图数据库建模技术
 社区干货
社区干货
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数据仓库中的数据?- 怎么组织才能使得数据的使用最为方便和便捷?- 怎么组织才能使得数据仓库具有良好的可扩展性和可维护性?> **Ralph Kimball 维度建模理论很好地回答和解决了上述问题。**维度建模理论和技术也是...
干货|数据湖技术在抖音近实时场景的实践
与传统数仓建模使用的schema on write 模式相比,数据湖采用了一种 schema on read 的模式,即不会事先对它的 schema 做过多的定义,而是在使用的时候才去决定 schema,从而支持上游更丰富、更灵活的应用。字节数据湖**Apache Hudi有下面非常重要的特性:** * Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)...
干货|底层技术揭秘!如何搭建“广告投放”场景下的A/B测试平台
将开发者信息预先保存至数据库中; **2.**将权限信息、开发者账户信息以及需要希望回调时带回的数据,统一拼装至授权链接后跳转至广告平台; **3.**用户点击授权,广告平台回调开发者账号填写的... 我们一般会使用充血模型来建模实际的对象,同时,由于业务的核心价值在于其运作模式,而不是具体的技术手段或实现方式。因此,领域层的编码是不允许依赖其他外部对象的。 **4. 基础设施层**基础设施层是在...
AI安全技术总结与展望| 社区征文
访问数据库、移动等,从而及时采取防御或者处置措施,以防泄露重要的数据。机器学习还能对不同的数据进行分类,在更细粒度上识别风险,保护数据的安全。 近来来,人工智能技术逐渐应用于各个安全产品,如SIEM、SOCK、SORA,通过分析平台日志,可构建异常检测模型、自动化编排响应。近年来,“安全大脑”一词较为火热,其目的进行对企业的安全要素进行智能编排,发现威胁管理流程、自动化建模。 人工智能在安全的应用尚处于初级阶段...
 特惠活动
特惠活动
 图数据库建模技术-优选内容
图数据库建模技术-优选内容
 图数据库建模技术-相关内容
图数据库建模技术-相关内容
字节跳动基于数据湖技术的近实时场景实践
与传统数仓建模使用的schema on write 模式相比,数据湖采用了一种 schema on read 的模式,即不会事先对它的 schema 做过多的定义,而是在使用的时候才去决定 schema,从而支持上游更丰富、更灵活的应用。## **1.2 字节数据湖**Apache Hudi有下面非常重要的特性:- Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数...
2022技术盘点之平台云原生架构演进之道|社区征文
削减技术债务,专注业务创新。下图为SmartOps架构全景: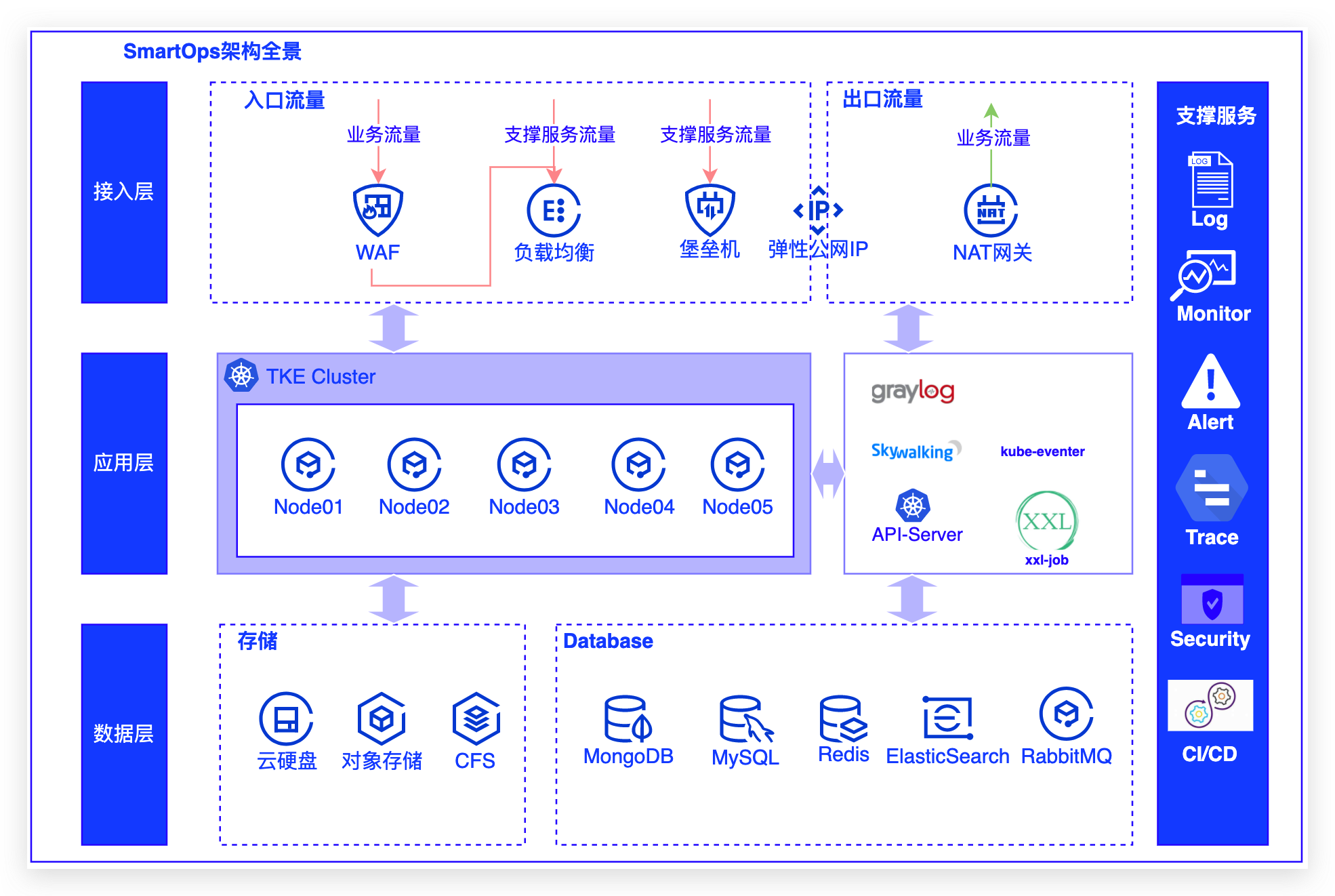- 接入层:通过WAF/SLB,配合NAT网关治理出方向流量,... 数据库有MongoDB分片集群/MySQL/Redis/ElasticSearch/RabbitMQ进行各类业务数据计算和存储## 三 流量管控...
字节跳动自研万亿级图数据库 & 图计算实践
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/5357a124a5134af89ad57441c53d42a2~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1714062040&x-signature=%2FDrcQlKkx59VcRAN4bERo7hGkx4%3D) 本文将对字节跳动自研的分布式图数据库和图计算专用引擎做深度解析和分享,展示新技术是如何解决业务问题,影响几亿互联网用户的产品体验。来源:字节跳动技术团队...
