hive与hbase区别
 社区干货
社区干货
Hive SQL 底层执行过程 | 社区征文
HiveHive是什么?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、... 在reduce阶段保存LastKey区分不同的key。MapReduce的过程如下: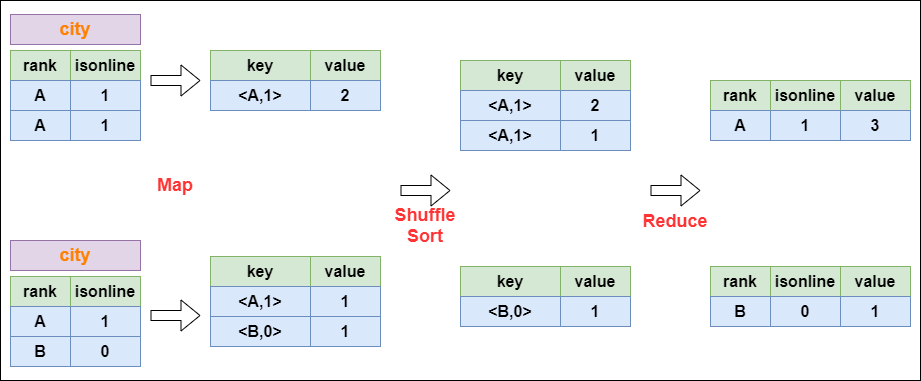#### 3. Distinct的实现原理以下面这个SQL为例,讲解 dist...
9年演进史:字节跳动 10EB 级大数据存储实战
Hive,HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 HDFS 架构。## **架构介绍** 字节跳动 HDFS 架构 ### **接入层**接入层是字节版 HDFS 区别于社区版本最大的一层,社区版本中并无这一层定义。在字节跳动的落地实践中,由于集群的节点过于庞大,我们需要非...
干货 | 看 SparkSQL 如何支撑企业级数仓
> 企业级数仓架构设计与选型的时候需要从开发的便利性、生态、解耦程度、性能、 安全这几个纬度思考。本文作者:惊帆 来自于数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规... MapReduce 和 HBase,形成了早期 Hadoop 的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似 SQL 语法的分析入口,同时在编程态的支撑也不够友好,只有 Map 和 Reduce ...
我的大数据学习总结 |社区征文
然后着重学习Hadoop核心技术如HDFS和MapReduce;接触数据库Hive后,学习数据流技术Kafka和分布式协调服务Zookeeper。深入研究Yarn和求执行引擎Spark。此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和... 学习难点: SQL on RDD与SQL on Dataset/DataFrame的区别。在学习SparkSQL时,我发现它支持两种SQL查询方式:使用SQL对RDD进行查询,以及使用SQL对Dataset/DataFrame进行查询。区分两个概念变得很重要。为了理解区别...
 特惠活动
特惠活动
 hive与hbase区别-优选内容
hive与hbase区别-优选内容
 hive与hbase区别-相关内容
hive与hbase区别-相关内容
服务概述
查看服务概述信息在集群详情页,点击 服务列表 查看已开通的服务,并选择需要查看概述信息的服务,单击 服务名称 进入服务详情。 在 服务概述 页面会展示该服务的运行情况的概述信息,概述信息分为文字指标信息和图表指标信息两种。(服务概述功能现支持以下服务:HDFS、Hive、YARN、HBase、Kafka、Presto、Trino、Ranger) 文字指标显示服务组件此刻的状态。 图表指标显示服务组件在过去一段时间内的状态,点击可切换查看信息的时间段...
我的大数据学习总结 |社区征文
然后着重学习Hadoop核心技术如HDFS和MapReduce;接触数据库Hive后,学习数据流技术Kafka和分布式协调服务Zookeeper。深入研究Yarn和求执行引擎Spark。此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和... 学习难点: SQL on RDD与SQL on Dataset/DataFrame的区别。在学习SparkSQL时,我发现它支持两种SQL查询方式:使用SQL对RDD进行查询,以及使用SQL对Dataset/DataFrame进行查询。区分两个概念变得很重要。为了理解区别...
Flink on K8s 企业生产化实践|社区征文
# 背景为了解决公司模型&特征迭代的系统性问题,提升算法开发与迭代效率,部门立项了特征平台项目。特征平台旨在解决数据存储分散、口径重复、提取复杂、链路过长等问题,在大数据与算法间架起科学桥梁,提供强有力的样本及特征数据支撑。平台从 Hive 、Hbase 、关系型数据库等大数据 ODS ( Operational Data store ) 层进行快速的数据 ETL ,将数据抽取到特征平台进行管理,并统一了数据出口,供数据科学家、数据工程师、机器学习工程...
功能发布记录(2023年)
本文为您介绍 2023 年大数据研发治理套件 DataLeap 产品功能和对应的文档动态。 2023/12/21序号 功能 功能描述 使用文档 1 数据集成 ByteHouse CDW 离线写入时,支持写入动态分区; HBase 数据源支持火山引擎 ... 修改项目配置信息 独享资源组管理 3 数据质量 数据质量双数据源校验支持 Hive 数据源,用于验证任意两种数据源之间的数据是否一致。 配置双数据源校验规则 2023/11/27序号 功能 功能描述 使用文档 1 数据...
EMR-2.2.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7 - Te...
权限管理
Hive ✅ Spark ✅ Presto Trino 实时计算 Kafka Kafka ✅ 交互式分析 Presto HDFS Hive Presto ✅ Trino HDFS Hive Trino ✅ NoSQL 数据库 HBase HDFS HBase ✅ 2 使用限制为保证权限管理模块功能的正常使... 此时区分不同集群类型,EMR 会为相应服务默认启用 Ranger 鉴权,具体 Ranger 鉴权默认启用情况可以参考上面的表格。 创建集群时不勾选安装 Ranger 服务 如果您仅仅是希望快速体验 EMR 产品,可以选择在创建集群时不...
EMR-2.4.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 HDFS 2.10.2 2.10.2 YARN 2.10.2 2.10.2 MapReduce2 2.10.2 2.10.2 Hive 2.3.9 - Spark 2.4.8 - Tez 0.10.1 - Knox 1.5.0 1.5.0 Openldap 2.5.13 2.5.13 Zookeeper 3.7.0 3.7.0 Ossa 1.0.0 - HBase 1.6.0 1.6.0 Flink 1.16.1 - Presto 0.280 - Trino 412 - DolphinSchedule...
EMR-2.1.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7 - Te...
EMR-2.1.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7 - Te...
