学习过程中CUDA的问题
 社区干货
社区干货
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 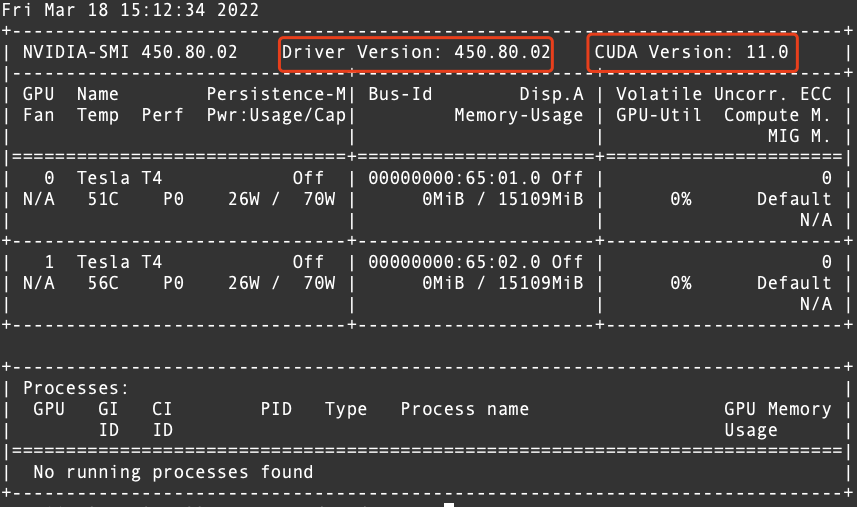 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
nvidia-cuda镜像
## 简介CUDA-X AI 是软件加速库的集合,这些库建立在 CUDA® (NVIDIA 的开创性并行编程模型)之上,提供对于深度学习、机器学习和高性能计算 (HPC) 必不可少的优化功能。下载地址:- 火山引擎访问地址:https://mirrors.ivolces.com/nvidia_all/- 公网访问地址:https://mirrors.volces.com/nvidia_all/## 相关链接官方主页:[https://www.nvidia.cn/technologies/cuda-x/](https://www.nvidia.cn/technologies/cuda-x/?spm=a...
GPU推理服务性能优化之路
# 一、背景随着CV算法在业务场景中使用越来越多,给我们带来了新的挑战,需要提升Python推理服务的性能以降低生产环境成本。为此我们深入去研究Python GPU推理服务的工作原理,推理模型优化的方法。最终通过两项关键... 典型的CUDA代码执行流程:a.将数据从Host端copy到Device端。b.在Device上执行kernel。c.将结果从Device段copy到Host端。以上流程也是模型在GPU推理的过程。在执行的过程中还需要绑定CUDA Stream,以流的形式...
我的AI学习之路----拥抱Tensorflow 拥抱未来|社区征文
跟随着课程的学习,我更加对TensorFlow感兴趣啦!按照该课程所述,我自学了初级代数知识,如变量与系数、线性方程组和函数曲线,使我自己更好的理解基本的机器学习模型。此外,因为我自己之前已经完成了Python的学习,基础的函数定义、列表/字典、循环和条件表达式等都早已熟记于心,自己可以更快速的学习TensorFlow。除了前面所述的两个基本要求外,在学习的过程中,我们需要准备一些基础知识,当然等真正遇到再去查资料也完全没问题。其...
 特惠活动
特惠活动
 学习过程中CUDA的问题-优选内容
学习过程中CUDA的问题-优选内容
 学习过程中CUDA的问题-相关内容
学习过程中CUDA的问题-相关内容
GPU推理服务性能优化之路
# 一、背景随着CV算法在业务场景中使用越来越多,给我们带来了新的挑战,需要提升Python推理服务的性能以降低生产环境成本。为此我们深入去研究Python GPU推理服务的工作原理,推理模型优化的方法。最终通过两项关键... 典型的CUDA代码执行流程:a.将数据从Host端copy到Device端。b.在Device上执行kernel。c.将结果从Device段copy到Host端。以上流程也是模型在GPU推理的过程。在执行的过程中还需要绑定CUDA Stream,以流的形式...
