持续交付
持续交付






- 文档首页
 持续交付用户指南AI 应用Qwen快速部署 Qwen2.5 大模型服务
持续交付用户指南AI 应用Qwen快速部署 Qwen2.5 大模型服务

本文将结合火山引擎 AI 云原生推理套件 AI Cloud Native ServingKit 的能力,介绍如何通过容器服务 VKE、持续交付 CP 等产品快速实现 Qwen2.5-Omni-7B 部署。
背景信息
Qwen2.5-Omni 模型是 Qwen 系列中全新的旗舰级端到端多模态大模型,专为全面的多模式感知设计,无缝处理包括文本、图像、音频和视频在内的各种输入,同时支持流式的文本生成和自然语音合成输出。
使用说明
下文主要介绍测试并验证通过的实践内容,为了获得符合预期的结果,同时符合 使用限制,请按照本文方案(或在本文推荐的资源上)操作。如需替换方案,您可以联系对应的客户经理咨询。
前提条件
容器服务
在容器服务创建容器集群,需要注意以下列举的参数配置,详细的操作说明参见 创建集群。
容器网络模型:选择 VPC-CNI。
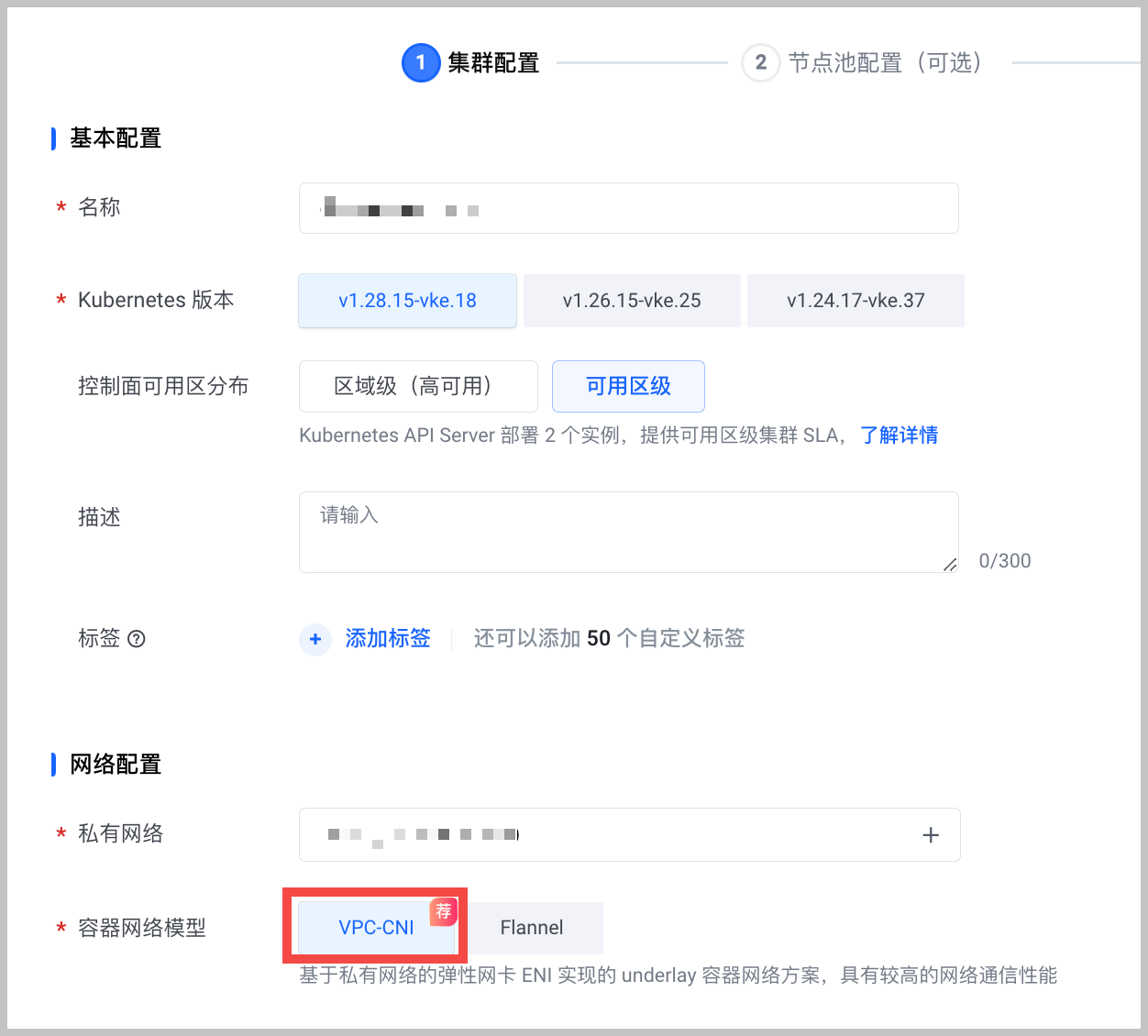
计算规格:
Qwen2.5-Omni-7B参数规模达到 70亿,而且音频、视频处理需要消耗较多的显存。以下是不同视频时长的机型和 GPU 卡数推荐。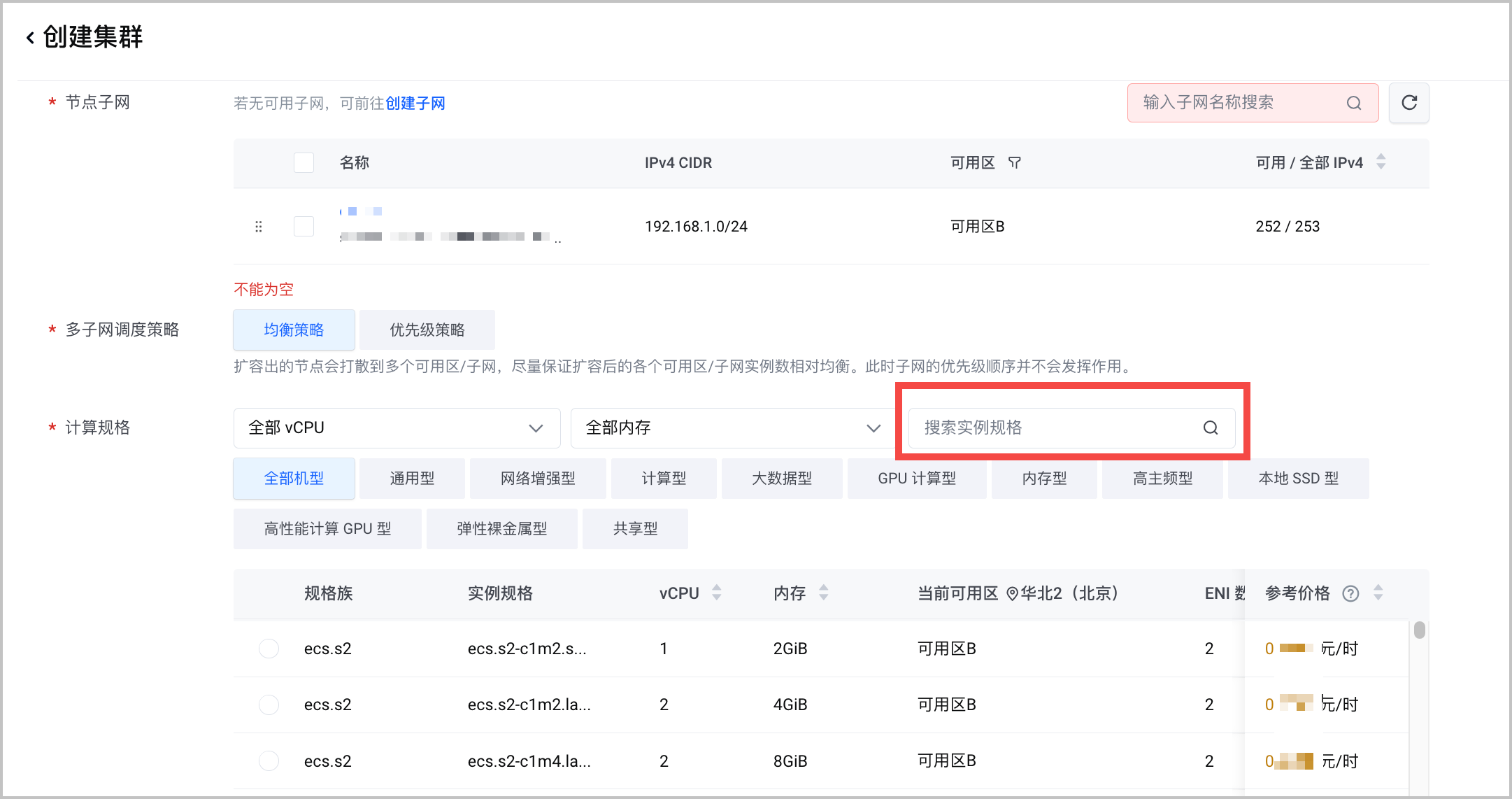
视频时长 推荐机型 推荐显卡数量 15秒 ecs.pni3l.11xlarge 2 30秒 ecs.pni3l.11xlarge 2 60秒 ecs.hpcpni3ln.45xlarge 或 