持续交付
持续交付






- 文档首页
 持续交付用户指南AI 应用Qwen快速部署 Qwen3 大模型推理服务
持续交付用户指南AI 应用Qwen快速部署 Qwen3 大模型推理服务

本文将结合火山引擎 AI 云原生推理套件 AI Cloud Native ServingKit 的能力,介绍如何通过容器服务 VKE、持续交付 CP 等产品快速实现 Qwen3 部署。
背景信息
Qwen3 具备思考和非思考双模式,前者适用于复杂问题求解,后者在简单问答场景表现高效。在多语言处理、推理能力和工具调用方面表现出色,通过智能规划和工具协同,可处理复杂任务。在多个权威基准测试中,Qwen3 成绩优异,能为各行业应用提供有力支持。
使用说明
下文主要介绍测试并验证通过的实践内容,为了获得符合预期的结果,同时符合使用限制,请按照本文方案(或在本文推荐的资源上)操作。如需替换方案,您可以联系对应的客户经理咨询。
前提条件
容器服务
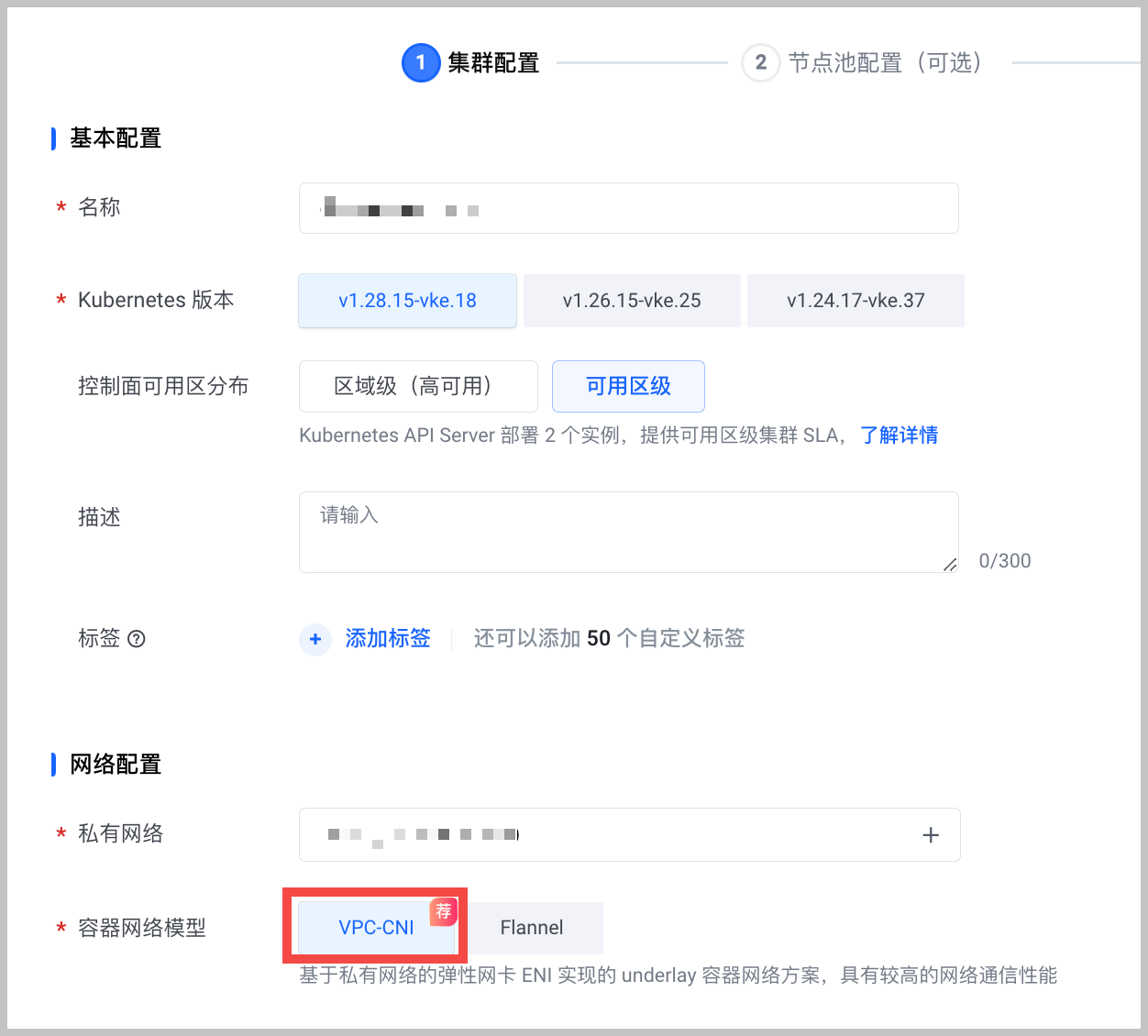
在容器服务创建容器集群,需要注意以下列举的参数配置,详细的操作说明参见 创建集群。
容器网络模型:选择 VPC-CNI。
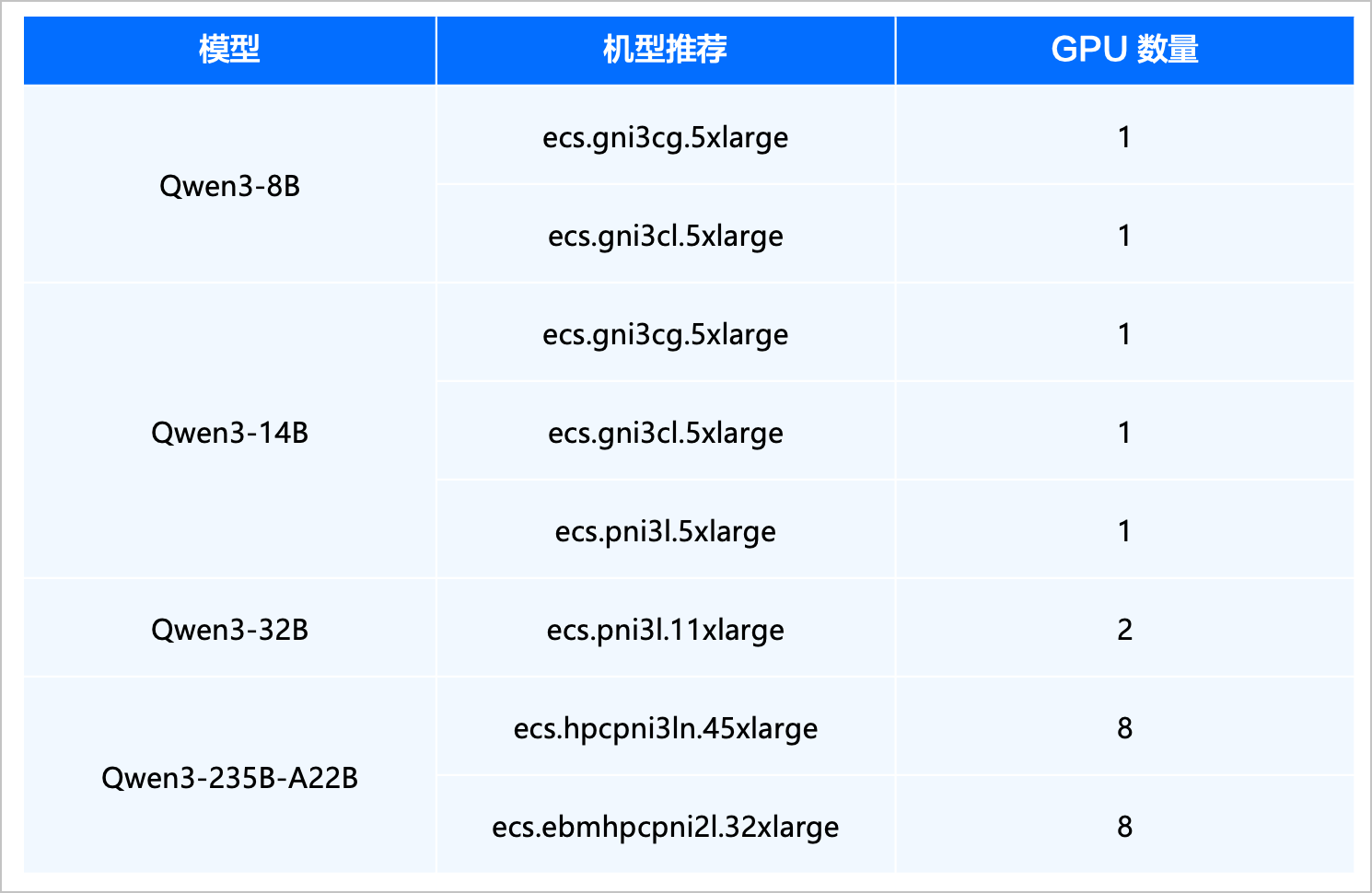
计算规格:推荐使用不同的机型部署不同的模型,以发挥最大性价比。以下为常用的蒸馏模型机型配置推荐,请供参考。
组件配置:安装 csi-tos 和 nvidia-device-plugin 两个组件。
API 网关
已创建 API 网关。 私有网络置必须和所创建 VKE 集群相同。网关节点的规格选择
1c2g 2。协议 为HTTP1.1。创建 API 网关实例的详细说明参见 创建实例。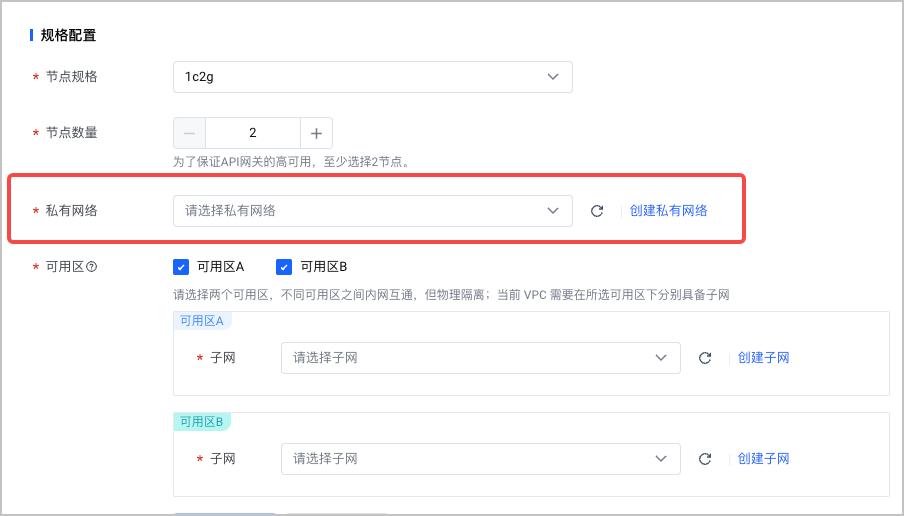
操作步骤
本文介绍通过火山引擎持续交付产品,完成 Qwen3-32B 在已创建的容器服务中的快速部署。