GPU-部署Pytorch应用
本文介绍如何在Linux实例上部署Pytorch应用。 Pytorch简介PyTorch是一个开源的Python机器学习库,用于自然语言处理等应用程序,不仅能够实现强大的GPU加速,同时还支持动态神经网络。 软件版本操作系统:本文以Ubuntu 18.04为例。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以470.57.02为例。 CUDA工具包:使GPU能够解决复杂计算问题的计算平台。本文以CUDA 11.4为例。 CUDNN库:深度神经网络库,用于实现高性能GPU加速。本文...
我的AI学习之路----拥抱Tensorflow 拥抱未来|社区征文
跟随着课程的学习,我更加对TensorFlow感兴趣啦!按照该课程所述,我自学了初级代数知识,如变量与系数、线性方程组和函数曲线,使我自己更好的理解基本的机器学习模型。此外,因为我自己之前已经完成了Python的学习,基础的函数定义、列表/字典、循环和条件表达式等都早已熟记于心,自己可以更快速的学习TensorFlow。除了前面所述的两个基本要求外,在学习的过程中,我们需要准备一些基础知识,当然等真正遇到再去查资料也完全没问题。其...
大模型:深度学习之旅与未来趋势|社区征文
如何在大量的优化策略中根据硬件资源条件自动选择最合适的优化策略组合,是值得进一步探索的问题。此外,现有的工作通常针对通用的深度神经网络设计优化策略,如何结合 Transformer 大模型的特性做针对性的优化有待进... 我们还通过BertTokenizer.from_pretrained()方法加载了预训练的tokenizer。最后,我们通过BertForTokenClassification.from_pretrained()方法加载了BERT模型。3.输入文本进行NER:```pythondef ner_inference(t...
火山引擎大规模机器学习平台架构设计与应用实践
模型训练过程中的网络通信带宽、训练资源数和时长都不尽相同。所以面对丰富的机器学习应用,我们的需求是多样的。针对这些需求,底层的计算、存储、网络等基础设施要提供强大的硬件,同时在这些硬件基础上还要提供强大的调度能力,才能为各种需求提供较好的服务,使集群利用率维持在较高水平。模型训练的第二个痛点是偏管理上的。比如在算法问题上,一个方法比另外一好,其中的原因多种多样,可能是基础架构不同,也可能是算法不同。在字...
GPU-基于Diffusers和Gradio搭建SDXL推理应用
用于调节在模型推理中的速度和质量。目前,Diffusers已经支持SDXL 1.0的base和refiner模型,可生成1024 × 1024分辨率的图片。 软件要求GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以470.57.02为例。 Pytorch:开源的Python机器学习库,实现强大的GPU加速的同时还支持动态神经网络。本文以2.0.0为例。Pytorch使用CUDA进行GPU加速时,在GPU驱动已经安装的情况下,依然不能使用,很可能是版本不匹配的问题,请严格关注虚拟环境中CUDA与Pyto...
GPU-部署Baichuan大语言模型
Pytorch使用CUDA进行GPU加速时,在CUDA、GPU驱动已经安装的情况下,依然不能使用,很可能是版本不匹配的问题,请严格关注以上软件的版本匹配情况。 使用说明下载本文所需软件需要访问国外网站,建议您增加网络代理(例如FlexGW)以提高访问速度。您也可以将所需软件下载到本地,参考本地数据上传到GPU实例中。 操作步骤步骤一:创建GPU计算型实例请参考通过向导购买实例创建一台符合以下条件的实例: 基础配置:计算规格:ecs.gni2.3xlarge...
GPU-部署ChatGLM-6B模型
针对中文问答和对话进行了优化。经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。 软件要求注意 部署ChatGLM-6B语言模型时,需保证CUDA版本 ≥ 11.4。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以535.86.10为例。 CUDA:使GPU能够解决复杂计算问题的计算平台。本文以CUDA 12.2为例。 CUDNN:深度神经网络库,用于实现高性能...
GPU-部署NGC环境
学习框架的镜像,例如Caffe、TensorFlow、Theano、Torch等。 软件版本操作系统:本文以Ubuntu 18.04为例。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以470.57.02为例。 CUDA:使GPU能够解决复杂计算问题的... 步骤一:查看驱动版本已安装成功远程连接云服务器并登录,具体操作请参考登录Linux实例小节。 执行以下命令,查看GPU驱动。nvidia-smi回显如下,表示已安装成功。 执行以下命令,查看CUDA驱动。/usr/local/cuda/bin/n...