ecs.ebmhpcpni2l.32xlarge 1 组件配置:安装 csi-tos 和 nvidia-device-plugin 两个组件。
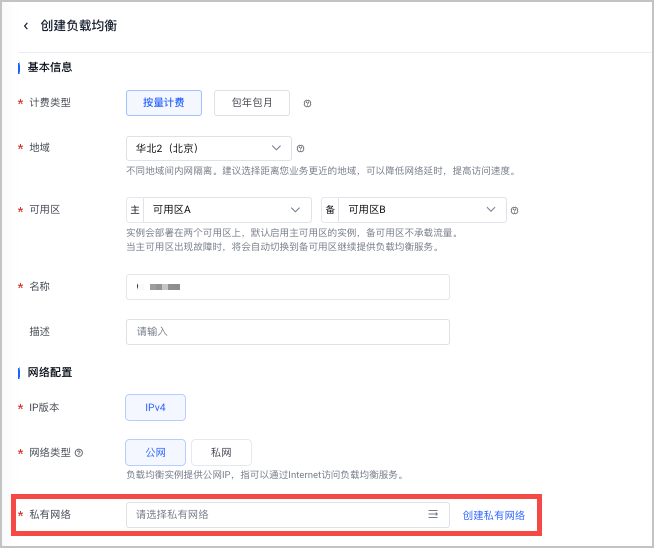
负载均衡
已创建负载均衡网关。 私有网络置必须和所创建 VKE 集群相同。创建负载均衡实例的详细说明参见 创建负载均衡实例。
操作步骤
本文介绍通过火山引擎持续交付产品,完成模型在已创建的容器服务中的快速部署。
第一步:创建部署集群
将已创建的 VKE 集群接入持续交付平台。
登录 持续交付控制台。
在左侧导航栏选择 资源管理。
在资源管理页面,切换至 部署资源 页签。
在 部署资源 页签,单击 创建部署资源 。
在 创建部署资源 对话框,按要求配置部署资源信息。重点注意以下参数配置,其他参数说明参见 接入 VKE 集群。
