配置Apache虚拟主机同时支持80和443端口,结果显示目录的索引。
 社区干货
社区干货
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
此版本尚且没有得到相关的修正且官方不支持修复,只能使用新版本了!2. **【安全问题,以及workaround的问题较多】** 其实新版本与旧版本区别主要在于应用了社区中经过cherrypick挑选出来的PR以及修复了安全性漏洞、... 2022年技术团队针对于Kubernetes的配置优化调整主要做了4个方面的问题的调整和优化工作路线,当然这只是面向于研发层面的哈。- 探针经常会无缘无故Killed我们的服务- Kubernetes的对应Kill容器Pod的编码分析- K...
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
**附注:** 从上述可知,当前云主机的发行版本为CentOS,当然,若是对于系统访问并发高,业务数据量非常之大的话,除了系统前后台代码本身质量优化之外,服务器配置(物理机or虚拟机or云主机)还可选择更高配些! Ok,n... 提供了一个分布式多用户能力的全文搜索引擎,基于RESTful Web接口,基于Java语言开发,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎,能够达到实时搜索,稳定,可靠,快速,安装使用方便。****```...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
(https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/0e5b1a80e87a4b5dae34522dde5e7866~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1715098844&x-signature=YVeB8%2Bs6xT59T5OuaVCenn... 文件分布和 Hudi 一致,通过列存的 base 文件与行存的 log 文件进行数据存储,基于时间戳维护数据版本。通过 filegroup 的方式对文件进行分组,相同逐渐的数据存储在同一个文件组内。后期结合数据构建索引能力,能够比...
干货|数据湖储存如何基于 Apache Hudi落地企业基建
**Apache** **Hudi 仅支持单表的元数据管理,缺乏统一的全局视图,会存在数据孤岛。**Hudi 选择通过同步分区或者表信息到 Hive Metastore Server 的方式提供全局的元数据访问,但是两个系统之间的同步无法保证原子... 如果用户需要修改策略的话需要通过 DDL 修改表的相关配置。之所以这么做,而不是通过写入侧去提交策略信息,是因为考虑到并发场景。如果通过写入侧指定策略会出现两个写入端提交的策略不对齐的问题,比方说一个 Compa...
 特惠活动
特惠活动
 配置Apache虚拟主机同时支持80和443端口,结果显示目录的索引。-优选内容
配置Apache虚拟主机同时支持80和443端口,结果显示目录的索引。-优选内容
 配置Apache虚拟主机同时支持80和443端口,结果显示目录的索引。-相关内容
配置Apache虚拟主机同时支持80和443端口,结果显示目录的索引。-相关内容
Apache Iceberg 中引入索引提升查询性能
Apache Iceberg 是一种开源数据 Lakehouse 表格式,提供强大的功能和开放的生态系统,如:Time travel,ACID 事务,partition evolution,schema evolution 等功能。本文将讨论火山引擎EMR团队针对 Iceberg 组件的优化思路,通过引入索引来提高查询性能。## 1. 采用 Iceberg 构建数据湖仓火山引擎 E-MapReduce(简称 EMR)是火山引擎数智平台(VeDI)旗下的云原生开源大数据平台产品, 提供了企业级的 Hadoop、Spark、Flink、Hive、Pre...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
**●** **容错性**:批处理 T+1 全量计算的结果会覆盖流处理的结果,意味着流处理假如有异常、可以被批处理计算时修复; **●** **支持复杂性隔离**:批处理的是离线就绪数据,可以很好的掌控。流处理采用增量方式处理... 文件分布和 Hudi 一致,通过列存的 base 文件与行存的 log 文件进行数据存储,基于时间戳维护数据版本。通过 filegroup 的方式对文件进行分组,相同逐渐的数据存储在同一个文件组内。后期结合数据构建索引能力,能够比...
干货 I 字节跳动基于 Apache Hudi 的数据湖实战解析
Apache HUDI 作为数据湖框架的一种开源实现,提供了事务、高效的更新和删除、高级索引、 流式集成、小文件合并、log文件合并优化和并发支持等多种能力,支持实时消费增量数据、离线批量更新数据,并且可通过 Spark、F... 会根据配置来判断一下是否需要进行 Table Service,比如之前提到的 Compaction 和 Clean,会依次把这些需要执行的 Table Service 都执行一遍,之后继续下一次的写入过程。这种方式结构是最简单的,但也会带来一些问题,...
干货 I 字节跳动基于 Apache Hudi 的数据湖实战解析
Apache HUDI 作为数据湖框架的一种开源实现,提供了事务、高效的更新和删除、高级索引、 流式集成、小文件合并、log文件合并优化和并发支持等多种能力,支持实时消费增量数据、离线批量更新数据,并且可通过 Spark、F... 会根据配置来判断一下是否需要进行 Table Service,比如之前提到的 Compaction 和 Clean,会依次把这些需要执行的 Table Service 都执行一遍,之后继续下一次的写入过程。这种方式结构是最简单的,但也会带来一些问题,...
Kafka 消息传递详细研究及代码实现|社区征文
(https://kafka.apache.org/documentation/#producerconfigs)* 里有相关配置说明:[**compression.type**](url)生产者生成的数据的压缩类型。通过使用压缩,可以节省网络带宽和Kafka存储成本。type: string... // 建立与 Kafka 群集的初始连接的主机/端口对的列表 多个以逗号隔开properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka1:9092, kafka2:9092, kafka3:9092");// 消息不成功重试次数properties...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
负责对计算资源进行统一的管理和调度,能够收集各个计算组的性能数据,为查询、写入和后台任务动态分配资源。同时支持计算资源隔离和共享,资源池化和弹性扩缩等功能。资源管理器是提高集群整体利用率的核心组件。-... 数据的索引等信息。元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对于访问频度高的元数据会进行缓存。元数据服务自身只负责处理对元数据的请求,自身是无状态的,可以水平扩展。- ...
