JDBCTemplate在执行查询后关闭预处理语句
 社区干货
社区干货
达梦@记一次国产数据库适配思考过程|社区征文
出现双引号则在实际的sql方言中也需要加上双引号,否则执行sql会抛出视图或表不存在,字段列名不存在的异常。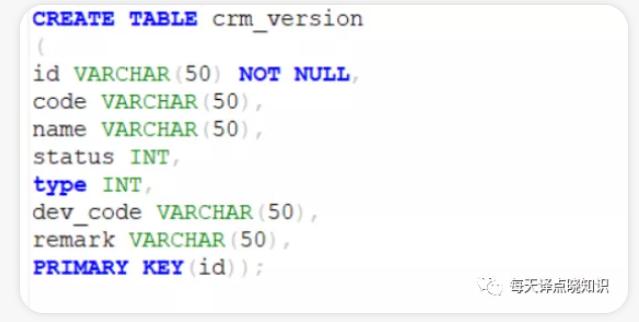若是通过**Mysql或Oracle或其他数据库,文件等方式迁移导入**。这里记录一下迁移过程中遇到的问题,**在迁移的时候,报某些字段超长**。于是,查看了MySql中那些字段的类型及长度,都是varchar(...
弹性容器实例:基于 Argo Workflows 和 Serverless Kubernetes 搭建精细化用云工作流
Argo Workflows 允许开发人员在 Kubernetes 集群中执行批处理的整个过程,周期性自动完成大量重复数据作业的处理;- **AI 模型训练**。模型训练通常都有规范化的流程:数据收集、数据预处理、模型构建、模型编译、... customresourcedefinition.apiextensions.k8s.io/clusterworkflowtemplates.argoproj.io createdcustomresourcedefinition.apiextensions.k8s.io/cronworkflows.argoproj.io createdcustomresourcedefinition.ap...
计算引擎在K8S上的实践|社区征文
template: metadata: labels: app.kubernetes.io/name: spark-thrift-server-test app.kubernetes.io/version: v3.1.1 spec: serviceAccountName: thrift-server hos... Thrift JDBC/ODBC Server - --master - k8s://https://kubernetes.docker.internal:6443 - --name - spark-thriftserver - --conf ...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.09
新增JDBC数据源,String 类型的切分键补充高级参数设置说明 - Oracle源端数据表支持正则表达式配置 - Kafka->LAS实时通道,支持OceanBase SharePlex Json 数据类型- **【** **公... 可以更稳定的运行大查询和ELT任务;大福优化了join/agg spill的性能- VW增强:支持Backup Virtual Warehouse,提升了单VW业务的可用性- 执行计划:支持简化版执行计划(Explain -Simple SQL),不打印节点信息性能...
 特惠活动
特惠活动
 JDBCTemplate在执行查询后关闭预处理语句-优选内容
JDBCTemplate在执行查询后关闭预处理语句-优选内容
 JDBCTemplate在执行查询后关闭预处理语句-相关内容
JDBCTemplate在执行查询后关闭预处理语句-相关内容
DataWind 产品使用问题排查方法
导致现在运行不成功;主要检查原数据集中的字段,是否受到了源头表的改动影响,如字段类型,是否存在,字段名等; 此时查看前台任务的【日志】,往往显示字段解析类的错误,会显示SQL xxxx error的日志内容; 4. 源头上做了迁库,数据源的库类型或者连接的IP+port或JDBC发生了变更;导致数据集同步失败,此时查看前台任务的【日志】,往往显示DataX...Schame..或Access Deniled等字样的,表示获取数据库连接错误或超时之类; 2.4 数据源字段与...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.09
新增JDBC数据源,String 类型的切分键补充高级参数设置说明 - Oracle源端数据表支持正则表达式配置 - Kafka->LAS实时通道,支持OceanBase SharePlex Json 数据类型- **【** **公... 可以更稳定的运行大查询和ELT任务;大福优化了join/agg spill的性能- VW增强:支持Backup Virtual Warehouse,提升了单VW业务的可用性- 执行计划:支持简化版执行计划(Explain -Simple SQL),不打印节点信息性能...