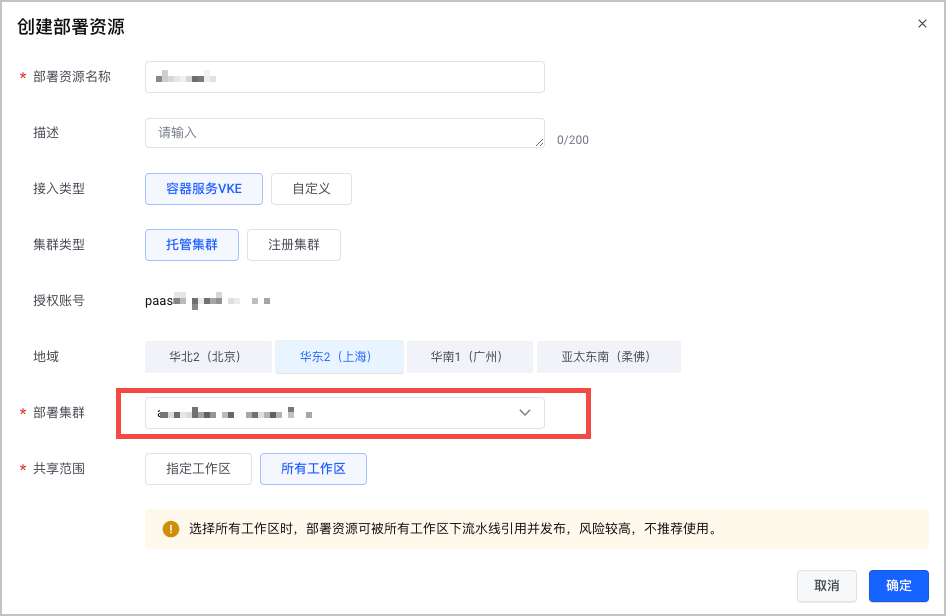
配置项 说明 接入类型 选择 容器服务 VKE。 地域 选择已创建容器服务集群所在的地域。 共享范围 选择 所有工作区。
第二步:创建 AI 应用
在持续交付的 AI 应用 模块,部署大模型应用。
登录 持续交付控制台。
在左侧导航栏选择 AI 应用。
在 AI 应用页面,单击 创建应用。
选择 基于 AI 模型创建 > Qwen2.5-Omni-7B,单击 部署。
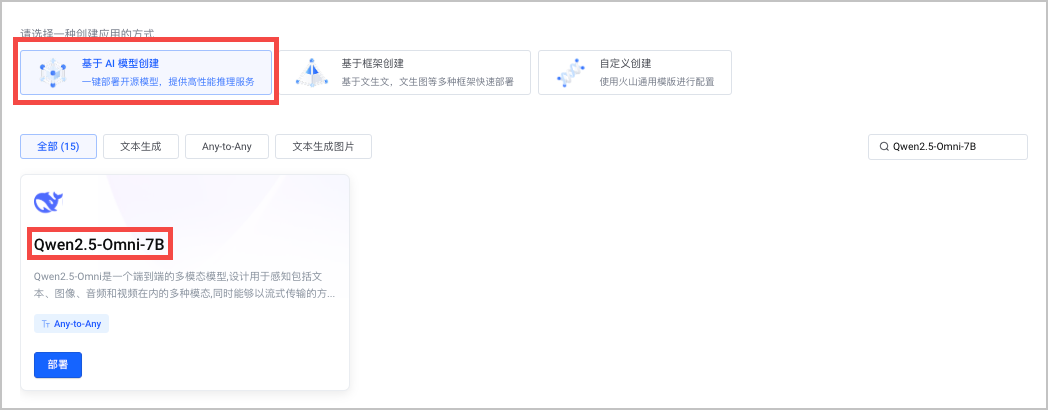
按要求填写应用的相关配置信息。配置完成后单击 创建,应用将开始创建并部署。
基本信息
配置项 说明 应用标识 自定义应用的标识。创建后不可更改。 应用显示名 自定义应用的显示名称。 描述 自定义应用的描述。 部署集群
