如何稳定机器学习模型?
 社区干货
社区干货
如何构建过拟合和防过拟合模型
机器学习提供了一种可以自动构建和修改模型的强大方法,能够从大量的输入数据中学习和优化模型,以产生更准确、更精确的预测。但是,当机器学习模型过分关注训练数据中的噪声和其他异常因素,而忽略了其他重要特征时,该模型可能会发生“过拟合”。如果模型太简单,而忽略了许多重要特征,则可能会发生“欠拟合”。因此,要构建准确的机器学习模型,用户需要有一种策略来确保模型不会过拟合或欠拟合,以确保预测的准确性。下面,我们将讨论如...
我的技术年终总结——机器学习 |社区征文
## 一、机器学习是什么?- 从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。 - 直观上理解,机器学习(Machine Learning,ML)是研究计算机模拟人类的学习活动,获取知识和技能的理论和方法,改善系统性能的学科。因为计算机系统中“经验‘通常以数据的形式存在,所以机器要利用经验,就必...
浅谈AI机器学习及实践总结 | 社区征文
这时候强化学习就上场了,它针对是智能体(可以理解成一种机器学习模型)如何基于环境而做出行动反应,以获得最大化的累积奖励。其与监督学习的差异在于监督学习是从数据中进行学习,而强化学习是从环境给他的奖惩中学习。Q-learning,SARSA,深度强化网络、蒙特卡洛学习...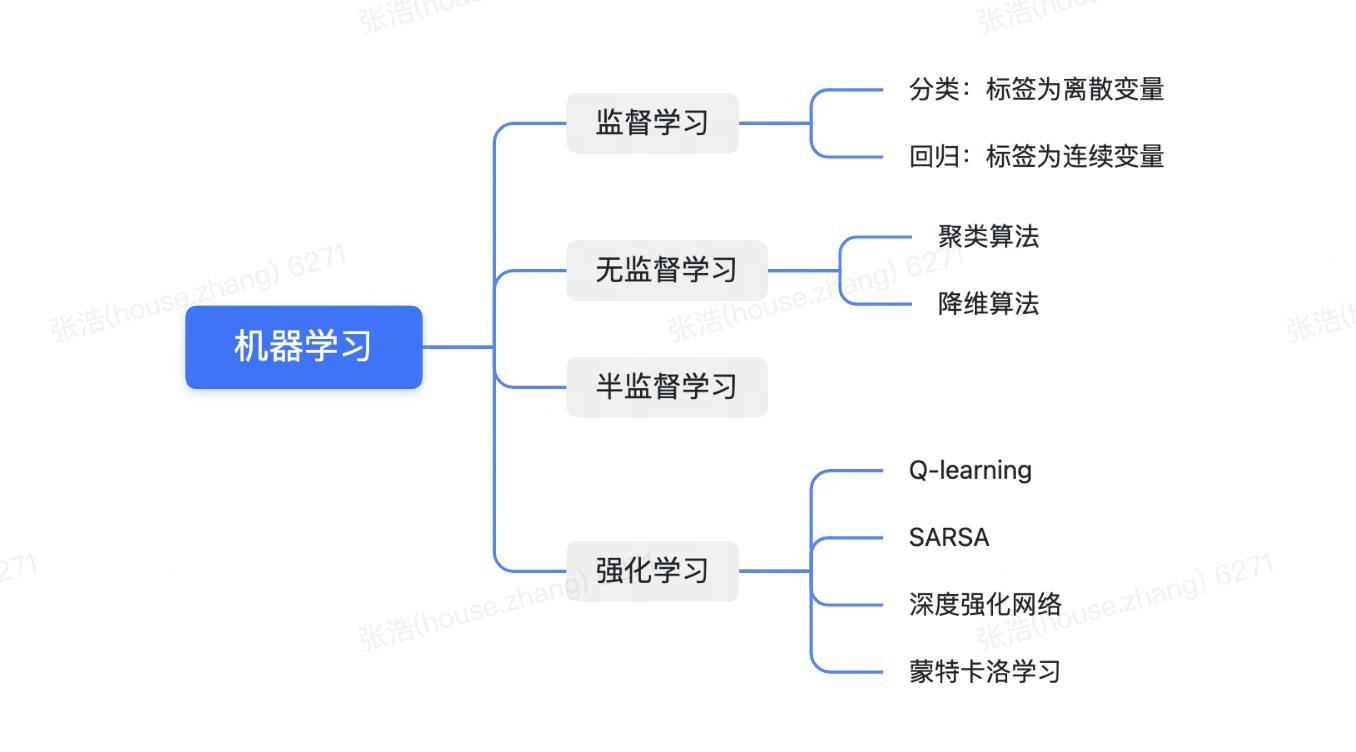## 如何理解深度学习常...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和回填特征。本文将介绍字节跳动如何通过 Iceberg 数据湖支持 EB 级机器学习样本存储,实现高性能特征读取和高效特征调研、特征工程加速模型迭代。**相关产品**:https://www.volcengine.com/product/flink # 机器学习样本存储:背景与趋势在字节跳动,机器学习模型的应用...
