hbase的jdbc驱动
 社区干货
社区干货
干货 | 看 SparkSQL 如何支撑企业级数仓
Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服... MapReduce 和 HBase,形成了早期 Hadoop 的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似 SQL 语法的分析入口,同时在编程态的支撑也不够友好,只有 Map 和 Reduce ...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
HBase、Vertica、Impala、Greenplum、 ClickHouse. 其中,**Hive:** 使用一种类似SQL查询语言,作用在分布式存储系统的文件之上,通常用于进行离线数据处理操作-MapReduce,支持多种不同的执行引擎-Hive on MapReduce、Hive on Tez、Hive on Spark.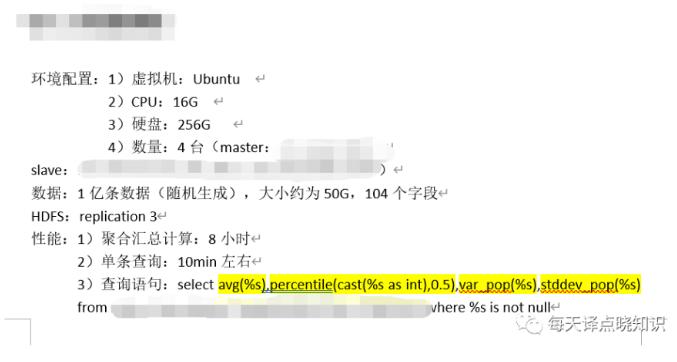**HBase:** 分布式、面向列开源数据库,不同...
达梦@记一次国产数据库适配思考过程|社区征文
String driverClassName = "dm.jdbc.driver.DmDriver";String url = "jdbc:dm://localhost:5236/";String username = "yxd179";String password = "yxd179";// 加载驱动Class.forName(driverClassName);// 获取数据库连接对象Connection con = (Connection) DriverManager.getConnection(url,username,password);// 获取数据库操作对象PreparedStatement ps = con.prepareStatement("SELECT COUNT(*) FROM TEST;");// ...
观点|SparkSQL在企业级数仓建设的优势
经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元... MapReduce和HBase,形成了早期Hadoop的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似SQL语法的分析入口,同时在编程态的支撑也不够友好,只有Map和Reduce两阶段,...
 特惠活动
特惠活动
 hbase的jdbc驱动-优选内容
hbase的jdbc驱动-优选内容
 hbase的jdbc驱动-相关内容
hbase的jdbc驱动-相关内容
ClickHouse JDBC Driver
基本用法 ClickHouse JDBC APIClass import com.clickhouse.client.config.ClickHouseClientOption import com.clickhouse.client.config.ClickHouseDefaults 连接信息请参考通过驱动连接到 ByteHouse,了解如何通过API Token或用户名+密码的方式连接到ByteHouse。 数据插入与查询您可以参考下面的代码示例来进行数据插入与查询,注意替换 API key 和 ClickHouse HTTP 的等连接信息。其中 Clickhouse HTTP 的字段,不用携带 "ht...
EMR-3.4.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSearch集... Flink组件增加对Connector的支持,提供HBase 、JDBC、Mysql CDC Connector 【组件】Spark组件增加数据源的支持,提供对Kudu、HBase、Phoenix数据源的支持 【组件】提供Tez webUI,便于分析任务的执行状态 更改、增...
DataGrip(TCP)
DataGrip 是 JetBrains 公司专为数据库开发人员和管理员设计的一套集成开发环境(IDE)。它支持各种数据库管理系统,提供智能代码完成,并便于版本控制集成。本文将介绍 DataGrip 如何通过JDBC 驱动,以 TCP 的方式来连接 ByteHouse 云数仓版。 前提条件请提前安装好 DataGrip ,并获得相应的商用授权。 从 ByteHouser JDBC driver 的 发布页面 获取最新版本的jar文件。 使用限制当使用Bytehouse JDBC TCP驱动程序进行连接时,设置项 m...
干货 | 看 SparkSQL 如何支撑企业级数仓
Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服... MapReduce 和 HBase,形成了早期 Hadoop 的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似 SQL 语法的分析入口,同时在编程态的支撑也不够友好,只有 Map 和 Reduce ...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
HBase、Vertica、Impala、Greenplum、 ClickHouse. 其中,**Hive:** 使用一种类似SQL查询语言,作用在分布式存储系统的文件之上,通常用于进行离线数据处理操作-MapReduce,支持多种不同的执行引擎-Hive on MapReduce、Hive on Tez、Hive on Spark.**HBase:** 分布式、面向列开源数据库,不同...
连接器列表
Flink 1.16 upsert-kafka 提供以 upsert 方式从 Kafka Topic 中读取数据并将数据写入 Kafka Topic 的能力。 ✅ ✅ ❌ Flink 1.16 jdbc 提供对 MySQL、PostgreSQL 等常见的关系型数据库的读写能力,以及支持... Flink 1.16 hbase-1.4 提供从 Hbase 表中读写数据的能力,支持做源表、结果表,以及维表。 ✅ ✅ ✅ Flink 1.11、Flink 1.16 hbase-2.2 ✅ ✅ ✅ Flink 1.16 elasticsearch-6 提供对不同版本 Elasticse...
DataGrip
DataGrip 是 JetBrains 公司专为数据库开发人员和管理员设计的一套集成开发环境(IDE)。它支持各种数据库管理系统,提供智能代码完成,并便于版本控制集成。本文将介绍 DataGrip 如何通过JDBC 驱动来连接 ByteHouse 企业版。 前提条件请提前安装好 DataGrip ,并获得相应的商用授权。 使用 DataGrip 连接 ByteHouse启动 DataGrip,在 Database Explorer 页签单击 + 图标,选择 Data Source -> ClickHouse*。* 切换到 Drivers 页签,单...
Shell 调用 DataX 最佳实践
DataX 是开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。DataX 作为数据同步框架,它将不同数据源的... "connection": [ { "jdbcUrl": [ "jdbc:mysql://ip:port/databases" // 数据库的JDBC私...
基础使用
2 RDD基础操作Spark围绕着 RDD 的概念展开,RDD是可以并行操作的元素的容错集合。Spark支持通过集合来创建RDD和通过外部数据集构建RDD两种方式来创建RDD。例如,共享文件系统、HDFS、HBase或任何提供Hadoop InputFo... 5.1 数据库操作5.1.1 创建数据库 0: jdbc:hive2://emr-master-1:10005> create database db_demo;+---------+ Result +---------++---------+No rows selected (0.285 seconds)5.1.2 查看数据库信息 0: jdbc:hiv...