配置项 说明 部署资源 选择已创建的容器服务集群。 命名空间 选择集群中已创建的命名空间。 环境标识 默认自动生成环境标识,支持自定义修改。本示例暂不开启。 推理服务规格
模型所部署的云服务器规格不同,对应可配置服务规格也有所不同,本示例使用系统默认推荐参数。
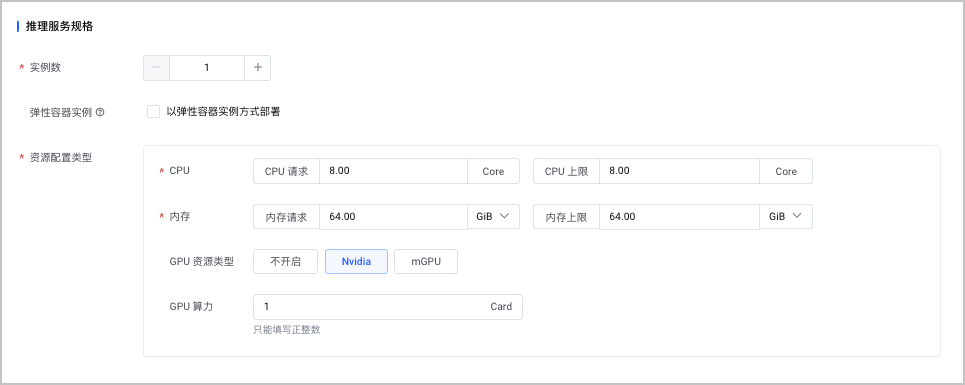
配置项 说明 实例数 选择 1。 弹性容器实例 本示例不选择该功能。 资源配置类型 模型所部署的云服务器规格不同,对应可配置服务规格也有所不同。本示例使用系统默认推荐参数。
第三步:创建负载均衡
火山引擎负载均衡 CLB 是一种将访问流量,按策略分发给多台后端服务器的服务,可以扩展系统对外服务能力,消除单点故障,提高系统的整体可用性。本示例使用负载均衡 CLB 对外暴露服务。