第一步:创建部署集群
将已创建的 VKE 集群接入持续交付平台。
登录 持续交付控制台。
在左侧导航栏选择 资源管理。
在资源管理页面,切换至 部署资源 页签。
在 部署资源 页签,单击 创建部署资源 。
在 创建部署资源 对话框,按要求配置部署资源信息。重点注意以下参数配置,其他参数说明参见 接入 VKE 集群。
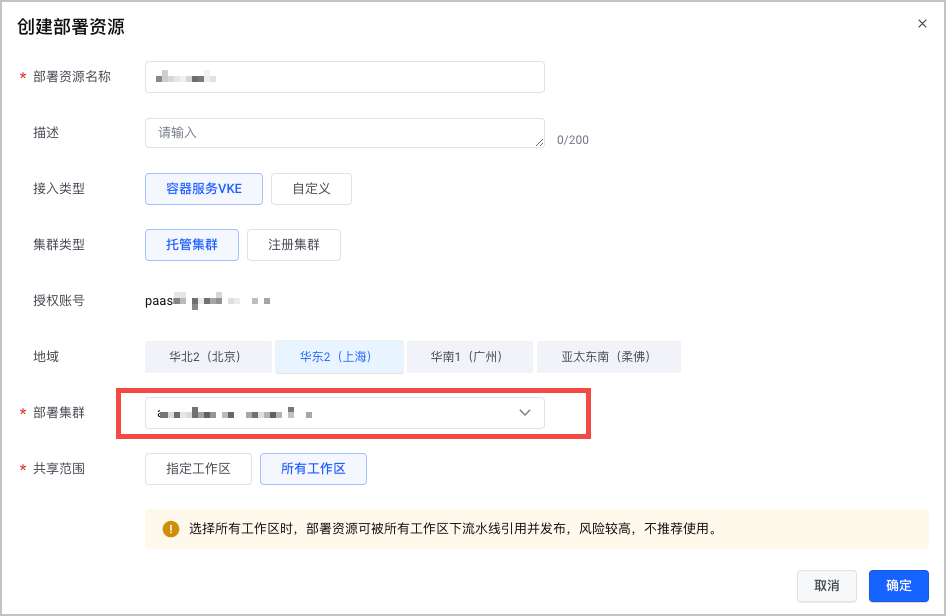
配置项 说明 接入类型 选择 容器服务 VKE。 地域 选择已创建容器服务集群所在的地域。 共享范围 选择 所有工作区。
第二步:创建 AI 应用
在持续交付的 AI 应用 模块,部署大模型应用。
- 登录 持续交付控制台。
- 在左侧导航栏选择 AI 应用。
- 在 AI 应用页面,单击 创建应用。
- 选择 基于 AI 模型创建 > Qwen3-32B,单击 部署。
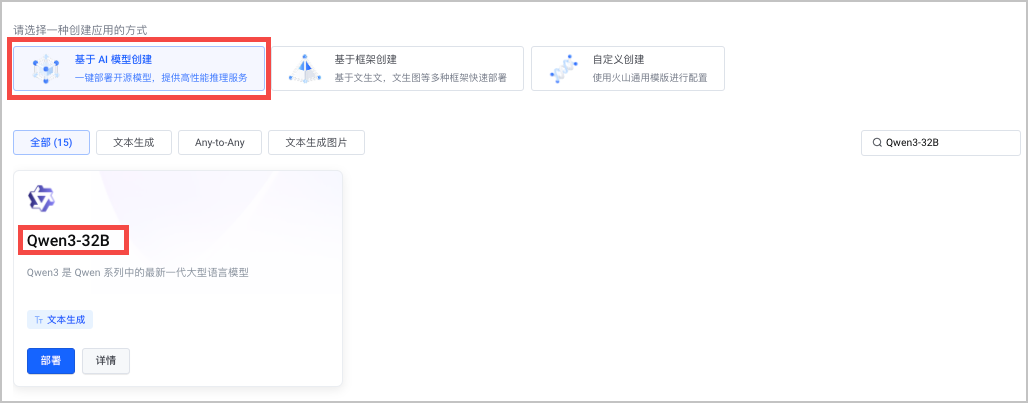
