聚合阶段不支持: '$bucket'
 社区干货
社区干货
2022技术盘点之平台云原生架构演进之道|社区征文
[](https://kaliarch-bucket-1251990360.cos.ap-beijing.myqcloud.com/blog_img/20221214175511.png)- 接入层:收护边界网络安全,对业务流量及运维支持流量进行安全防护;- 应用层:平台应用采用安全框架,并严格遵... 进行五阶段实施: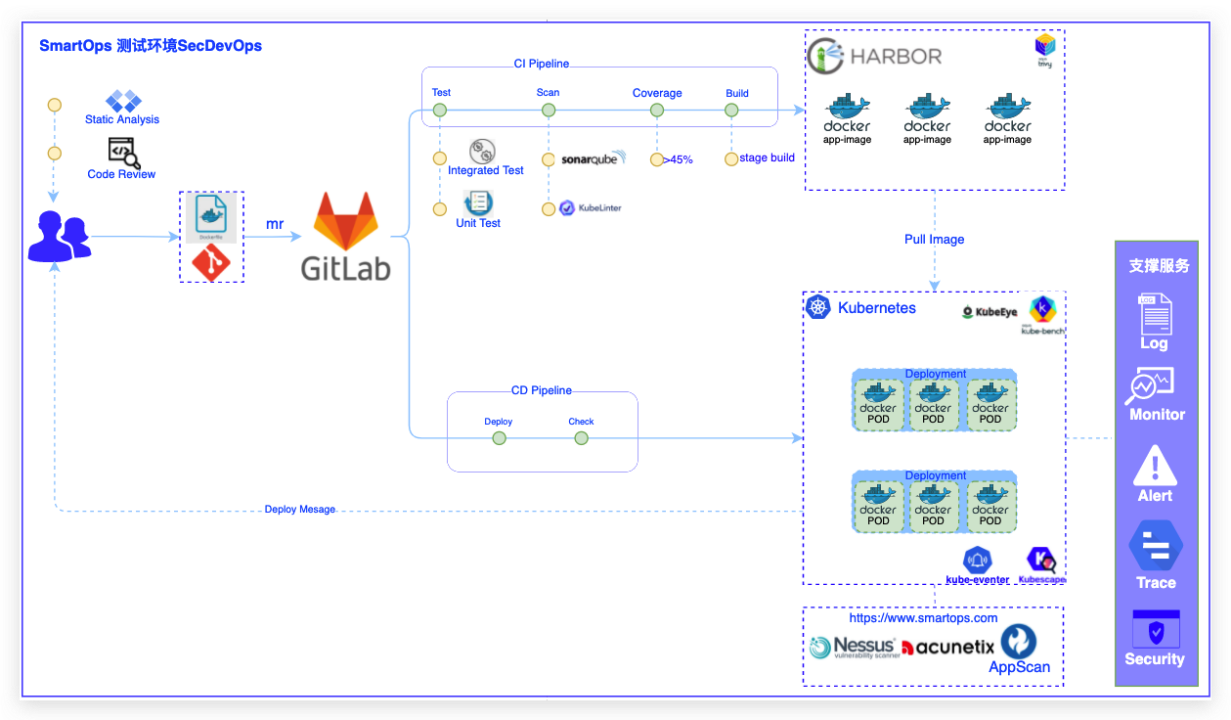- 第一阶段:威胁建模(场景分析)梳理并绘制软件生命周期可能引发安全问题的场景;梳理平台架...
一口气看完43个关于 ElasticSearch 的使用建议
超过百万基数的聚合很容易导致节点内存不够用以至 OOM。`bucket\_sort`使用桶排序算法,性能问题主要是由于它需要在内存中缓存所有的文档和聚合桶,然后才能进行排序和分页,随着文档数量增多和分页深度增加,性能会逐渐变差,有深分页问题。因为桶排序需要对所有文档进行整体排序,所以它的时间复杂度是 O(NlogN),其中 N 是文档总数。目前Elasticsearch支持聚合分页(滚动聚合)的目前只有复合聚合(Composite Aggregation)一种。滚动...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.03
100%开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。## **产品迭代一览** ### **大数据研发治理** **套件*... 兼容多种计算引擎,并能满足数据湖场景下文件级元数据管理的需求。- **Bucket Index**:轻量且高效的索引方式,在大规模数据入湖、探索分析等场景中提供高效的写入和查询能力。- **Column Family**:解决部分列更...
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
此版本尚且没有得到相关的修正且官方不支持修复,只能使用新版本了!2. **【安全问题,以及workaround的问题较多】** 其实新版本与旧版本区别主要在于应用了社区中经过cherrypick挑选出来的PR以及修复了安全性漏洞、... Kubernetes的Yaml文件配置优化阶段- kubernetes的应用故障排查#### 探针经常会无缘无故Killed我们的服务##### 探针的种类- livenessProbe:指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容...
