与Pandas的约会
 社区干货
社区干货
「火山引擎数据中台产品双月刊」 VOL.07
与原有华北区域组成 2 大服务区域,能更好服务更大范围的客户。 - 数据管理:新增 Table 类型,支持 Hive 内部表类型,开放 WareHouse 文件目录,快速帮助 Hadoop 用户无缝迁移至 LAS。 - 迁移工具:提供 Ha... Pandas on PySpark - Imported Model Support - PyTorch/TensorFlow on PySpark- **弹性** **GPU** **资源** - 基于 Volcano Scheduler 深度优化,支持 GPU 资源调度和按量付费能力...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.07
与原有华北区域组成 2 大服务区域,能更好服务更大范围的客户。 - 数据管理:新增 Table 类型,支持 Hive 内部表类型,开放 WareHouse 文件目录,快速帮助 Hadoop 用户无缝迁移至 LAS。 - 迁移工具:提供 Ha... Pandas on PySpark - Imported Model Support - PyTorch/TensorFlow on PySpark- **弹性** **GPU** **资源** - 基于 Volcano Scheduler 深度优化,支持 GPU 资源调度和按量付费能力...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和回填特征。本文将介绍字节跳动如何通过 Iceberg 数据湖支持... Pandas 等接口。设备的普及和近年来5G网络的异军突起,数据量更是呈显出爆炸性的增长,对数据处理的速... 使用数据处理算法对采集的数据进行预处理和清洗,去除噪声和异常值。```import pandas as pd # 读取数据 data = pd.read_csv('patient_data.csv') # 去除异常值 data = data.replace([np.inf, -np.inf],...
 特惠活动
特惠活动
 与Pandas的约会-优选内容
与Pandas的约会-优选内容
 与Pandas的约会-相关内容
与Pandas的约会-相关内容
火山引擎 DataLeap 下 Notebook 系列文章二:技术路线解析
为了和火山引擎 DataLeap 的视觉风格更契合,从 2020 下半年到 2021 年初,团队还针对性地改进了 JupyterLab 的 UI。 另外火山引擎 DataLeap 研发团队还开发了定制的可视化 SDK,使得用户在 Notebook 上计算得到的 Pandas Dataframe 可以接入火山引擎 DataLeap 数据研发已经提供的数据结果分析模块,直接在 Notebook 内部做一些简单的数据探查。 [JupyterHub](https://xie.infoq.cn/link?target=https%3A%2F%2Fjupyterhu...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
Pandas 等接口。其中读时合并和下推过滤在一些训练模型/数据处理中有很多样本是可以跳过和采样的,我们也通过下推过滤减少训练的样本计算量来提速。在支持高速读时合并中支持了内存统...
使用SDK进行数据导出
初始化python import wandbimport pandas as pdproject = "ci" 项目名称id = "run_20230714_bb4b99f4" run_idapi = wandb.TrackingApi() run = api.run(project=project, run_id=i... 与平台界面展示的数据完全一致,但是平台界面为了兼顾前端性能,返回的是经过采样的数据。如果需要看全量数据,需要使用run.scan_history()方法 导出自定义表格数据python >>> table_names = run.list_table_names() ...
保姆级人工智能学习成长路径|社区征文
和论文都是最权威的一手资料。 为了帮助初学者更快的入门,特意将几大学习重点列举如下,从而方便初学者学习:1. Python基础语法(如基本类型、选择循环等语句等)1. Python编程规范1. Python函数1. Python面向对象1. Python异常处理1. Python文件操作1. Python正则表达式1. .... 除此之外,还需要花费一些时间学习机器学习常用的库,比如Numpy(numpy.array的基本操作、Fancy Indexing)、Pandas(Series、Data...
人工智能与教育:机遇与挑战 | 社区征文
和增强他们的工作上下文理解和灵活性:编程需要对问题的上下文有深入理解,并根据需求做出灵活的调整和决策。AI 在这方面的能力仍然有限,很难像人类程序员那样适应不同的情况和变化。社交和合作:程序员常常需要与团队... 在教育领域应用人工智能的项目代码可以根据具体的应用场景和目标而异。以下是一个简单的示例,演示了如何使用 Python 编写一个基于机器学习的学生成绩预测模型。 ```# 导入所需的库import pandas as pdfrom ...