 特惠活动
特惠活动
 如何稳定机器学习模型?-优选内容
如何稳定机器学习模型?-优选内容
 如何稳定机器学习模型?-相关内容
如何稳定机器学习模型?-相关内容
火山引擎大规模机器学习平台架构设计与应用实践
如何先复现实验结果?团队不同的人做了不同的实验,如何对这些实验进行对比?这些都是有挑战的事情。这些管理问题其实也是机器学习模型训练过程中比较大的痛点。本文将针对这些痛点,介绍我们如何进行机器学习平台的架构设计。## 云原生机器学习平台架构设计我们主要在两方面做了投入:一是高性能计算和存储的规模化调度;二是模型分布式训练的加速。### 高性能计算和存储的规模化调度——挑战#### 计算侧在高性能计算方面...
机器学习
1. 概述 机器学习,是指可视化建模支持机器学习算子,对数据进行加工处理,以便用户基于数据进行模型训练、深度分析、预测分析等。本文将为您介绍机器学习算子的功能。 2. 功能介绍 2.1 预测将机器学习算子训练生成的... 2.6 时间序列ARIMA模型将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模 型来近似描述这个序列。这个模型一旦被识别后就可以从时间序列的过去值及现在值来预测未来值。可以帮助企业对未来进...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
=&rk3s=8031ce6d&x-expires=1714839657&x-signature=Al%2FWOIx2RqK%2F278tUeMeOkcCpBo%3D)深度学习的模型规模越来越庞大,其训练数据量级也成倍增长,这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和回填特征。本文将介绍字节跳动如何通过 Iceberg 数据湖支持 EB 级机器学习样本存储,实现高性能特征读取和高效特征...
机器学习
1.功能概述 机器学习,是指可视化建模支持机器学习算子,对数据进行加工处理,以便用户基于数据进行模型训练、深度分析、预测分析等。本文将为您介绍机器学习算子的功能。 2.算子介绍 2.1 预测将机器学习算子训练生成... 2.6 时间序列ARIMA模型 将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模 型来近似描述这个序列。这个模型一旦被识别后就可以从时间序列的过去值及现在值来预测未来值。可以帮助企业对未来进...
字节跳动杨震原:抖音如何用好机器学习
首先说说为什么要聊机器学习,什么场景、什么情况下要用机器学习系统?用机器学习会有什么样的挑战?我们是怎么解决这些挑战的? 用机器学习的前提,是问题可以定量评估 我认为机器学习很重要的一点,是把问题数字化。先数字化,然后让这个问题可以定量评估。当问题可以定量评估的时候,接下来就可以智能化,进一步用一些机器学习的方法来优化。之前有些朋友问我,说“震原,能不能帮我搞一个模型?”我问他想用这个模型干什么?他其实自己并...
字节跳动正式开源分布式训练调度框架 Primus
> 项目地址:https://github.com/bytedance/primus 随着机器学习的发展,模型及训练模型所需的数据量越来越大,也都趋向于通过分布式训练实现。而算法工程师通常需要对这些分布式框架涉及到的底层文件存储和调度... 大规模应用混部资源:由于混部资源不稳定的特点,对训练的容错和稳定有着更高的要求;1. 支持复杂调度编排语义:为了使集群资源利用率最大化,需要将合适的容器放在适当的位置上,并需要能够动态调整并发和容器大小。...
火山引擎大规模机器学习平台架构设计与应用实践
如何先复现实验结果?团队不同的人做了不同的实验,如何对这些实验进行对比?这些都是有挑战的事情。这些管理问题其实也是机器学习模型训练过程中比较大的痛点。本文将针对这些痛点,介绍我们如何进行机器学习平台的架构设计。 云原生机器学习平台架构设计 我们主要在两方面做了投入:一是高性能计算和存储的规模化调度;二是模型分布式训练的加速。 **高性能计算和存储的规模化调度——挑...
导入模型
机器学习平台支持用户从本地或者对象存储(TOS)将模型注册到【模型仓库】模块下,每个模型允许包含多个版本。 相关概念 模型管理(模型仓库) Tensor 配置 对象存储(TOS) 创建新模型 登录机器学习平台,单击左侧导航栏中的【模型仓库】进入列表页面。 单击列表页面左上方的【+ 创建模型】进入创建页面。 在创建页面填写相关参数,具体参数如下: 参数名称 参数说明 模型名称 * 填写模型的名称。 必填 。 * 支持 1~64 位可见字符,且只...
揭秘字节跳动基于 HPC 的大规模机器学习技术
点击上方👆蓝字关注我们! 随着智慧科研、自动驾驶、基因测序、量化投资等大量新兴产业的发展,现代产业对模型训练有了大量的需求,模型体积也呈现爆发式地增长。而大模型训练给底层基础设施,尤其是计算能力带来了不小的挑战。4 月 14 日,火山引擎开发者社区 **技术大讲堂第一期**将为大家揭秘字节跳动基于 HPC 的大规模机器学习技术。字节跳动经过业务实践打磨的**机器学习技术将****首次亮相*...