干货 | BitSail Connector 开发详解系列一:Source
不参与作业真正的执行。- SourceSplit: 数据读取分片,大数据处理框架的核心目的就是将大规模的数据拆分成为多个合理的 Split 并行处理。- State:作业状态快照,当开启 checkpoint 之后,会保存当前执行状态。... `*`COLUMNS`*字段在通过这个映射文件转换后才会映射到`TypeInfoConverter`中。##### 示例FileMappingTypeInfoConverter通过 JDBC 方式连接的数据库,包括 MySql、Oracle、SqlServer、Kudu、ClickHouse 等。这...
干货 | BitSail Connector开发详解系列一:Source
不参与作业真正的执行。● **SourceSplit:** 数据读取分片,大数据处理框架的核心目的就是将大规模的数据拆分成为多个合理的Split并行处理。● **State:** 作业状态快照,当开启checkpoint之后,会保存当前执... 字段在通过这个映射文件转换后才会映射到TypeInfoConverter中。 **示例:**###### **1. FileMappingTypeInfoConverter**通过JDBC方式连接的数据库,包括MySql、Oracle、SqlServer、Kudu、...
[BitSail] Connector开发详解系列三:SourceReader
每个SourceReader都在独立的线程中执行,只要我们保证SourceSplitCoordinator分配给不同SourceReader的切片没有交集,在SourceReader的执行周期中,我们就可以不考虑任何有关并发的细节。)); consumer.setConsumerPullTimeoutMillis(pollTimeout); ...
可视化建模 Open API
1.可视化建模 Open API 概述 可视化建模(也称 Prep)提供丰富多样的数据清洗、筛选、聚合、机器学习等算子,支持用户创建任务,进行数据的抽取、转换能力,输出至数据集以供后续的报表制作、可视化查询、数据大屏使用。... "statusDesc": "执行成功", "retryCount": 0, "inputParams": [ { "hasAuth": null, "flowTas...
字节跳动湖平台在批计算和特征场景的实践
表统计信息以及上层查询引擎读取、表写入文件接口等,使得 Spark, Flink 等计算引擎能够同时高效使用相同的表。* 下层有 parquet、orc、avro 等文件格式可供选择* 下接缓存加速层,包括开源的 Alluxio、火山引擎自... 其核心信息是保存 Version 文件所在的目录。+ Iceberg Catalog 共有8种实现方式,包括 HadoopCatalog,HiveCatalog,JDBCCatalog,RestCatalog 等+ 不同的实现方式,其底层存储信息会略有不同;RestCatalog 方式无需对...
技术人年度回顾:大模型驱动的变革与影响|社区征文
如果在医学领域,那么医学文献或文章可以是一个好的数据源。**3.数据预处理:** 对无监督语料进行预处理,使其符合模型的输入格式。这可能包括分词、去除停用词、处理特殊字符等。**4.模型配置:** 根据硬件和数据... 评估效果:** 使用一些验证集或任务来检查模型的性能是否有所提高。**7.模型微调:** 模型经过增强训练,可以将其继续用于特定的下游任务(如文本分类、实体识别)对模型进行微调,以便它能更好地执行这些任务。**8....
字节跳动湖平台在批计算和特征场景的实践
表统计信息以及上层查询引擎读取、表写入文件接口等,使得 Spark, Flink 等计算引擎能够同时高效使用相同的表。- 下层有 parquet、orc、avro 等文件格式可供选择- 下接缓存加速层,包括开源的 Alluxio、火山引... 其核心信息是保存 Version 文件所在的目录。Iceberg Catalog 共有8种实现方式,包括 HadoopCatalog,HiveCatalog,JDBCCatalog,RestCatalog 等不同的实现方式,其底层存储信息会略有不同;RestCatalog 方式无需对接任何...
