多模块应用中的Firebase Analytics - 如何实现?
 社区干货
社区干货
干货 | 实时数据湖在字节跳动的实践
不希望感知到数据湖的底层实现细节,数据湖的解决方案应该能够自动地优化数据分布,提供稳定的产品性能。**第三是批流一体的存储。** 数据湖这个技术出现以来,被数仓行业给予了厚望,他们认为数据湖可以最终去解决一... 第一个问题就是分区的元数据是分散在两个系统当中的,缺乏 single source of true。第二个是分区的元数据的获取需要从 HDFS 拉取多个文件,没有办法给出类似于 HMS 这样的秒级访问响应。服务在线的数据应用和开发工具...
借助 MAD 助力你的 Android 应用开发|社区征文
近期我们完成了一款 AI 变脸类应用在 GooglePlay 的上架,此应用可将用户自己的头像图片经算法加工成各种艺术效果。应用一经上架便广受好评,这一切正是得益于我们在项目中对 MAD 技术的综合运用,我们在最短时间内完... 应用情况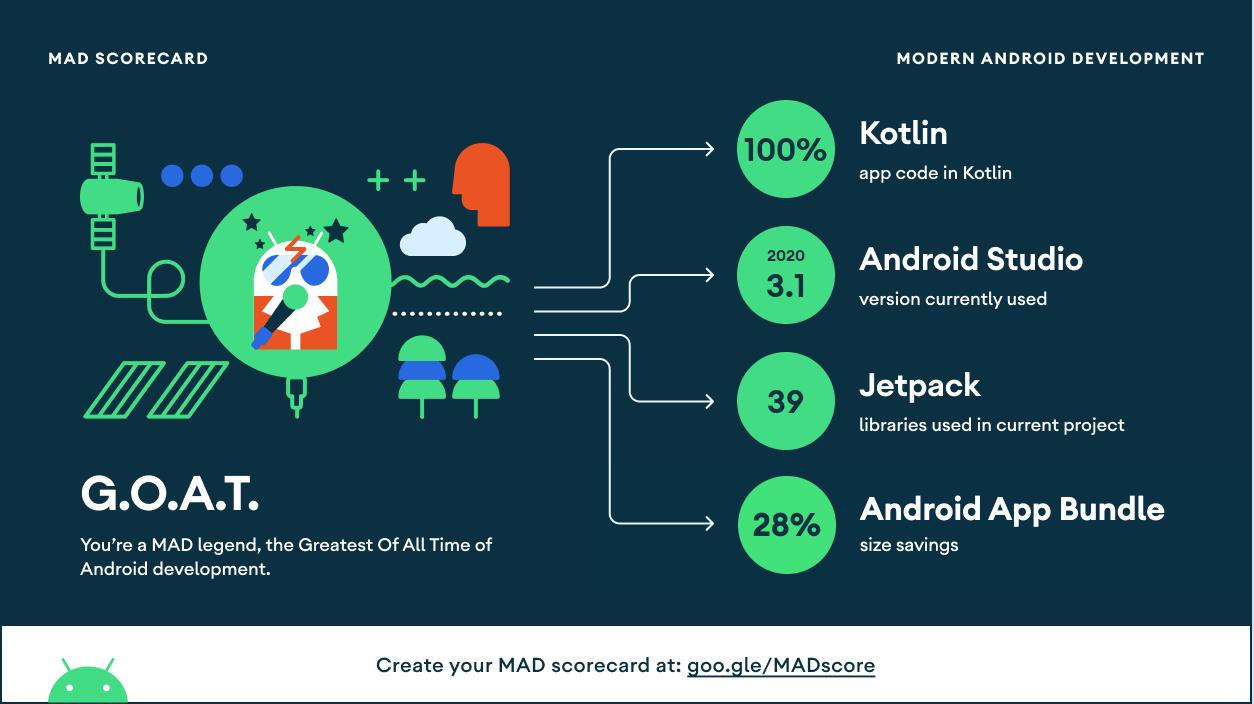接下来,本文将分享一些我们在对 MAD 实践过程中的心得和案例# 1. Kot...
LAS Spark 在 TPC-DS 的优化揭秘
也包含交互式联机查询和统计报表类应用,同时大数据的数据质量较低,数据分布真实而不均匀。因此 TPC-DS 成为客观衡量多个不同 Hadoop 版本以及 SQL on Hadoop 技术的最佳测试集。这个基准测试有以下几个主要特点:- 一共 99 个测试案例,遵循 SQL 99 和 SQL 2003 的语法标准,SQL 案例比较复杂;- 分析的数据量大,并且测试案例是在回答真实的商业问题;- 测试案例中包含各种业务模型(如分析报告型,迭代式的联机分析型,数据挖...
LAS Spark 在 TPC-DS 的优化揭秘
也包含交互式联机查询和统计报表类应用,同时大数据的数据质量较低,数据分布真实而不均匀。因此 TPC-DS 成为客观衡量多个不同 Hadoop 版本以及 SQL on Hadoop 技术的最佳测试集。这个基准测试有以下几个主要特点:- 一共 99 个测试案例,遵循 SQL 99 和 SQL 2003 的语法标准,SQL 案例比较复杂- 分析的数据量大,并且测试案例是在回答真实的商业问题- 测试案例中包含各种业务模型(如分析报告型,迭代式的联机分析型,数据挖掘...
