hbase和SQL的区别
 社区干货
社区干货
Hive SQL 底层执行过程 | 社区征文
再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark 或 Tez 执行查询。我们今天来聊... ```sqlselect rank, isonline, count(*) from city group by rank, isonline;```将GroupBy的字段组合为map的输出key值,利用MapReduce的排序,在reduce阶段保存LastKey区分不同的key。MapReduce的过程如下: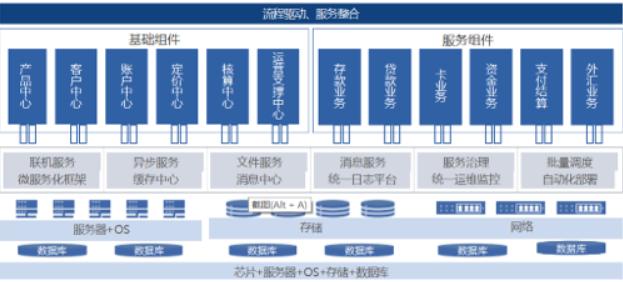- 底层芯片采用国内主流ARM路线的CPU;- 操作系统采用国产Kylin操作系统;- 数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。...
我的大数据学习总结 |社区征文
学习数据流技术Kafka和分布式协调服务Zookeeper。深入研究Yarn和求执行引擎Spark。此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和操作系统原理。后面再系统学习关系数据库MySQL和数据仓库理论。学... 学习难点: SQL on RDD与SQL on Dataset/DataFrame的区别。在学习SparkSQL时,我发现它支持两种SQL查询方式:使用SQL对RDD进行查询,以及使用SQL对Dataset/DataFrame进行查询。区分两个概念变得很重要。为了理解区别...
 特惠活动
特惠活动
 hbase和SQL的区别-优选内容
hbase和SQL的区别-优选内容
 hbase和SQL的区别-相关内容
hbase和SQL的区别-相关内容
基础使用
本文将为您介绍Spark支持弹性分布式数据集(RDD)、Spark SQL、PySpark和数据库表的基础操作示例。 1 使用前提已创建E-MapReduce(简称“EMR”)集群,详见:创建集群。 2 RDD基础操作Spark围绕着 RDD 的概念展开,RDD是可以并行操作的元素的容错集合。Spark支持通过集合来创建RDD和通过外部数据集构建RDD两种方式来创建RDD。例如,共享文件系统、HDFS、HBase或任何提供Hadoop InputFormat的数据集。 2.1 创建RDD示例:通过集合来创建RDD ...
分布式数据库TiDB的设计和架构
(SQL),能很好的解决复杂的数据运算及表间处理,多用于银行、电信等传统行业复杂业务逻辑场景中,以 Oracle 为代表。此类数据库挑战在于成本高,随着数据量增加,只能通过购买更贵更好的服务器;无法线性扩容,海量数据下处理能力大幅下降。**2008年至2013年**2008年至2013年,随着搜索/社交的发展,数据量爆发增长,传统数据库高成本,无法线性扩容问题日益突显;分布式及分布式非关系型(NoSQL)开始快速发展,如 MongoDB,HBase。但此类数...
基于国产化环境的金融级业务系统性能优化实践|社区征文
和服务创新提供强有力的支撑。系统总体架构设计如下所示:- 底层芯片采用国内主流ARM路线的CPU;- 操作系统采用国产Kylin操作系统;- 数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。...
我的大数据学习总结 |社区征文
学习数据流技术Kafka和分布式协调服务Zookeeper。深入研究Yarn和求执行引擎Spark。此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和操作系统原理。后面再系统学习关系数据库MySQL和数据仓库理论。学... 学习难点: SQL on RDD与SQL on Dataset/DataFrame的区别。在学习SparkSQL时,我发现它支持两种SQL查询方式:使用SQL对RDD进行查询,以及使用SQL对Dataset/DataFrame进行查询。区分两个概念变得很重要。为了理解区别...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
存储-HDFS & NoSQL 团队共同合作研发的新一代面向复杂业务的实时服务分析系统(HSAP: Hybrid Serving and Analytical Processing),希望能在应对大数据复杂分析场景的同时,也能满足业务对于实时数据在线服务的需求。... 结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。...
配置数据源
HBase 数据源 配置 HDFS 数据源 配置 Hive 数据源 配置 Kafka 数据源 配置 Kudu 数据源 配置 LarkSheet 数据源 配置 LAS 数据源 配置 MaxCompute 数据源 配置 Mongo 数据源 配置 MySQL 数据源 配置 OceanBase 数据源 配置 Oracle 数据源 配置 OSS 数据源 配置 PostgreSQL 数据源 配置 Redis 数据源 配置 REST_API(HTTP形式)数据源 配置 RocketMQ 数据源 配置 SAP Hana 数据源 配置 SQLServer 数据源 配置 StarRocks 数据源 配置...
20000字详解大厂实时数仓建设 | 社区征文
顺风车实时数仓和对应的离线数仓有很多类似的地方。例如分层结构;比如 ODS 层,明细层,汇总层,乃至应用层,他们命名的模式可能都是一样的。但仔细比较不难发现,两者有很多区别:1. **与离线数仓相比,实时数仓的层次... 渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要...
支持的数据源
SQLServer ✅ ✅ ✅ ✅ 关系型数据库 PostgreSQL ✅ ✅ ✅ ✅ 关系型数据库 VeDB ✅ ✅ ✅ ✅ 关系型数据库 GaussDB ✅ ✅ ✔️ 关系型数据库 GBase8s ✅ ✅ 关系型数据库 GreenPlum ✅ 关系型数据库 OceanBase ✅ ✅ 大数据存储 LAS ✅ ✅ ✅ 大数据存储 HBase ✅ ✅ ✅ 大数据存储 HDFS ✅ ✅ 大数据存储 Hive(on HDFS) ✅ ✅ ✅ 大数...
创建实例
和中划线(-)。 长度需要在 1~128 个字符内。 实例类型 当前仅支持标准版,无需选择。 数据库版本 当前仅支持HBase 2.0,无需选择。 可用区 每个地域都有多个相互隔离的区域,称为可用区。不同可用区间没有实质区别。 实例规格 Master 节点,需要选择如下配置:节点规格:选择 Master 节点的资源规格。更多关于 Master 节点规格的信息,请参见实例规格。 节点数量:Master 节点的数量。固定为 2,支持高可用,无需选择。 Region Server 节...