一位老IT的2023年的技术总结 |社区征文
## 笔者介绍笔者介绍,近几年的工作内容都与数据库和大数据相关,公司的市场定位 为客户提供数据智能一体化的解决方案,笔者的工作主要围绕公司的旗舰产品做一些售前、售中、售后的事情 ,主要是DBA和技术支持。工作... 一般采用关系模型建模的方式 。**大数据系统建设方案:** 该应用建设需要整合较多的数据源,将集成较多的数据集,主要与业务系统联通或者其它设备的数据汲取过来,通过清洗、整合、编排后,输出一个错落有致、规范得体...
通过客户端运维数据库
通过客户端连接数据库进行运维操作。本文以 Windows 系统的 Navicat for MySQL 客户端工具为例进行介绍。 说明 【邀测】数据库运维属于付费功能,目前处于邀测试用阶段,如需使用,请联系官方技术支持。 前提条件云堡... 如下图所示,依次配置 MySQL 连接的 SSH 信息和常规信息。 配置类 配置项 说明 SSH 使用 SSH 隧道 勾选以使用 SSH 隧道。目前通过云堡垒机连接数据库的实现,必须使用 SSH 隧道,其他方式暂不可用。 主机 SSH 隧道...
一文读懂火山引擎云数据库产品及选型
> **火山引擎存储&数据库产品解决方案团队**,由资深的存储&数据库解决方案架构师组成。团队致力于帮助企业与组织更好的使用火山引擎云存储与云数据库产品,针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软...
基于云数据库 PostgreSQL 版构建智能交互式问答系统
本文就如何利用云数据库 PostgreSQL 版和大语言模型技术(Large Language Model,简称 LLM),实现企业级智能交互式问答系统进行介绍。通过本文,您将学习了解到:交互式问答系统原理、PostgreSQL 向量化存储和检索技术,... 来演示将云数据库 PostgreSQL 版作为向量数据库的使用方法。 核心概念及原理核心概念:嵌入向量(Embedding Vectors)向量 Embedding 是在自然语言处理和机器学习中广泛使用的概念。各种文本、图片或其他信号,均可通过...
加速大模型落地:火山引擎向量数据库的实践应用
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/1d0348a36139451ea45dd112380bc245~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1710433205&x-signature=OwrV1e72eLj8BScIMyxKcns29Vg%3D)近两年随着大模型技术的快速发展,图片、视频、自然语言等多模态、非结构化数据的查找需求变大,非结构化数据的量级也远大于结构化数据,传统数据库已经无法满足如此多样化数据的处理需求。...
抖音大规模实践,火山引擎向量数据库是这样炼成的
火山引擎向量数据库技术演进之路 **存算分离的分布式架构搭建**在抖音集团内部,早期的向量化检索引擎是围绕搜索、推荐、广告业务来构建的,由于这些业务天然具有极大的数据规模,因此从一开始,就需要思考如何在向量索引中支持百亿数据的检索需求,比如图虫拥有几亿图片素材,数量规模早已超出单机内存的极限,举个例子,对于 1 亿条 128 维的 Float 向量,不考虑任何辅助结构,就需要 100000000 * 128 * 4 b...
