hbase和tidb谁快
 社区干货
社区干货
分布式数据库TiDB的设计和架构
导语市场上有很多数据库产品,如Oracle、MySQL、SQLServer、NoSQL、NewSQL等,那么目前数据库圈最火的分布式关系型数据库之一TiDB你了解吗?相信很多同学以前听说过TiDB,也知道是一款国人研发的数据库,但你知道TiDB... 开始快速发展,如 MongoDB,HBase。但此类数据库的局限在于无法处理交易类数据及复杂业务逻辑的特性,限制其在非互联网领域的发展。**2013年以后**2013年以来,有个新的概念为分布式关系型数据库(NewSQL),它是兼具...
分布式数据库TiDB的设计和架构
那么目前数据库圈最火的分布式关系型数据库之一TiDB你了解吗?相信很多同学以前听说过TiDB,也知道是一款国人研发的数据库,但你知道TiDB到底是如何实现的?它跟其他数据库产品相比,它的核心优势是什么?此次夜校分享... 开始快速发展,如 MongoDB,HBase。但此类数据库的局限在于无法处理交易类数据及复杂业务逻辑的特性,限制其在非互联网领域的发展。**2013年以后**2013年以来,有个新的概念为分布式关系型数据库(NewSQL),它是兼具...
字节跳动 NoSQL 的探索与实践
列存:以 HBase 为代表; - 图、时序等新兴的数据库也都属于 NoSQL 范畴。如今 NoSQL 在字节跳动有非常广泛的应用:数万 NoSQL 应用实例,10W+ 台物理服务器资源,字节跳动超过 90% 的在线服务都是 NoSQL 系统提供的。### NoSQL 产品矩阵![]()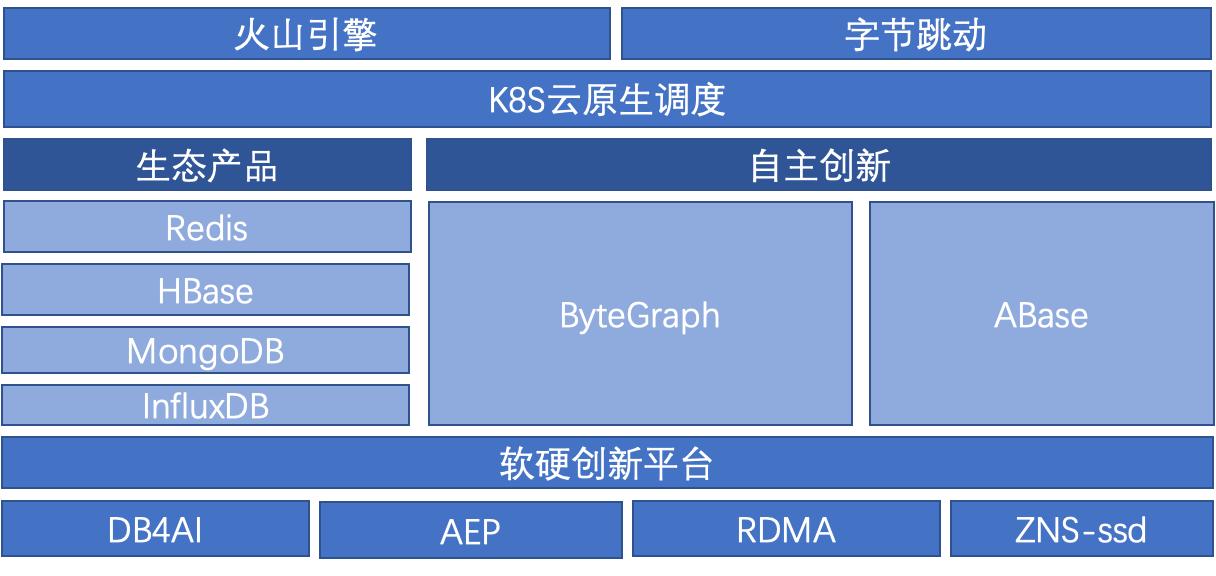上图是字节跳动 NoSQL 的产品矩阵。我们对内对...
20000字详解大厂实时数仓建设 | 社区征文
渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要... 将消息落盘到 TiDB 存储,基于 TiDB 的能力对落盘的消息进行检索、查询、汇总。编写固定时间边界的测试用例与相同时间边界的业务库数据或者离线数仓数据进行比对。通过以上方式,抽样核心店铺的数据进行指标准确性验...