- 按要求填写应用的相关配置信息。配置完成后单击 创建,应用将开始创建并部署。
模型配置
配置项 说明 部署方式 选择 vLLM。 高级配置 支持通过多台主机实现部署分布式推理模型。本示例不开启。 基本信息
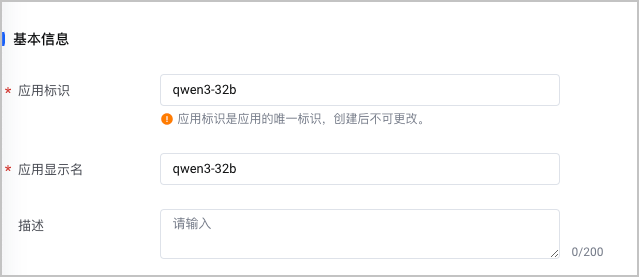
配置项 说明 应用标识 自定义应用的标识。创建后不可更改。 应用显示名 自定义应用的显示名称。 描述 自定义应用的描述。 部署集群
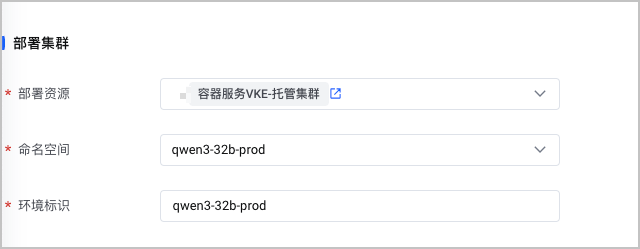
配置项 说明 部署资源 选择已创建的容器服务集群。 命名空间 选择集群中已创建的命名空间。 环境标识 默认自动生成环境标识,支持自定义修改。本示例暂不开启。 推理服务规格
模型所部署的云服务器规格不同,对应可配置服务规格也有所不同。以下是不同机型推荐的服务规格。本文以
ecs.gni3cl.11xlarge为例。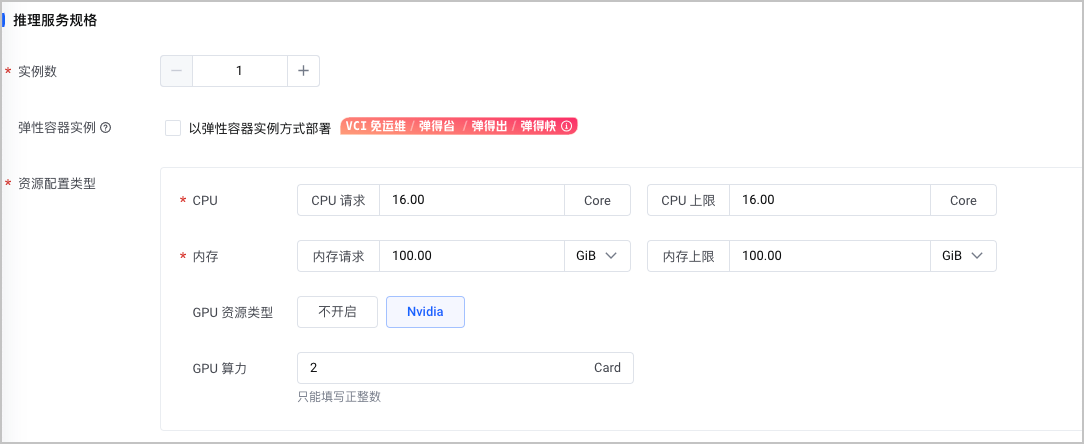
