上层到底层的接口调用,易于用户使用并将xFasterTransformer集成到自有业务框架中。更多信息,可查看xFasterTran... 旨在优化和加速深度学习模型的推理和训练。它提供了一系列高效的算法和优化,用于在英特尔处理器(CPU)、图形处理器(GPU)和其他硬件加速器上执行深度学习任务。 操作步骤步骤一:环境准备创建搭载了第5代英特尔®至强...
使用官方模型
模型前后处理版本 选择要部署的模型前后处理版本。关于前后处理版本的详细说明,请参见为模型创建版本。 服务配置 服务状态类型 固定为 无服务状态。 最大批处理大小 设置最大批处理数量。取值范围:0 ~ 100。 HTTP... 内存限额:容器可以使用的最大内存值。单位:MB 或 GB。使用整数表示。取值范围:0MB ~ 128GB。 注意 如果模型服务在 CPU 或内存方面超过限额,容器将会被终止。 高级配置 动态批处理 设置是否开启动态批处理功能。...
KubeCon 2023 | 字节跳动是怎么为 AI 打造云原生基础设施的
在字节跳动,每天都有数千个作业提交到由 KubeRay 创建的 Ray 集群中。通过在长时间运行的集群上调试程序并通过 Ray Job 自定义资源启动常规作业,用户可以从简化的工作流程中获益。同时,高效地管理并发的 Ray 作业面... 在云原生世界中,我们可以使用 Kubernetes 和集群自动缩放器来降低成本。但与微服务不同,批处理作业对集群的弹性要求更高,给集群自动缩放器带来了更多挑战。在我们的场景中,用户将在短时间内创建多达 16,000 个 Pod...
