hbase每次都要启动吗
 社区干货
社区干货
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 元信息在启动时被加载到内存中。Data Node 会定时向 Name Node 做心跳汇报,并且周期性将自己所存储的副本信息汇报给 Name Node。这个过程对 Federation 中的每个集群都是独立完成的。在心跳汇报的返回结果中,会携...
基于国产化环境的金融级业务系统性能优化实践|社区征文
它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续... 所以IO子系统优化最主要的目的就是减少CPU计算数据从磁盘读取的等待事件,从而提升计算效率。一般情况扩展提升缓存、内存、磁盘的效率等是一些常见手段;另外也可以从计算数据的读取规律层面进行优化,如:开启数据库预...
2022技术盘点之平台云原生架构演进之道|社区征文
每次运行脚本任务时,Gitlab-Runner 会自动创建一个或多个新的临时 Runner来运行Job。- 资源最大化利用:动态创建Pod运行Job,资源自动释放,而且 Kubernetes 会根据每个节点资源的使用情况,动态分配临时 Runner 到空... 安全等功能需要借助服务治理框架实现。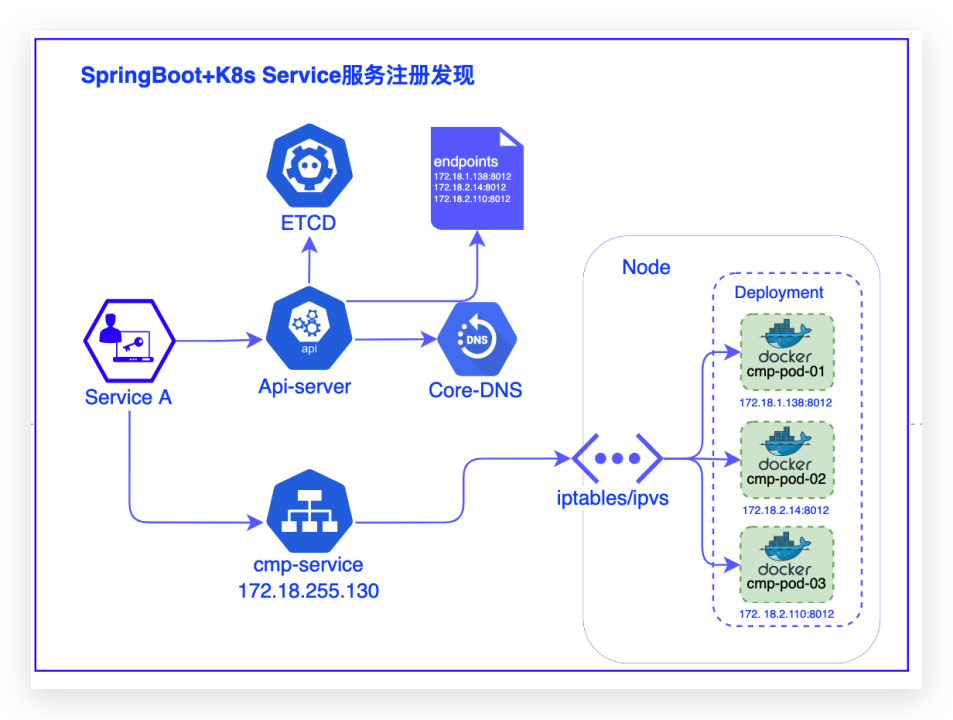服务注册:spring Boot 应用配置有serivce的服务,启动后k8s集群针对调...
一文读懂火山引擎云数据库产品及选型
宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以 Neo4j 为代表)**。虽然这些类型都属于 NoSQL 数据库范畴,但是不同类型的 NoSQL 数据库所适用的场景各有不同,需要根据业务特征选择合适的 NoSQL 数据库。其中 KV 型 NoSQL 数据库适用于需要超高性能,读远多于写,并且可以容忍数据部分丢失的场景,例如作为关系型数据库的外部缓存,用于提升系统整体的读性能,减轻关系型数据...
 特惠活动
特惠活动
 hbase每次都要启动吗-优选内容
hbase每次都要启动吗-优选内容
 hbase每次都要启动吗-相关内容
hbase每次都要启动吗-相关内容
基于国产化环境的金融级业务系统性能优化实践|社区征文
它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续... 所以IO子系统优化最主要的目的就是减少CPU计算数据从磁盘读取的等待事件,从而提升计算效率。一般情况扩展提升缓存、内存、磁盘的效率等是一些常见手段;另外也可以从计算数据的读取规律层面进行优化,如:开启数据库预...
