hbase取某一列包含某值
 社区干货
社区干货
20000字详解大厂实时数仓建设 | 社区征文
包含明细数据和汇总数据,统一了 DWD 层,降低了大数据资源消耗,提高了数据复用性,可对外输出丰富的数据服务。数仓具体架构如下图所示: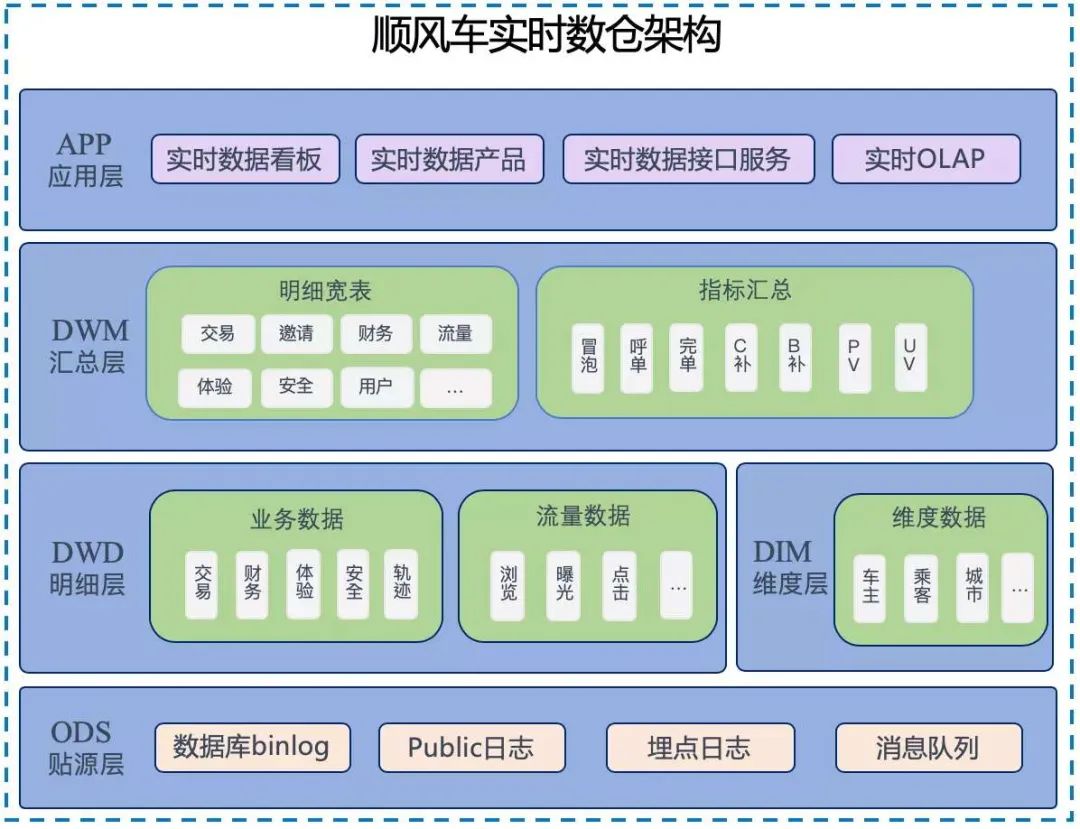从数据架构... Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要包括订单相关的 binlog 日...
干货|Hudi Bucket Index 在字节跳动的设计与实践
取最新值**3. **将更新后的 100,000 条数据写入临时目录,最后覆盖原先的数据**由此可以引出三个问题:1. **读那么多文件是必要的吗?**2. **更新那么多文件是必要的吗?**3. **分布式关联是必要的吗?*... 默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 ...
干货|Hudi Bucket Index 在字节跳动的设计与实践
**2. 与 100 条更新的数据做分布式关联,取最新值** **3. 将更新后的 100,000 条数据写入临时目录,最后覆盖原先的数据**由此可以引出三个问题:**1. 读那么多文件是必要的吗?** **2. 更新那么多文件是必要的... 默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Parti...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
支持对元数据的字段含义、使用场景等提问和回答,能力可插拔- ML Service:负责封装与机器学习相关的能力,能力可插拔- API Layer:以RESTful API的形式整合系统中的各类能力### 存储层针对不同场景,选用的不同的存储:- Meta Store:存放全量元数据和血缘关系,当前使用的是HBase- Index Store:存放用于加速查询,支持全文索引等场景的索引,当前使用的是ElasticSearch- Model Store:存放推荐、打标等的算法模型信息...
