hbase的架构底层存储
 社区干货
社区干货
基于国产化环境的金融级业务系统性能优化实践|社区征文
系统总体架构设计如下所示: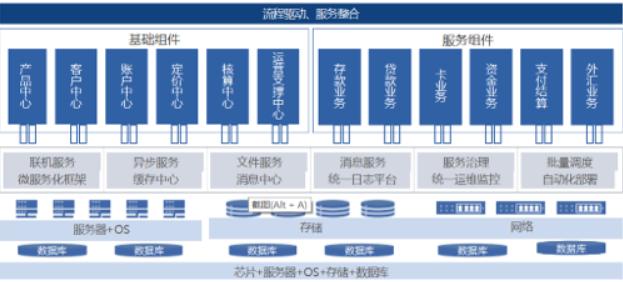- 底层芯片采用国内主流ARM路线的CPU;- 操作系统采用国产Kylin操作系统;- 数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理...
字节跳动基于数据湖技术的近实时场景实践
# **本文为字节跳动基于****数据湖****技术的近实时场景实践,主要包括以下几部分内容:数据湖技术的特性、近实时技术的架构、电商****数仓****实践、未来的挑战与规划。** # ▌**数据湖**技术特性1. ## **... Hudi 支持各类计算、查询引擎(Flink、Spark、Presto、Hive),底层存储兼容各类文件系统 (HDFS、Amazon S3、GCS、OSS) - Hudi 使用 Timeline Service机制对数据版本进行管理,实现了数据近实时增量读、写。 - ...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 HDFS 架构。## **架构介绍** 字节跳动 HDFS 架构 ### **接入层**接入层是字节版 HDFS 区别于社区版本最大的一层,社区版本中并无这一层定义。在字节跳动的落地实践中,由于集群的节点过于庞大,我们需要非常多的 N...
20000字详解大厂实时数仓建设 | 社区征文
实时数仓的数据源存储不同:**- 在建设离线数仓的时候,目前滴滴内部整个离线数仓都是建立在 Hive 表之上。但是,在建设实时数仓的时候,同一份表,会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车...
 特惠活动
特惠活动
 hbase的架构底层存储-优选内容
hbase的架构底层存储-优选内容
 hbase的架构底层存储-相关内容
hbase的架构底层存储-相关内容
20000字详解大厂实时数仓建设 | 社区征文
实时数仓的数据源存储不同:**- 在建设离线数仓的时候,目前滴滴内部整个离线数仓都是建立在 Hive 表之上。但是,在建设实时数仓的时候,同一份表,会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车...
干货 | 这样做,能快速构建企业级数据湖仓
HDFS 到云对象存储等多种底层。* **Table 格式** :本质上是基于存储的、 Table 的数据+元数据定义。具体来说,这种数据格式有三个实现: **Delta Lake** 、 **Iceberg** 和 **Hudi** 。三种格式的出发点略有不同,但是场景需求里都包含了事务支持和流式支持。在具体实现中,三种格式也采用了相似做法,即在数据湖的存储之上定义一个元数据,并跟数据一样保存在存储介质上面。这三者相似的需求以及相似的架构,导致了他们在演化过...
Hive SQL 底层执行过程 | 社区征文
> 本文结构采用宏观着眼,微观入手,从整体到细节的方式剖析 Hive SQL 底层原理。第一节先介绍 Hive 底层的整体执行流程,然后第二节介绍执行流程中的 SQL 编译成 MapReduce 的过程,第三节剖析 SQL 编译成 MapReduce 的具体实现原理。### 一、HiveHive是什么?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。Hive直接访问存储在 HDFS 中或者 HBase ...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
与底层的存储或业务系统交互,操作底层资源,比如建库建表,能力可插拔- Q&A Service:问答系统相关能力,支持对元数据的字段含义、使用场景等提问和回答,能力可插拔- ML Service:负责封装与机器学习相关的能力,能力可插拔- API Layer:以RESTful API的形式整合系统中的各类能力### 存储层针对不同场景,选用的不同的存储:- Meta Store:存放全量元数据和血缘关系,当前使用的是HBase- Index Store:存放用于加速查询,...
基于火山引擎 EMR 构建企业级数据湖仓
它既保留了 DataLake 分析结构化、半结构化、非结构化数据,支持多种场景的能力,同时也引入了 Data Warehouse 支持事务和数据质量的特点。LakeHouse 定义了一种叫我们称之为 Table Format 的存储标准。Table form... 即在数据湖的存储之上定义一个元数据,并跟数据一样保存在存储介质上面。这三者相似的需求以及相似的架构,导致了他们在演化过程中变得越来越相似。:关键技术与总结
在存储层,火山引擎 DataLeap 研发人员借用了Atlas的设计与实现。Atlas的底层使用JanusGraph做图引擎。JanusGraph 是基于Gremlin 图查询语义实现的计算引擎,其底层存储支持HBase/Cassadra/BerkeleyDB等KCV结构的存储,同时,使用ElasticSearch作为索引查询支持。当火山引擎 DataLeap 研发人员将越来越多的元数据接入系统,图存储中的点和边分别到达百万和千万量级,读写性能都遇到了比较大的问题。我们做了部分源码的修改,这边介绍其...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
> 深度学习的模型规模越来越庞大,其训练数据量级也成倍增长,这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删... 其次是通过**传统数据库方案**存放样本,这种方案更多适用于处理少量样本的场景,当海量数据达到 PB、EB 级时会遇到困难。此外由于训练代码无法直接读取数据库底层文件,读取吞吐量可能受限制,即使在实时拼接特征、标...
干货|数据湖技术在抖音近实时场景的实践
近实时技术的架构、电商数仓实践、未来的挑战与规划。> ======================================================================> > > * Hudi 使用 Timeline Service机制对数据版本进行管理,实现了数据近实时增量读、写。* Hudi 支持 Merge on Read / Copy on Write 两种表类型,以及Read...
