storm写hbase优化
 社区干货
社区干货
基于国产化环境的金融级业务系统性能优化实践|社区征文
并创新地开发出HBase分布式事务处理等新技术,从而推出了Trafodion,并将全部代码开源,贡献给社区。应客户的要求,为了能够让业务系统在国产化环境下性能达到最优,对系统从硬件到软件做了全方位的性能优化,包括BIOS... 读写密集型业务尽可能IO分流。l **网络层面**:提升网络IO速率、尽量减少不必要的网络数据传输。l **应用层面**:提升线程并发数,充分利用CPU的多核特点,降低热点资源竞争、减少或避免锁、微服务化、分布式架构...
大数据学习架构实践|社区征文
HBase列式存储在HDFS基础上,采用了列式存储的HBase数据库,解决了数据稀疏性的问题。并且由于HBase中数据结构的优化,使得快速实时查询在HBase上成为可能。# **4、大数据技术生态**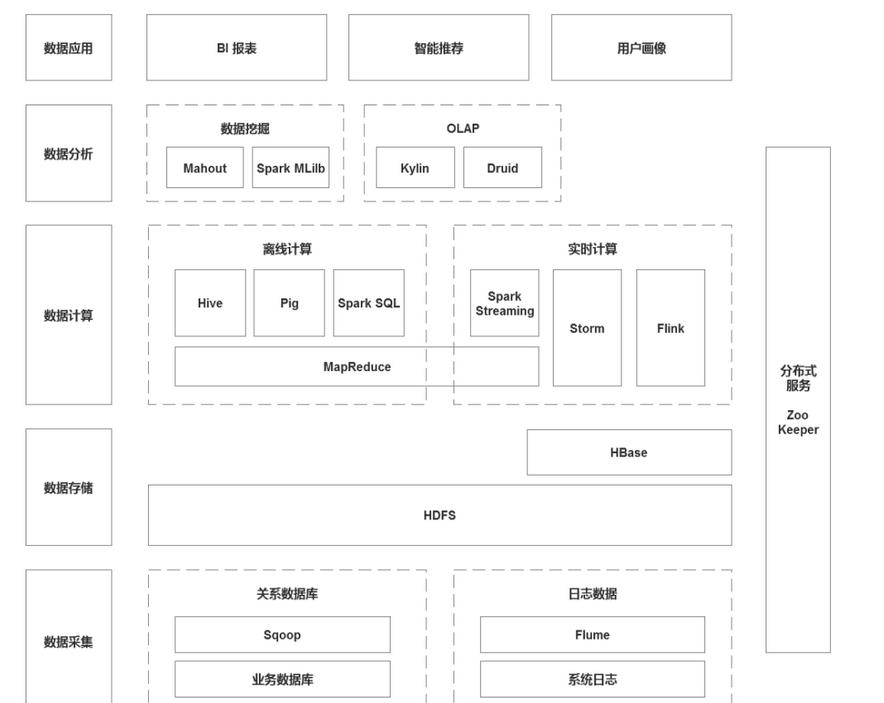## **4.1 数据采集**1)Sqoop:Sqoop是关系型数据库和HDFS之间的一个桥梁,写的时候除了HDFS,还可以写Hive,甚至可...
20000字详解大厂实时数仓建设 | 社区征文
分别是:Storm、SparkStreaming、Flink,计算框架越来越成熟。一方面,实时任务的开发已经能通过编写 SQL 的方式来完成,在技术层面能很好地继承离线数仓的架构设计思想;另一方面,在线数据开发平台所提供的功能对实时任... 渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 锁优化,启动加速等问题,将原 Name Node 的服务能力进一步提高。容纳更多的元数据信息。为了解决这个问题,我们也实现了字节跳动特色的 DanceNN 组件,兼容了原有 Java 版本 NameNode 的全部功能基础上,大大增强了稳定...
 特惠活动
特惠活动
 storm写hbase优化-优选内容
storm写hbase优化-优选内容
 storm写hbase优化-相关内容
storm写hbase优化-相关内容
20000字详解大厂实时数仓建设 | 社区征文
分别是:Storm、SparkStreaming、Flink,计算框架越来越成熟。一方面,实时任务的开发已经能通过编写 SQL 的方式来完成,在技术层面能很好地继承离线数仓的架构设计思想;另一方面,在线数据开发平台所提供的功能对实时任... 渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 锁优化,启动加速等问题,将原 Name Node 的服务能力进一步提高。容纳更多的元数据信息。为了解决这个问题,我们也实现了字节跳动特色的 DanceNN 组件,兼容了原有 Java 版本 NameNode 的全部功能基础上,大大增强了稳定...
EMR-3.6.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... HBase集群类型、Flink集群类型、自定义集群类型适配Kerberos,该特性属于白名单功能。 更改、增强和解决的问题【组件】Tez版本升级由0.10.1升级到0.10.2 【组件】Spark组件开箱参数优化,以及内核优化提高SQL执行性...
返回结构
本文介绍表格数据库 HBase 版的 API 返回结构信息。 说明 HTTP 状态码为 200,表示接口请求成功。 所有非 200 的 HTTP 状态码,表示接口请求失败。具体的失败信息,以 JSON 的形式返回。 返回结果示例请求调用成功返回结果json { "ResponseMetadata": { "RequestId": "202204151506390101940591001265****", "Action": "DescribeRegions", "Version": "2018-01-01", "Service": "hbase", "Region": "cn-beijing" }, "Result":...
EMR-3.6.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... 并提供开箱参数优化。参考Proton发行版本。 【组件】Flink组件中支持自定义参数功能。 【组件】Kafka组件中支持自定义参数功能。 【组件】Trino组件中修复access-control.properties文件内容。 【组件】修复扩...
搞流式计算,大厂也没有什么神话
计算引擎用的还是 ApacheStorm——诞生于 2011 年的、Twitter 开发的第一代流处理系统,只支持一些 low level 的 API。“所有的 Storm 任务都是在开发机上用脚本提交,运维平台处于非常原始的状态。如果 Storm ... 对方写的代码我们也都能看懂,优化起来很方便。”除此之外,字节在 Flink 稳定性方面做了大量的工作,比如支持黑名单机制,单点故障恢复,Gang 调度,推测执行等功能。由于业务对数据的准确性要求更高了,团队支持作...
一文读懂火山引擎云数据库产品及选型
宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以 Neo4j 为代表)**。虽然这些类型都属于 NoSQL 数据库范畴,但是不同类型的 NoSQL 数据库所适用的场景各有不同,需要根据业务特征选择合适的 NoSQL 数据库。其中 KV 型 NoSQL 数据库适用于需要超高性能,读远多于写,并且可以容忍数据部分丢失的场景,例如作为关系型数据库的外部缓存,用于提升系统整体的读性能,减轻关系型数据...
EMR-3.9.0发布说明
环境信息版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 系统环境应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 ... 优化读吞吐,优化Meta RPC执行效率; 组件版本下面列出了 EMR 和此版本一起安装的组件。 组件 版本 描述 zookeeper_server 3.7.0 用于维护配置信息、命名、提供分布式同步的集中式服务。 zookeeper_client 3.7.0 Zo...
EMR-3.6.2 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... 其深度优化的 TOS 访问能力和 JobCommitter 功能,可极大地提升作业的执行效率。 Kyuubi 1.7.1 是一个分布式和多租户网关,用于在数据仓库和湖仓上提供无服务器 SQL。