登录当前应用。
- 登录 持续交付控制台。
- 在左侧导航栏选择 AI 应用。
- 在 AI 应用页面,选择目标 AI 应用,单击应用卡片,进入当前应用的基本信息页签。
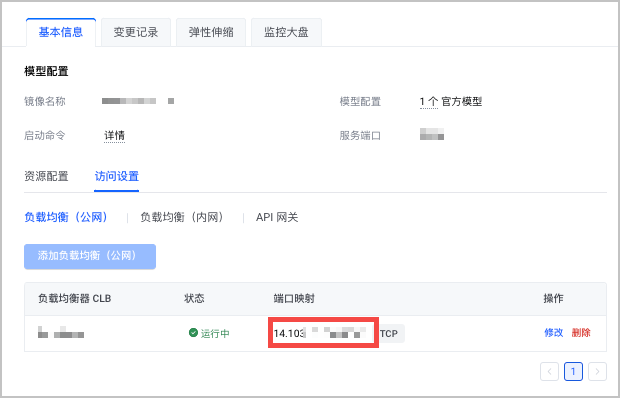
在 基本信息 > 访问设置 页签,选择 负载均衡(公网)。
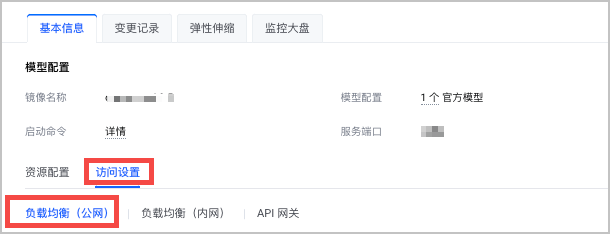
单击 添加负载均衡(公网) ,添加符合 前提条件 要求的负载均衡。
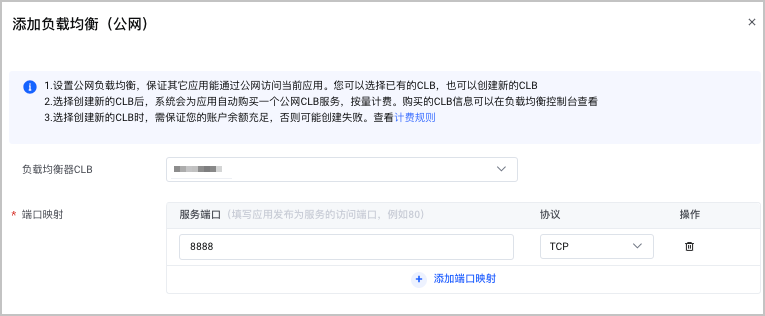
完成上述操作后,即可在 访问设置 页面查看模型的公网 IP 地址。
操作结果