 特惠活动
特惠活动
 hbase和tidb谁快-优选内容
hbase和tidb谁快-优选内容
 hbase和tidb谁快-相关内容
hbase和tidb谁快-相关内容
创建实例
创建实例是开启使用表格数据库 HBase 版的第一步。本文介绍如何创建 HBase 实例。 前提条件已注册火山引擎账号,并完成实名认证。账号注册和实名认证的操作步骤,请参见如何进行账号注册和实名认证。 已创建私有网络和子网。操作步骤请参见创建私有网络及子网。 操作步骤登录 HBase 控制台。 在顶部菜单栏的左上角,选择实例所属的地域。 在实例列表页,单击创建实例。 在创建实例页,设置如下参数。 类别 参数 说明 基本信息 实例...
字节跳动 NoSQL 的探索与实践
列存:以 HBase 为代表; - 图、时序等新兴的数据库也都属于 NoSQL 范畴。如今 NoSQL 在字节跳动有非常广泛的应用:数万 NoSQL 应用实例,10W+ 台物理服务器资源,字节跳动超过 90% 的在线服务都是 NoSQL 系统提供的。### NoSQL 产品矩阵![]()上图是字节跳动 NoSQL 的产品矩阵。我们对内对...
20000字详解大厂实时数仓建设 | 社区征文
渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要... 将消息落盘到 TiDB 存储,基于 TiDB 的能力对落盘的消息进行检索、查询、汇总。编写固定时间边界的测试用例与相同时间边界的业务库数据或者离线数仓数据进行比对。通过以上方式,抽样核心店铺的数据进行指标准确性验...
干货 | 看 SparkSQL 如何支撑企业级数仓
负责清洗和加工上层业务所需要的数据,用来支撑整个企业的数仓构建。一个企业在实施数据平台的时候,由多个不同组件各自工作在不同的架构层中,无法相互取代,相互协作配合,承载整个企业的数据平台业务。# 企业级数仓技术选择Google 发表的三篇论文从存储,计算,检索三个方向阐述了海量数据下一种新的分布式数据加工处理技术,这三个方向被雅虎 Nutch 团队实现后贡献给 Apache,也就是目前大家看到的 HDFS,MapReduce 和 HBase,形成...
观点|SparkSQL在企业级数仓建设的优势
MapReduce和HBase,形成了早期Hadoop的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似SQL语法的分析入口,同时在编程态的支撑也不够友好,只有Map和Reduce两阶段,严重限制了业务处理的实现,雅虎团队也是爬虫相关业务孵化而出,可以看出Hadoop早期的三大套件有着如下特点:* 门槛高,需要编程实现,并且编程态受限于MapReduce的两阶段约束。* 以离散数据处理为主,对分析能力,查...
字节跳动 NoSQL 的探索与实践
订单的状态和实际交易的过程达成一致;但这个过程有一定的时间延迟。BASE 理论是对 CAP 中 AP 理论的扩展,通过牺牲强一致性获得可用性。当出现故障时,允许部分不可用,但能保证核心功能可用;允许数据在一段时间内不一致,但最终要达到一致。NoSQL 大致可以分为以下几类:- KV 类:以 Redis 为代表;- 文档型:以 MongoDB 为代表;- 列存:以 HBase 为代表;- 图、时序等新兴的数据库也都属于 NoSQL 范畴。如今 NoSQL 在字节跳动...
干货 | 字节跳动构建Data Catalog数据目录系统的实践(上)
使用场景等提问和回答,能力可插拔* ML Service:负责封装与机器学习相关的能力,能力可插拔* API Layer:以RESTful API的形式整合系统中的各类能力 **存储层**针对不同场景,选用的不同的存储:* Meta Store:存放全量元数据和血缘关系,当前使用的是HBase* Index Store:存放用于加速查询,支持全文索引等场景的索引,当前使用的是ElasticSearch* Model Store:存放推荐、打标等的算法模型信息,使用HDFS,当ML Service启用时使...
字节跳动数据库的过去、现状与未来
加之商业化数据库和存储带来的巨大成本使企业难以承受,以 NoSQL 和 BigData 为代表的数据库革命正式爆发,无论是 Google 开源的 HDFS、Bigtable,还是 HBase、MongoDB,它们都旨在解决 OLTP 型数据库吞吐量、扩展性不足的问题。到 2010 年,Google 开始大量使用 NoSQL 和 BigData 数据库系统,但很快它就发现了不少问题,比如 NoSQL 不支持事务且每个产品的 NoSQL 接口都不一样,这给应用程序迁移和学习带来了极大的成本,为此它又开发...
干货|字节跳动数据湖技术选型的思考
State索引和Hbase索引来做到高效率的全局索引**。这两个例子说明了不同场景下,索引的选择也会决定了整个表读写性能。Hudi提供多种开箱即用的索引,已经覆盖了绝大部分场景,用户使用成本非常低。02 - Merge On Read表格式除了索引系统之外,Hudi的Merge On Read表格式也是一个我们看重的核心功能之一。这种表格式让实时写入、近实时查询成为了可能。在大数据体系的建设中,写入引擎和查询引擎存在着天然的冲突:...