配置项 说明 实例数 选择 1。 弹性容器实例 本示例不选择该功能。 资源配置类型 模型所部署的云服务器规格不同,对应可配置服务规格也有所不同。推荐根据下表,配置对应的服务规格参数。 机器型号 GPU 数量 CPU 请求/上限 内存请求/上限 ecs.gni3cl.11xlarge 2 16 100G
第三步:创建 API 网关访问推理服务
火山引擎 API 网关 APIG 是基于云原生的、高扩展、高可用的云上网关托管服务。在传统流量网关的基础上,集成丰富的服务发现和服务治理能力,打通微服务架构的内外部网络,实现安全通信。
登录当前应用。
- 登录 持续交付控制台。
- 在左侧导航栏选择 AI 应用。
- 在 AI 应用页面,选择目标 AI 应用,单击应用卡片,进入当前应用的基本信息页签。
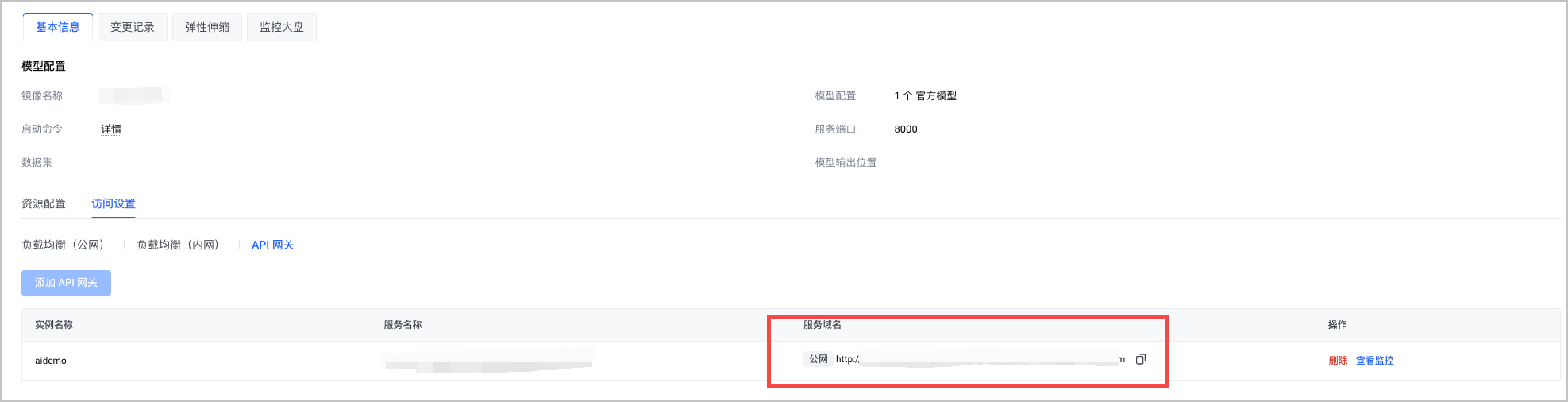
