以并行方式高效下载大量文件的方法
 社区干货
社区干货
阿里巴巴的 Java 开发手册(黄山版)来了
当时是在阿里的公众号下载的,后来还买了实体的《Java开发手册》和《码出高效》两本书。其实这本小册子并不是什么深度的内容,但是却让我受益匪浅——你写不出复杂高深的代码,但是至少能写出规范、干净、同事看了不喊“卧槽”而是喊“卧槽牛逼”的代码。在这篇文章中我将会挑选几条手册中的编程规约做一个简单的导读。**友情提示,文末有手册下载方式哦。**>对软件来说,适当的 规范和标准绝不是消灭代码内容的创造性、优雅性...
年终学习大礼包|云原生大数据知识地图
# 大势所趋:云原生大数据随着行业的快速发展和业务的高速迭代,数据量也呈爆炸式增长,传统的大数据架构在资源利用、高效运维、可观测性等方面存在诸多不足,已经越来越无法适应当下的发展需求。具体来讲,传统大数据... 它可以按分时复用的方式来调用资源。- **资源调度层面**:在传统模式下,如果一个 Flink 集群有100台机器,那这100台机器就由它独占;云原生模式虚拟化出了资源池的概念。资源池可以承载不同类型的大数据集群,可以装...
年终学习大礼包|云原生大数据知识地图
随着行业的快速发展和业务的高速迭代,数据量也呈爆炸式增长,传统的大数据架构在资源利用、高效运维、可观测性等方面存在诸多不足,已经越来越无法适应当下的发展需求。具体来讲,传统大数据架构主要存在以下几方面的... 它可以按分时复用的方式来调用资源。* **资源调度层面**:在传统模式下,如果一个 Flink 集群有100台机器,那这100台机器就由它独占;云原生模式虚拟化出了资源池的概念。资源池可以承载不同类型的大数据集群,可以装...
记一次 ClickHouse 性能测试
数据批量写入,且数据不更新或少更新;4)无需事务,数据一致性要求低;5)灵活多变,不适合预先建模。### 环境准备在阿里云买一台 16c64g 的服务器,操作系统 centos 7.8,使用 sealos 一键安装 k8s,使用 helm 一键安装 mysql(5.7)、influxdb(1.8)、clickhouse(22.3) ,每个应用各分配 4c16g 的资源。 ```bash# 下载 sealos$ wget https://github.com/labring/sealos/releases/download/v4.0.0/sealos_4.0.0_linux_amd64.tar.gz \&...
 特惠活动
特惠活动
 以并行方式高效下载大量文件的方法-优选内容
以并行方式高效下载大量文件的方法-优选内容
 以并行方式高效下载大量文件的方法-相关内容
以并行方式高效下载大量文件的方法-相关内容
最新动态(2024年前)
用户过滤等方式,选择符合当前筛选条件的历史实验,给未来新开实验提供历史经验参考。详细可查看文档:经验库 上线「优化计划」功能 「优化计划」是日常产品的迭代从始至终的缩影,通过制定优化目标、关联AB实验和自动... 使用蒙特卡洛方法,得出每个方案/人群为最优的概率3. 可视化3.2: 支持元素尺寸相关CSS样式编辑 系统管理:全局操作历史,可从全局角度下查看所有实验和Feature的变更记录 5. 系统管理:白名单支持批量登记 删除用户时数...
干货 | 以一次Data Catalog架构升级为例,聊聊业务系统的性能优化
打开详情展示时需要等1分钟以上为此,我们进行了一系列的性能调优,结合Data Catlog产品的特点,调整了Apache Atlas以及底层Janusgraph的实现或配置,并对优化性能的方法论做了一些总结。 ***## 二、注意点### 1. 并行度- ***并行度 不等于 最大线程数(maximumPoolSize)***,下图 commonPool 有49个线程,但是 并行度为1- 默认的 ...
得物AI平台-KubeAI推理训练引擎设计和实践
所以模型推理服务也主要以Python GPU推理为主。模型推理过程一般涉及预处理、模型推理、后处理过程,单体进程的方式下CPU前/后处理过程,与GPU推理过程需要串行,或者假并行的方式进行工作,大致流程如下图所示:。在微服务、DevOps和云平台流行的当下,使用一个高效的持续集成工具也是一个非常重要的事情。虽... 下载镜像并编写Deployment文件部署到k8s集群;如图1所示: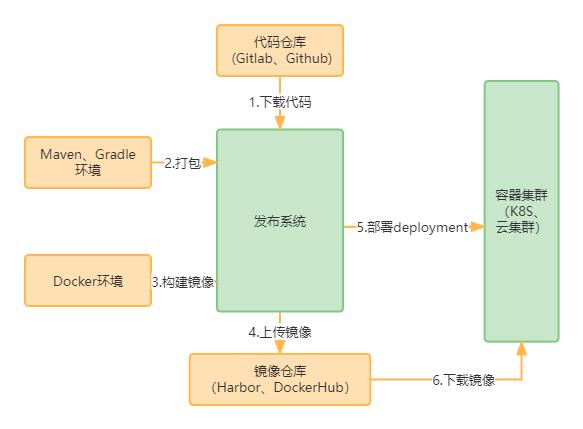图1从以上步骤...
字节开源 Monoio :基于 io-uring 的高性能 Rust Runtime
当并行下载两个文件时,在任何语言中都可以启动两个 Thread,分别下载一个文件,然后等待 thread 执行结束;但并不想为了 IO 等待启动多余的线程,如果需要等待 IO,我们希望这时线程可以去干别的,等 IO 就绪了再做就好。这种基于事件的触发机制在 cpp 里面常常会以 callback 的形式遇见。Callback 会打断我们的连续逻辑,导致代码可读性变差,另外也容易在 callback 依赖的变量的生命周期上踩坑,比如在 callback 执行前提前释放了它会...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
> 深度学习的模型规模越来越庞大,其训练数据量级也成倍增长,这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删... 每日还在以 PB 级的速度增长。这些数据被用于支持广告、搜索、推荐等模型的训练,覆盖了多个业务领域;这些数据还支持算法团队的特征调研、特征工程,并为模型的迭代和优化提供基础。目前字节跳动以及整个业界在机器学...
干货 | 基于ClickHouse的复杂查询实现与优化
若采用哈希表的方式进行去重,第二阶段需在Coordinator单机上去合并各个Worker的哈希表。这个计算量会很重且无法并行。**第二类,由于目前ClickHouse模式并不支持Shuffle,因此对于Join而言,右表必须为全量数据。*... 会将一个复杂的Query按数据交换情况切分成多个 Stage,各Stage之间则通过Exchange完成数据交换。 **Stage之间的数据交换主要有以下三种形式。*** 按照单个或者多个key进行Shuffle* 将单个或者多个节点的数据汇...
直播预告|数据湖实时化与智能化实践探索
以及怎么去解决的?2. 了解如何基于 Iceberg,节省40%以上存储成本,提升训练速度?3. 了解字节在 Iceberg 上后续的迭代演进路线是怎样的? ![]() ### **快手基于流批一体打造高效数据湖****讲师:钟靓-快手大... 依托其强大的并行处理能力和高性能算子,可以在海量数据集上提供亚秒级的交互式查询体验。而近年来,随着数据湖技术飞速发展,越来越多的企业开始依托数据湖技术构建其基础数据的存储架构,并利用数据湖提供的批流一体...