 特惠活动
特惠活动
 多模块应用中的Firebase Analytics - 如何实现?-优选内容
多模块应用中的Firebase Analytics - 如何实现?-优选内容
 多模块应用中的Firebase Analytics - 如何实现?-相关内容
多模块应用中的Firebase Analytics - 如何实现?-相关内容
业务维度(item)数据接入(SaaS-非云原生版)
SaaS云原生版本和私有化版本接入请参考HTTP API文档中的6. 上报业务对象属性模块。 使用限制 本文档涉及的上报和查询 OpenAPI 接口均采用 Restful API 规范,且API使用QPS上限为500。 接入业务维度(item)数据时,需... API用法 域名国内: https://analytics.volcengineapi.com海外: https://analytics.byteplusapi.com 属性值初始化接口Path: /dataprofile/openapi/v1/{app_id}/items/{item_name}/{item_id}?set_once=trueMethod:...
AI赋能安全技术总结与展望| 社区征文
大家好,我是 herosunly。985 院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池安全恶意程序检测第一名,科大讯飞恶意软件分类挑战赛第三名,CCF恶意软件家族分类第四名,科大讯飞阿... 在网络空间安全中的很多细分领域涌现出与人工智能相关的新应用,比如恶意样本检测、恶意流量检测、恶意域名检测、异常检测、网络钓鱼检测与防护、威胁情报构建等。人工智能不仅能够提高威胁检测能力,而且还能帮助安...
「火山引擎数据 中台产品双月刊」 VOL.01
三款数据中台产品的功能迭代、重点功能介绍、产品联动使用案例、平台最新活动等多个有趣、有料的模块内容。# **产品迭代一览**## 火山引擎大数据研发治理套件 DataLeap- 公有云【数据开发特惠版】(限时特惠... 并且成为火山引擎湖仓一体分析服务 LAS(LakeHouse Analytics Service)的默认服务。本篇文章为Databricks 主办的Data + AI Summit峰会上的分享回顾。## 【文章】字节跳动杨震原:抖音电商是如何实现数据驱动的?...
字节跳动基于 Hudi 的机器学习应用场景
我们了解 Hudi 在机器学习离线数据流中的若干应用场景。# 2. 离线样本存储与迭代我们希望设计的样本离线存储方案能够适用于多种场景,主要包含以下三类情况。第一,模型的重新训练,回放流式训练的过程,迭代/纠... 如何实现低成本低读写放大的数据修改。在没有使用数据湖之前,用户做离线特征调研之前需要复制样本,修改并另存一份。其中消耗了巨大的计算和存储资源,伴随样本量的增大,这样的方案将消耗数个 EB 的存储,使得迭代变得...
数据驱动业务增长之体系化思考与建设|社区征文
如何实现具体落地的一套方法论,如图所示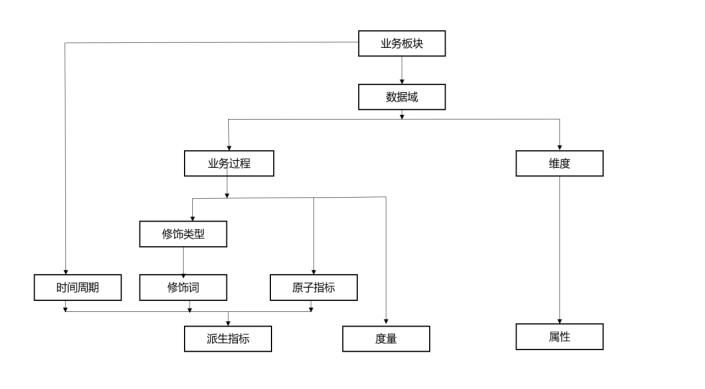(1)业务板块:即面向业务的大的模块,就是公司的产品线,不会经常变。比如一个公司有三个产品线分别是产品线A、产品线B、产品线C,那么这三个产品线分别属于不同的业务板块。(2)数据域:数据所属的领域。如电商产品中的用户、商品、交易等大的功能模块都属于数...
「火山引擎」数智平台 VeDI 数据中台产品季刊 VOL.10
可对原始数据中的敏感字段进行处理,降低数据敏感度并减少安全隐私风险。此外,安全策略还能与数据地图联动,标签化展示内容合法性,为信息安全提供强力保障。 **应用场景** - 隐私信息保密:业... [了解更多>>](https://www.volcengine.com/docs/6260/1188005) 【**工作流任务】** 在一个工作流任务下,采用可视化拖拉拽的方式,用户可自由组合不同引擎任务的依赖关系,轻松实现跨引擎、...
干货|Hudi Bucket Index 在字节跳动的设计与实践
**读那么多文件是必要的吗?**2. **更新那么多文件是必要的吗?**3. **分布式关联是必要的吗?**假设在数据分布最糟糕的情况下,需要被更新的 100 条数据分布在 100 个文件中。那我们实际需要读和更新的文件是多少个?**答案是 100 个,只占总量的 1/4。**因此,Hudi 为了消除不必要的读写,引入了索引的实现。在有了索引之后,更新的数据可以快速被定位到对应的 File Group,以下面的官方的示意图为例,1. 避免读取不...
干货|Hudi Bucket Index 在字节跳动的设计与实践
我们需要更新其中的 100 条数据。这三个很重的操作分别是: **1. 从 400 个文件中读出 100,000 条数据** **2. 与 100 条更新的数据做分布式关联,取最新值** **3. 将更新后的 100,000 条数据写入临时目录,最后... 需要被更新的 100 条数据分布在 100 个文件中。那我们实际需要读和更新的文件是多少个?**答案是 100 个,只占总量的 1/4。** 因此,Hudi 为了消除不必要的读写,引入了索引的实现。在有了索引之后,更新的数据可以快速...
干货|Hudi Bucket Index 在字节跳动的设计与实践
引入了索引的实现。在有了索引之后,更新的数据可以快速被定位到对应的 File Group,以下面的官方的示意图为例,1. 避免读取不需要的文件2. 避免更新不必要的文件3. 无需将更新数据与历史数据做分布式关联,只需要在 File Group 内做合并## 索引的类型索引是独立模块, 开源 Hudi 主要提供以...