 特惠活动
特惠活动
 hbase取某一列包含某值-优选内容
hbase取某一列包含某值-优选内容
 hbase取某一列包含某值-相关内容
hbase取某一列包含某值-相关内容
StartThrift2
包括实例 ID。 ClientToken String 否 WbiAlPqJM6tMoSOYhT**** 用于保证请求的幂等性,防止重复提交请求。由客户端生成该参数值,要保证在不同请求间唯一,大小写敏感且不超过 127 个 ASCII 字符。 返回数据null 说明 申请成功后,您可调用 DescribeDBInstanceDetail 接口查看指定实例的详细信息,在 DBInstanceEndpoint 字段获取实例的 Thrift2 私网连接地址信息。 请求示例json POST https://hbase.volcengineapi.com/?Action=St...
20000字详解大厂实时数仓建设 | 社区征文
包含明细数据和汇总数据,统一了 DWD 层,降低了大数据资源消耗,提高了数据复用性,可对外输出丰富的数据服务。数仓具体架构如下图所示:从数据架构... Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要包括订单相关的 binlog 日...
干货|Hudi Bucket Index 在字节跳动的设计与实践
取最新值**3. **将更新后的 100,000 条数据写入临时目录,最后覆盖原先的数据**由此可以引出三个问题:1. **读那么多文件是必要的吗?**2. **更新那么多文件是必要的吗?**3. **分布式关联是必要的吗?*... 默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 ...
干货|Hudi Bucket Index 在字节跳动的设计与实践
**2. 与 100 条更新的数据做分布式关联,取最新值** **3. 将更新后的 100,000 条数据写入临时目录,最后覆盖原先的数据**由此可以引出三个问题:**1. 读那么多文件是必要的吗?** **2. 更新那么多文件是必要的... 默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Parti...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
支持对元数据的字段含义、使用场景等提问和回答,能力可插拔- ML Service:负责封装与机器学习相关的能力,能力可插拔- API Layer:以RESTful API的形式整合系统中的各类能力### 存储层针对不同场景,选用的不同的存储:- Meta Store:存放全量元数据和血缘关系,当前使用的是HBase- Index Store:存放用于加速查询,支持全文索引等场景的索引,当前使用的是ElasticSearch- Model Store:存放推荐、打标等的算法模型信息...
EMR-2.1.0版本说明
Dolphin Scheduler 3.1.1 - Hudi 0.11.1 - 发布说明 以下发布说明包括有关 EMR V2.1.0 的信息。EMR V2.1.0为火山引擎EMR V2.1.x的第一个版本。发布日期: 2022 年 12 月 15 日 新增功能【集群】新增独立的HBase集... ranger_usersync 1.2.0 拉取用户和组的Ranger服务。 spark_jobhistoryserver 3.2.1 用于查看完整的 Spark 应用程序的生命周期的已记录事件的 Web UI。 ksana 1.0 为字节EMR团队自研组件,定位于SparkSQL数据仓库构...
Hudi Bucket Index 在字节跳动的设计与实践
取最新值**3. **将更新后的 100,000 条数据写入临时目录,最后覆盖原先的数据**由此可以引出三个问题:* **读那么多文件是必要的吗?*** **更新那么多文件是必要的吗?*** **分布式关联是必要的吗?**假设... 默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向...
Hudi Bucket Index 在字节跳动的设计与实践
取最新值****(3)将更新后的 100,000 条数据写入临时目录,最后覆盖原先的数据**由此可以引出三个问题:**(1)读那么多文件是必要的吗?****(2)更新那么多文件是必要的吗?****(3)分布式关联是必要的吗?... 默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Parti...
DataLeap 数据资产实战:如何实现存储优化?
排除了 HBase 和 Cassandra;- 从当前数据量与将来的可扩展性考虑,单机方案不可选,排除了 BerkeleyDB;- 同样因为人力成本,需要做极大量开发改造的方案暂时不考虑,排除了 Redis。 最终我们挑选了 MySQL ... 特定的 key 来说,存储和读取某个 shard,是根据 ShardManager 来决定 典型的 ShardManager 逻辑,是根据总 shard 数对 key 做 hash 决定,默认单分片。- 对于每个 Store,表结构是 4 列(id, g_key, g_column,...