在 基本信息 > 访问设置 页签,选择 API 网关。
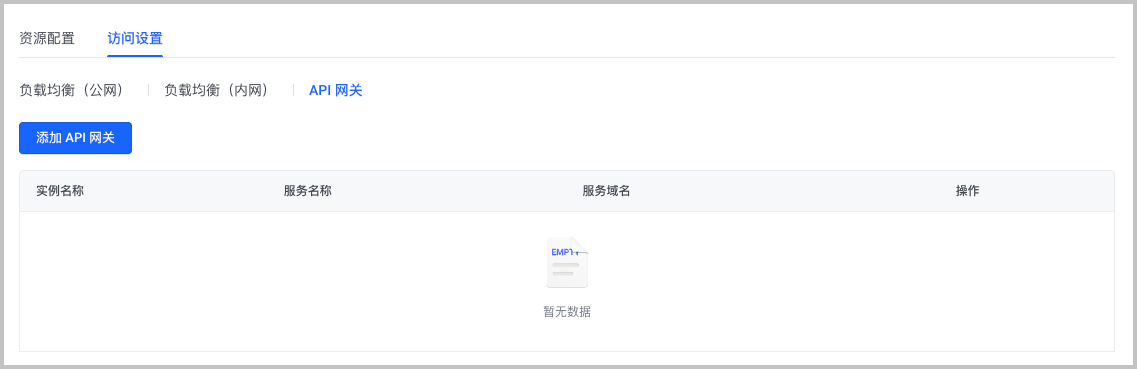
单击 添加 API 网关 ,添加符合 前提条件 要求的 API 网关。
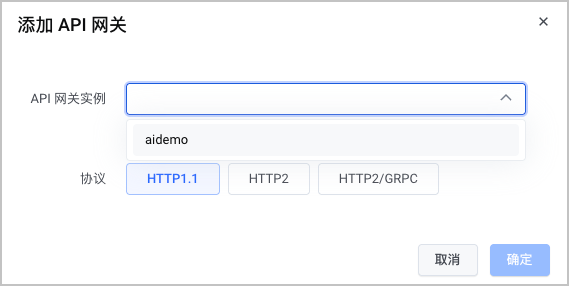
完成上述操作后,即可在 访问设置 页面查看模型的公网域名。
操作结果
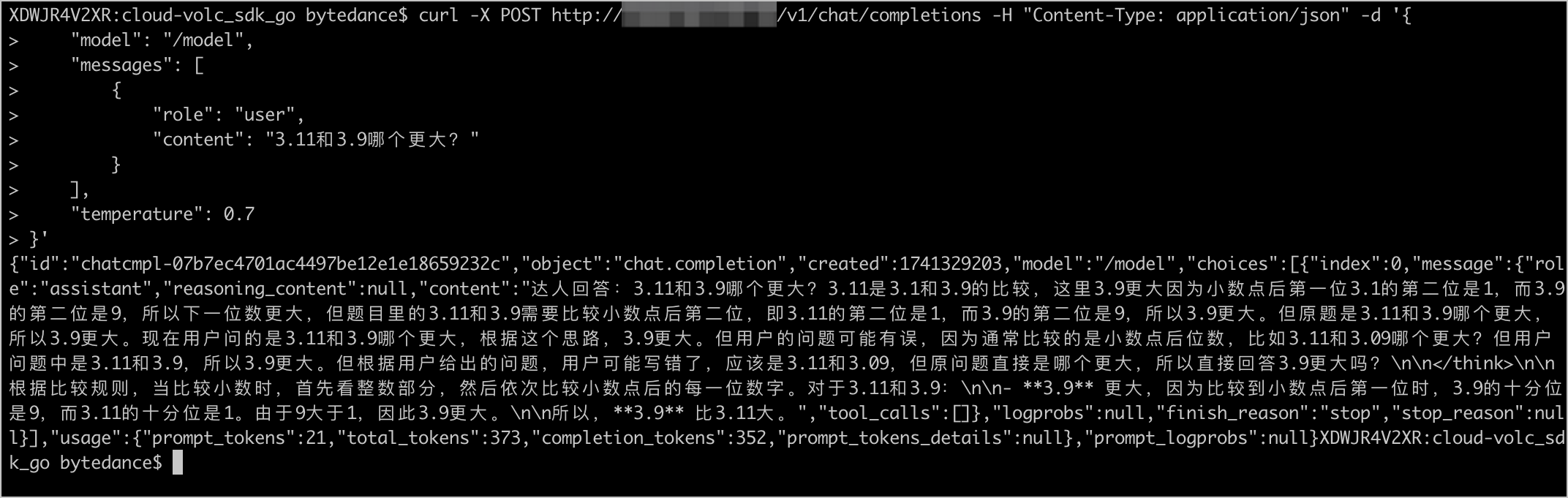
通过本地 curl 命令调用大模型 API,即可以成功和大模型对话。
curl -X POST http://example.com/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "/model", "messages": [ { "role": "user", "content": "你的问题" } ], "temperature": 0.7 }'