【拥有新时代的通信协议,引领云原生迈向更高的舞台】解密Dubbo3从微服务升华到云原生 | 社区征文
[](https://oscimg.oschina.net/oscnet/up-8151f8c47ea4a89415bf703cef3eb80a052.png)#### “鼠”年给云原生建立好的开端摘自官网资料中的Dubbo3的虎年的发展计划: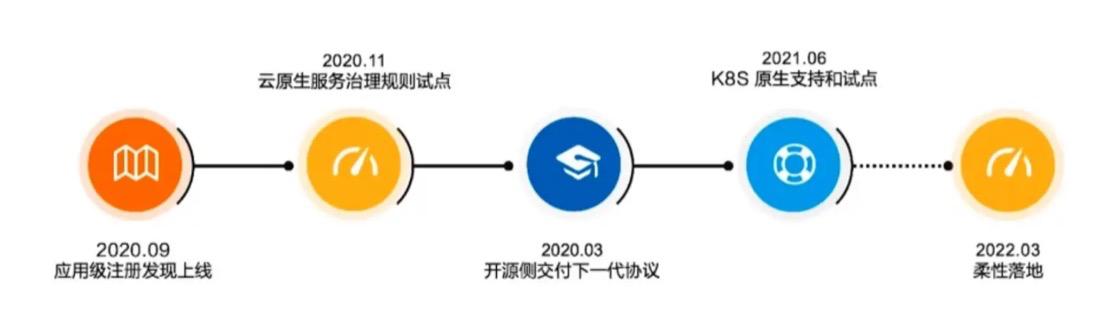#### “牛”年完美收官和中肯评价> **Dubbo3是Apache顶级项目Dubbo的一个非常具有里程碑性质的版本,它是让Dubbo服务体系全面...
安装证书到Apache服务器
支持HTTPS连接。本教程将指导您安装SSL证书到Apache服务器。 前提条件您已经通过证书中心提交了SSL证书请求,并且SSL证书已经签发。如果您还没有提交SSL证书请求,请参见快速入门。 您的服务器的443端口是开放的。HT... 环境说明本教程以以下环境为例介绍相关的操作步骤: 服务器:操作系统:Ubuntu 22.04 64位 Web服务程序:Apache/2.4.41 版本 Web服务器程序的安装目录:/etc/apache2 说明 服务器环境不同,可能导致实际配置与本文描述...
一文读懂火山引擎云数据库产品及选型
同时,根据卡内基梅隆大学维护的全球数据库信息库(dbdb.io)显示,数据库系统种类已经多达 870 种,可谓是欣欣向荣,让人眼花缭乱。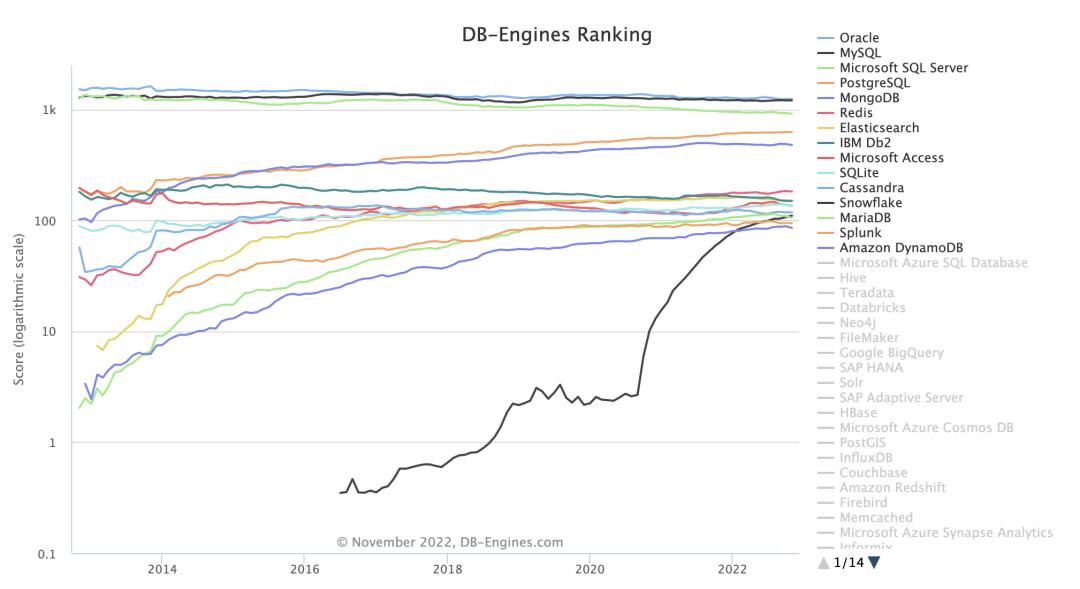纵观整个数据库发展史,关系型数据库系统是历史最悠久并且使用最广泛的一类数据库系统,其理论基础是基于 IBM 研究员 E.F.Codd 博士在 1970 年提出的“关系模型(Relatio...
