hbase索引大小几十个G
 社区干货
社区干货
干货|Hudi Bucket Index 在字节跳动的设计与实践
默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 ... 在建表时先预估表的单个分区数据存储大小,设置一个分桶数 numBuckets。2. 在数据插入前,首先生成 n 个 File ID, 将 File ID 的前8位替换成 bucketId 的数字 00000000-e929-4327-8b0c-7d0d66091321 0000...
Hudi Bucket Index 在字节跳动的设计与实践
数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBa... i-tlddhu82om/cd5f35b2be3b41d083b8f028e6178bf0~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1714494015&x-signature=s8rOaVItlbOzfBbJ72JfA1Bxvd0%3D)(1)在建表时先预估表的单个分区数据存储大小...
Hudi Bucket Index 在字节跳动的设计与实践
默认的索引方式 包含在数据文件的footer中。默认配置,不依赖外部系统,数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向... =&rk3s=8031ce6d&x-expires=1714494045&x-signature=fX%2BfhjmkvzPPB6u2KpGr4u8zGtk%3D)1. 在建表时先预估表的单个分区数据存储大小,设置一个分桶数 numBuckets。2. 在数据插入前,首先生成 n 个 File ID, 将 F...
干货|Hudi Bucket Index 在字节跳动的设计与实践
索引是独立模块, 开源 Hudi 主要提供以下两种索引: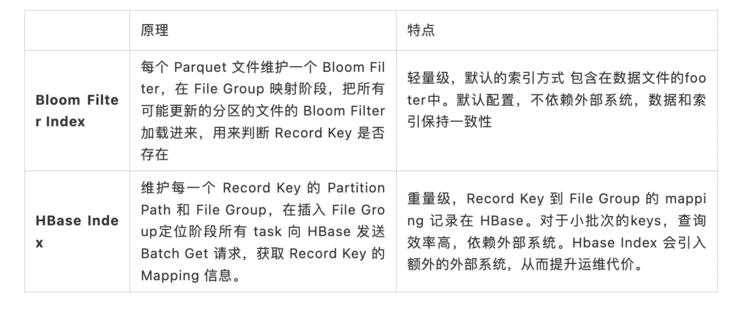在本文中,我们将介绍一个新的 Hudi 索引模块 Bucket Index 在字节跳动的设计与实践。# Bucket Index 产生背景索引带来的性能收益是非常巨大的, 尽管 Hudi 已支持 Bloom Filter Index、Hbase index 类型,但在字节跳动大规模数据入湖、探索分...
 特惠活动
特惠活动
 hbase索引大小几十个G-优选内容
hbase索引大小几十个G-优选内容
 hbase索引大小几十个G-相关内容
hbase索引大小几十个G-相关内容
Hudi Bucket Index 在字节跳动的设计与实践
数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBa... i-tlddhu82om/cd5f35b2be3b41d083b8f028e6178bf0~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1714494015&x-signature=s8rOaVItlbOzfBbJ72JfA1Bxvd0%3D)(1)在建表时先预估表的单个分区数据存储大小...
干货|Hudi Bucket Index 在字节跳动的设计与实践
索引是独立模块, 开源 Hudi 主要提供以下两种索引:在本文中,我们将介绍一个新的 Hudi 索引模块 Bucket Index 在字节跳动的设计与实践。# Bucket Index 产生背景索引带来的性能收益是非常巨大的, 尽管 Hudi 已支持 Bloom Filter Index、Hbase index 类型,但在字节跳动大规模数据入湖、探索分...
20000字详解大厂实时数仓建设 | 社区征文
/ods_log_{日志名} eg: realtime_ods_binlog_ihap_fangyuan`---#### 2. DWD 明细层建设根据顺风车业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表;结合顺风车分析师在离线侧的... Hbase、fusion(滴滴自研 KV 存储) 三种存储引擎,对于维表数据比较少的情况可以使用 MySQL,对于单条数据大小比较小,查询 QPS 比较高的情况,可以使用 fusion 存储,降低机器内存资源占用,对于数据量比较大,对维表数据...
一文读懂火山引擎云数据库产品及选型
这是个复杂的问题, 因为各行各业的业务场景各不相同,对数据库的需求和使用场景差异很大,可选择的数据库系统也是几十上百种,如此一组合下来,对于非数据库专业人士,选择复杂度非常高。本文的目的就是要尝试回答这个... 文档型 NoSQL 数据库(以 MongoDB 为代表)、宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以 Neo4j 为代表)**。虽然这些类型都属于 NoSQL 数据库范畴,但是不...
字节跳动数据湖索引演进
=&rk3s=8031ce6d&x-expires=1714494073&x-signature=MTAnSGvwUz2HZAG4WWB1%2F2F6bVI%3D)以一个极端的场景为例:假设用户只需要更新 1 条数据,但是历史的全量数据有 100 个文件,每个文件大小有 1G,那么更新这 1 条数... 这是默认的索引方案,基于布隆过滤器实现,索引信息存储在 Parquet 文件的 Footer 当中。② Hbase Index。索引信息存储在 Hbase 数据库上。③ Bucket Index。字节提出的一种基于哈希的实现,不需要额外存储索引信息,可...
干货|Hudi Bucket Index 在字节跳动的设计与实践
数据和索引保持一致性 || **HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBa... tlddhu82om/62245696d5624c8c99a7fcceb2c5e880~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1714494073&x-signature=VUv5UxeBfvYrA5O5x9FTgCxZhgo%3D)1. 在建表时先预估表的单个分区数据存储大小...
干货 | 以一次Data Catalog架构升级为例,聊聊业务系统的性能优化
十几分钟后触发超时* 一张几十列的埋点表,上下游很多,打开详情展示时需要等1分钟以上为此,我们进行了一系列的性能调优,结合Data Catlog产品的特点,调整了Apache Atlas以及底层Janusgraph的实现或配置,并对优... JanusGraph在写入一个property的时候,会先找到跟这个property相关的组合索引,然后从中筛选出Coordinality为“Single”的索引2. 在写入之前,会check这些为Single的索引是否已经含有了当前要写入的propertyValue3...
干货 | 这样做,能快速构建企业级数据湖仓
**Iceberg** 和 **Hudi** 。三种格式的出发点略有不同,但是场景需求里都包含了事务支持和流式支持。在具体实现中,三种格式也采用了相似做法,即在数据湖的存储之上定义一个元数据,并跟数据一样保存在存储介质上面... 并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
gnature=nwvjQVF2j4piVNe2oEkutCRwpnY%3D)上图是字节典型的广告后端架构,数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系... 在数据大小上,TPC-H 上,Krypton 增长了 13%,主要是因为 Krypton 内部的索引,但在 Magnus 上,Krypton 减少了 8%,这主要受益于在复合类型的高效存储。**实验** **环境**1. **实验环...