操作完成后可以通过公网 IP 地址在浏览器访问推理服务。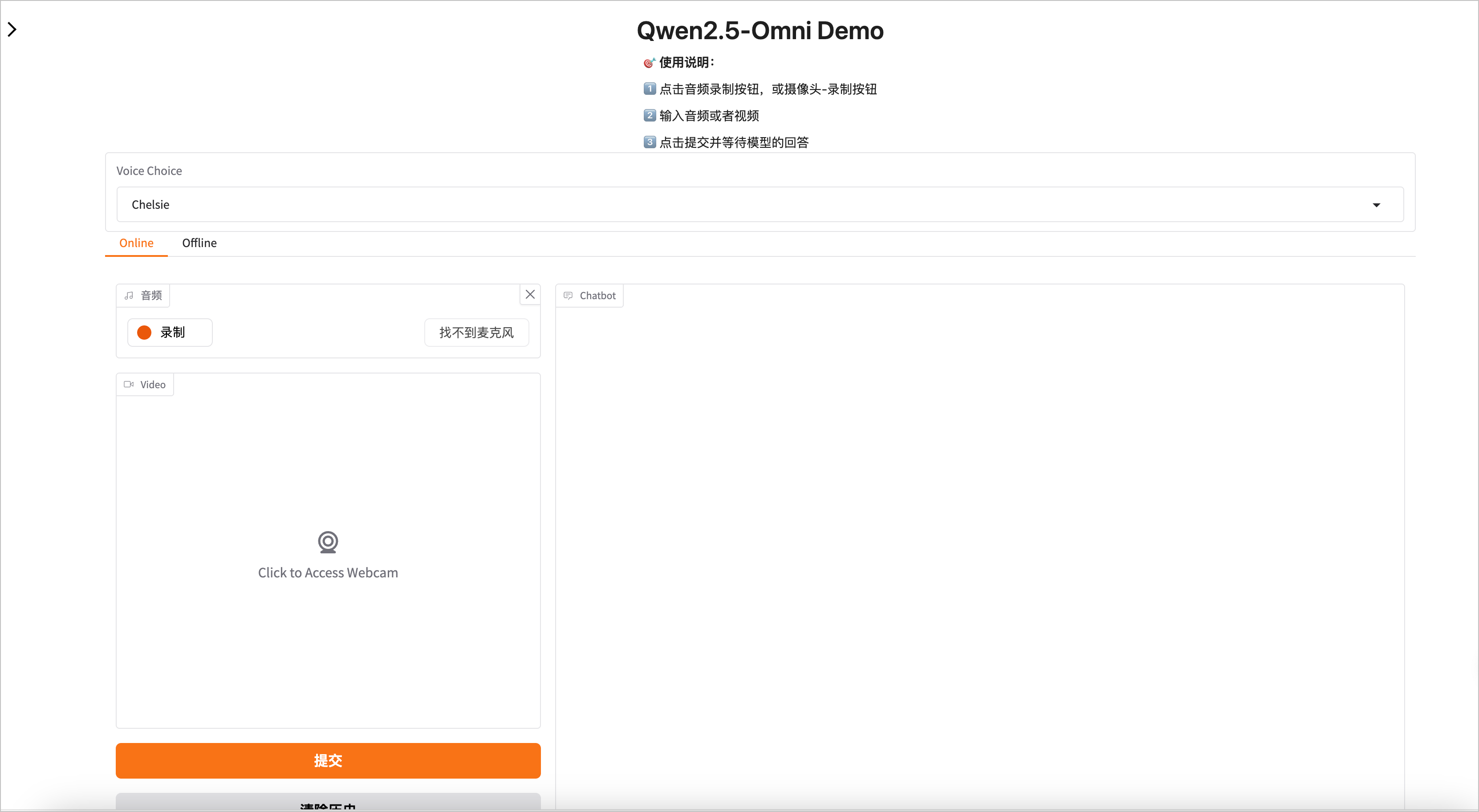
常见问题
摄像头、麦克风使用异常
问题原因
本示例是通过 HTTP(非安全链接)的方式访问的推理服务,由于浏览器的安全设置问题,在使用 摄像头、麦克风的时候可能会遇到image.no_webcam_support 的报错。
解决方案
基于常用的 Chrome 浏览器解决方案如下。
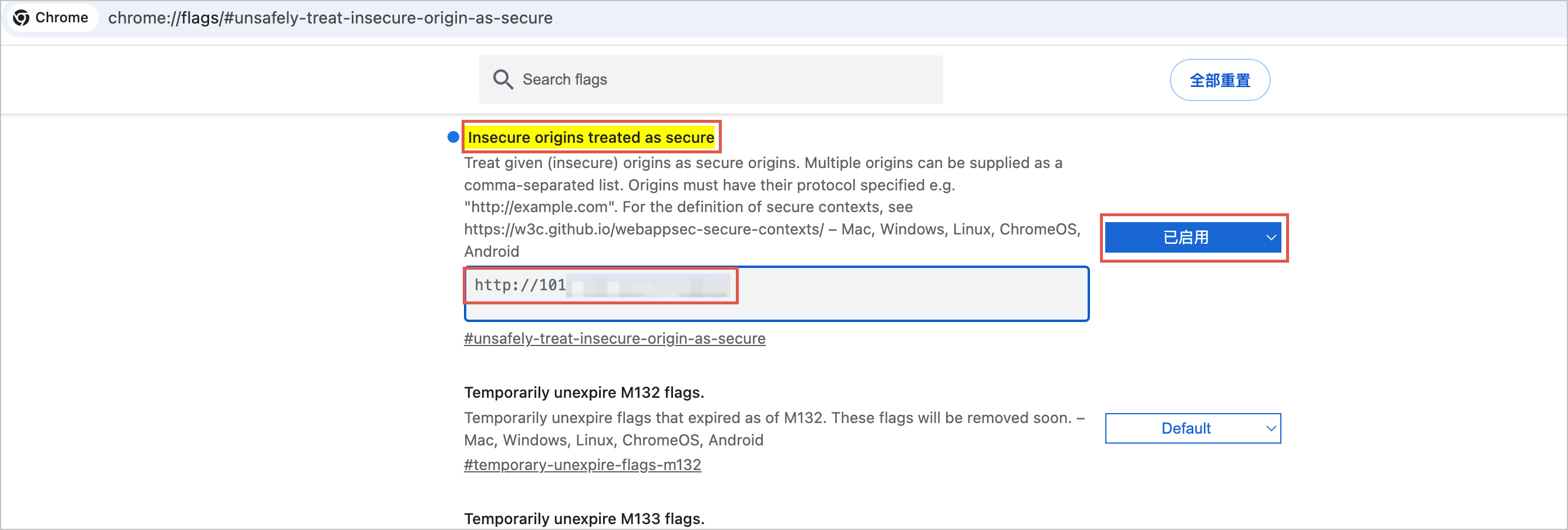
在浏览器页面输入以下地址。
chrome://flags/#unsafely-treat-insecure-origin-as-secure将 Insecure origins treated as secure 配置为 已启用,并且将我们访问推理服务的公网 IP 填入配置中。
重启浏览器。