 特惠活动
特惠活动
 聚合阶段不支持: '$bucket'-优选内容
聚合阶段不支持: '$bucket'-优选内容
 聚合阶段不支持: '$bucket'-相关内容
聚合阶段不支持: '$bucket'-相关内容
新功能发布记录
支持云厂商线路并扩展了二级运营商线路 新增云厂商线路(火山引擎、阿里云、华为云、腾讯云、百度云),并在二级运营商线路中新增小运营商聚合、铁通、华通云。 小运营商聚合线路包含除云解析 DNS 支持的二级运营商线... 支持固定 IP 地址接入 您可以使用客户端 SDK 或 HTTP API 通过固定 IP 地址接入移动解析 HTTPDNS 服务端。该功能处于公测阶段。您可以 提交工单 联系我们获取固定 IP 地址。 2023 年 9 月 19 日 全部 导入和初...
干货 | ByteHouse:基于ClickHouse 的实时计算能力升级
同时这个数据量还会不断地增长,2019年,字节内部每天新增的数据量就达到了 100 个TB。其次,在数据量大的基础上,仍要保有包含以下三个方向非常强的灵活性: **●****数据源头的灵活性。**也同时去支持批示数据和流式数据的导入,实现批流一体。**●****查询性能的多样性。**希望同时能够支持到明细数据和聚合查询,不希望在数据库当中只存聚合的数据。**●****交互式分析需求的灵活性。**数千个维度都要能够达到...
干货|火山引擎DataTester:5个优化思路,构建高性能A/B实验平台
如果做一些轻量级聚合把结果做到单表上,性能可以极大提升。也就是把join提前到数据构建阶段,构建好的数据就是join好的数据。* 需要join的场景,则通过减小右表大小来加速查询。因为join的时候会把右表拉到本地构建... 考虑到不同指标配置可能会配置相同的聚合字段、聚合类型,事件名、过滤条件,生成md5的目的是保证唯一防止多次聚合。聚合类型包括count,sum,max,min,latest,distinct(暂不支持),任何算子都可以用这几个基础聚合结果计...
9年演进史:字节跳动 10EB 级大数据存储实战
Append Only 的写入(不支持随机写) - 顺序和随机读 - 超大数据规模 - 易扩展,容错率高## HDFS 在字节跳动的发展字节跳动已经应用 HDFS 非常长的时间了。经历了 9 年的发展,目前已直接支持了十多种数... 兼容了原有 Java 版本 NameNode 的全部功能基础上,大大增强了稳定性和性能。相关详细介绍会在下面的 DanceNN 章节中介绍。### **第三阶段**当数据量跨过 10EB,集群规模扩大到十万+台的时候,慢节点问题,更细粒度...
在大数据量中 Spark 数据倾斜问题定位排查及解决|社区征文
传统的Hive表不支持行级数据操作,粒度都是表级的,如果采用传统Hive表形式,每次对数据进行更新的成本是非常高的,需要全表数据参与,后面经过调研,发现Iceberg是支持行级更新,并且和Spark结合的比较好,经过测试之后发... 在运行时阶段:1. 增加分区数:通过增加分区数来提高并行度,从而减轻数据倾斜的影响。2. 使用聚合操作代替groupByKey:groupByKey操作容易导致数据倾斜,可以尝试使用聚合操作(如reduceByKey、combineByKey)来替代...
LAS Spark 在 TPC-DS 的优化揭秘
指的是在 Spark Optimizer 阶段增加了一些规则来优化逻辑计划。我们常说的谓词下推优化就是 Optimizer 阶段的一条优化规则。#### **3.1.1 Fast Decimal**Decimal 的计算比较耗时,在一些情况下可以把 Decimal 类型先转成 Long 计算,然后再恢复成 Decimal。Spark 现有的优化规则 DecimalAggregates 就是做这样的优化。DecimalAggregates 针对 window/agg 的聚合函数是对 decimal 的 sum/agg 的场景做了如下优化````Sum(e)...
Serverless StarRocks表模型设计
支持追加新数据,不支持修改历史数据。 2.1 适用场景分析原始数据,例如原始日志、原始操作记录等。 查询方式灵活,不需要局限于预聚合的分析方式。 导入日志数据或者时序数据,主要特点是旧数据不会更新,只会追加新... StarRocks 支持在建表和新增分区时自动设置分桶数量 (BUCKETS),您无需手动设置分桶数量。更多信息,请参见 确定分桶数量。 3.4 使用说明排序键的相关说明: 在建表语句中,排序键必须定义在其他列之前。 排序键可以...
DNS 服务观测
该功能目前处于 邀测 阶段,如需使用,请提交申请。 背景信息在大规模场景下时,大量的 DNS 请求会对集群中的 DNS 组件造成较大的压力,导致 DNS 的时延增加,从而影响业务性能。因此,您需要使用集群的可观测能力,及时了解到集群中 DNS 组件的工作状态,并在必要时给出告警和进行处理。 容器服务支持 CoreDNS 组件和 NodeLocal DNSCache 组件。支持标准的集群 DNS 服务发现和节点 DNS 缓存代理功能。涉及的组件包括: core-dns 组件:C...
幸福里基于 Flink & Paimon 的流式数仓实践
围绕这个业务有很多针对 BP 支持的方向,其中最重要的方向之一就是工单系统。工单系统面向的用户是幸福里业务线一线的经纪人和门店经理等。如下图所示,我们可以看下数据是如何通过工单系统产生和流转的。