2022技术盘点之平台云原生架构演进之道|社区征文
每次运行脚本任务时,Gitlab-Runner 会自动创建一个或多个新的临时 Runner来运行Job。- 资源最大化利用:动态创建Pod运行Job,资源自动释放,而且 Kubernetes 会根据每个节点资源的使用情况,动态分配临时 Runner 到空... 安全等功能需要借助服务治理框架实现。服务注册:spring Boot 应用配置有serivce的服务,启动后k8s集群针对调...
DisassociateAllowList
请确保还需要访问当前实例的设备 IP 已加入其他白名单中。 请求参数名称 类型 是否必选 示例值 描述 InstanceIds Array of String 是 ["hb-cnglda9068d1****"] 需要解绑白名单的实例 ID。 说明 您可以调用 DescribeDBInstances 接口查询目标地域下所有 HBase 实例的基本信息,包括实例 ID。 支持一次传入多个实例 ID,多个 ID 间用英文逗号(,)分隔。 不支持同时传入多个实例 ID 和白名单,即每次仅允许将一个白名单中的多...
一文读懂火山引擎云数据库产品及选型
宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以 Neo4j 为代表)**。虽然这些类型都属于 NoSQL 数据库范畴,但是不同类型的 NoSQL 数据库所适用的场景各有不同,需要根据业务特征选择合适的 NoSQL 数据库。其中 KV 型 NoSQL 数据库适用于需要超高性能,读远多于写,并且可以容忍数据部分丢失的场景,例如作为关系型数据库的外部缓存,用于提升系统整体的读性能,减轻关系型数据...
9年演进史:字节跳动 10EB 级大数据存储实战
**承载的主要业务如下:*** Hive,HBase,日志服务,Kafka 数据存储* Yarn,Flink 的计算框架平台数据* Spark,MapReduce 的计算相关数据存储**02****字节跳动特色的 HDFS 架构**... 元信息在启动时被加载到内存中。Data Node 会定时向 Name Node 做心跳汇报,并且周期性将自己所存储的副本信息汇报给 Name Node。这个过程对 Federation 中的每个集群都是独立完成的。在心跳汇报的返回结果中,会...
常见问题
5.x HBase(protobuf) 所有版本 HBase(thrift) Thrift1、thrift2 Hive 1.X、2.X、3.X Redis 所有版本 Elasticsearch 所有版本 Cassandra 3.X HDFS 所有版本 Impala 3.X Graphbase 6 Greenplum 5、6 Spark SQL(thrift) 1.x、2.x Spark SQL(RESTful) 1.x、2.x SSDB 所有版本 ArangoDB 3.4.9 Neo4j 4.2.0 OrientDB 3.1.6 Percona MongoDB 4.x、5.x 大数据 HBase(protobuf) 所有版本 HBase(thr...
如何调优一个大型 Flink 任务 | 社区征文
是否需要复杂计算等,均会造成一定偏差。另外,CPU 本身的优劣也会造成一定影响。# 如何拆解性能问题?网上有大量的 Flink 性能调优案例分析,但实际上我们每次遇到性能问题时往往还是无从下手,这是因为没有从案例... HBase 等外部资源,那么这些基础设施本身都会有相应的延迟监控,可以从中判定延迟的来源。### 2. 并行度不足并行度不足的问题比较容易发现,一般可以观察任务总体的 CPU 占用,以及各个 Task Manager/Container 的...
20000字详解大厂实时数仓建设 | 社区征文
明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS... 每次微调的过程之中都要改,单作业的稳定性会非常差;第二个问题是:数据量是万亿级,这会导致两个情况,首先是这个量级的单作业稳定性非常差,其次是实时关联维表的时候用的 KV 存储,任何一个这样的 RPC 服务接口,都不...
Shell 调用 DataX 最佳实践
DataX 是开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。DataX 作为数据同步框架,它将不同数据源的... 同步时启动并发任务进行数据同步。推荐使用表主键切分。 "connection": [ { "jdbcUrl": [ ...