基于 LAS pyspark 的自有 python 工程使用&依赖导入
与打包 python 虚拟环境的方式解决。# 解决方案我们通过案例说明该问题解决方式。(1)打包一个名称为 pythonCode.zip 的工程,里面只包含代码 test.py 代码,test.py 代码内容如下:```python import pandas a... 通过 DataLeap 资源管理上传代码包和虚拟环境包(4)通过如下方式调用步骤1中的代码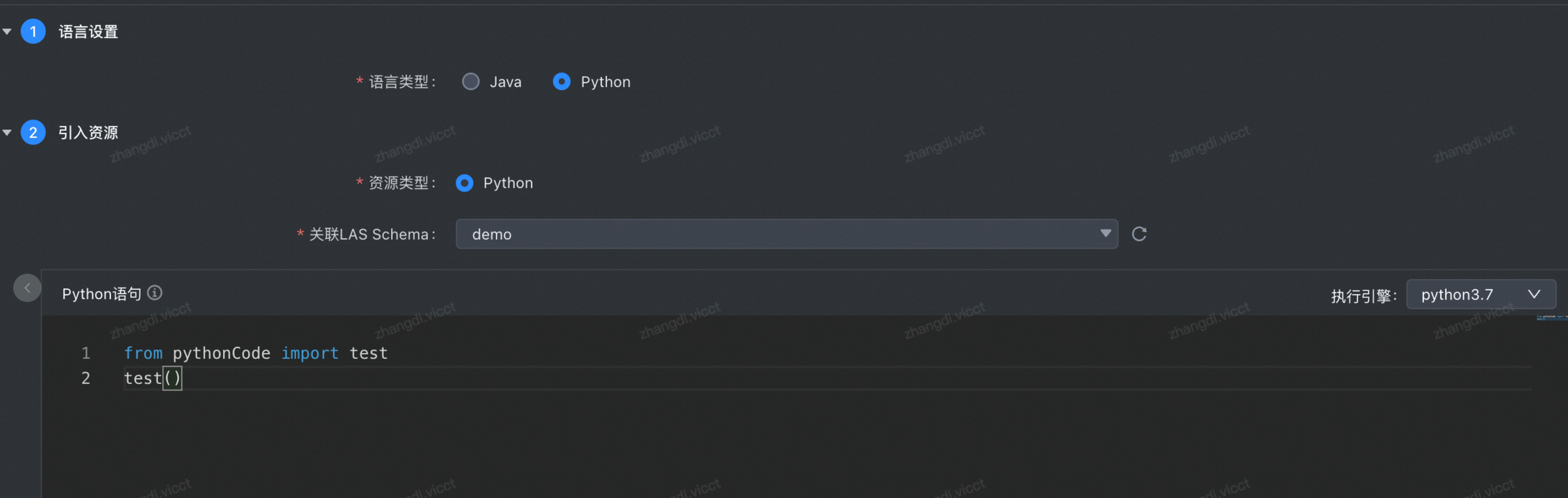> 【说明】...
技术人的 2023 总结:人工智能-基于机器学习的环境污染影响评估学习|社区征文
数据预处理和清洗也显得尤为重要,以确保模型训练的准确性。```import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler# 读取环境数据... 这可以通过绘制预测值和真实值的对比图、特征重要性图等方式来实现。```import matplotlib.pyplot as plt# 绘制预测值与真实值对比图plt.scatter(y_test, y_pred)plt.xlabel('True Values')plt.ylabel('Pr...
基于 ES 的排序学习实践
完成与搜索引擎服务和 LTR 模型工具的交互,灵活性更高。本文主要介绍的是使用开源工具实现排序学习的流程。 步骤一:准备环境登录云搜索服务控制台,然后创建一个 7.10 版本的 ES 实例。 安装 Python Client 依赖。Python pip install -U elasticsearch7==7.10.1 ES数据库相关pip install -U pandas 分析splash的csv 步骤二:准备数据集本文选择使用开源 Metarank 排序工具文档中推荐的 RankLens 数据集,您可以下载 dataset/meta...
基于火山引擎云搜索服务的排序学习实战
> 排序学习(LTR: Learning to Rank)作为一种机器学习技术,其应用场景非常广泛。例如,在**电商推荐**领域,可以帮助电商平台对用户的购买历史、搜索记录、浏览行为等数据进行分析和建模;可以帮助**搜索引擎**对用户的搜索关键词进行分析建模;可以为广告主提供最精准和最有效的**广告投放**方案;在**金融风控**领域,排序学习可以帮助金融机构分析客户的信用评级和欺诈风险,提高风控能力和业务效率。#### 本文相关产品-火山引擎云搜...
