以虚拟变量为因变量的线性回归
 社区干货
社区干货
浅谈AI机器学习及实践总结 | 社区征文
因变量叫做标签(label),可定义为Y,而一批特征和标签的集合,就是机器学习的数据集。机器学习的学习过程就是在已知的数据集的基础上,通过反复的计算,选择最准确的函数去描述数据集中自变量X1,X2....Xn 和因变量Y之... 分类算法:逻辑回归、决策树分类、SVM分类、贝叶斯分类、随机森林、XGBoost、KNN...回归算法:线性回归、 决策树回归、SVN回归、贝叶斯回归...- 无监督学习:训练数据集没有标签,多应用在聚类、降维等有限的场景...
我的AI学习之路----拥抱Tensorflow 拥抱未来|社区征文
在编程实现过程中还具备以下的两大特点:### 2.1 将图的定义和图的运行完全分开使用Tensorflow进行编程与使用Python进行编程有明显的区别。在进行Python进行编程时,只要定义了相关变量以及运算,在程序运行时就会直... 直接在应用里搜**Anaconda prompt**就可以啦,打开之后就会发现这个界面:然后第二步我们进行**创建tensorflow虚拟环境**这个地方需要点**yes**的地方,就一直输入y就可以啦大数据驱动的具有综合复杂性的工业过程智能控制; 4)复杂工业过程的分析与优化控制; 5)重大耗能设备智能优化控制系统。4. **难测工艺参数与生产指标的软测量与检测技术及装置** ... 通过网络将**虚拟化的资源**作为服务提供,通常包含**基础设施即服务**(Infrastructure as a Service, IaaS)、**平台即服务**(Platform as a Service, PaaS)、**软件及服务**(Software as a Service, SaaS)。>> (...
我的技术年终总结——机器学习 |社区征文
古文献的数字化浪潮给自动文学修复提供了机会 以色列特拉维夫大学的学者将机器学习用于自动的书页拼接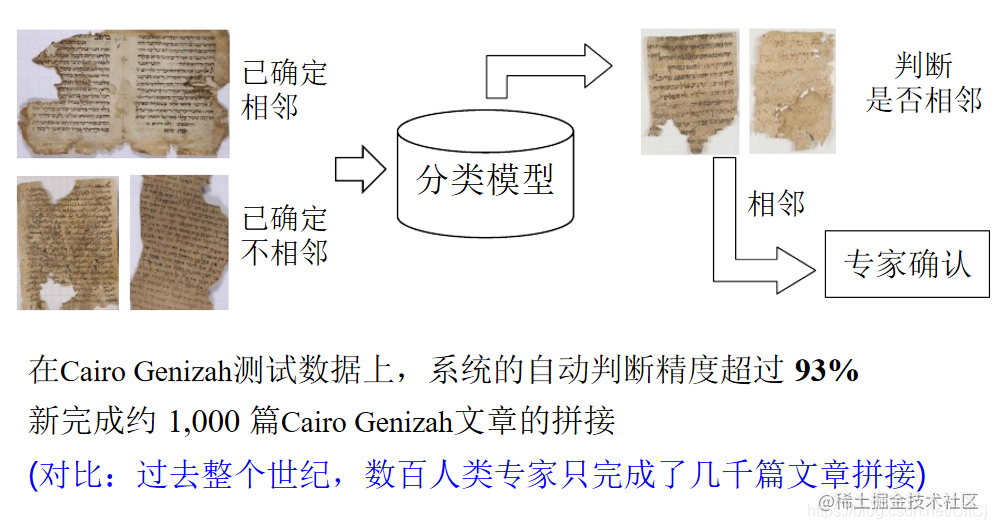回归、分类、聚类是机器学习最常见的三大任务。回归是一种数学模型,利用数据统计原理,对大量统计数据进行数学处理,确定因变量与某些自变量的相关关系,建立一个相关性较好的回归方程(...
 特惠活动
特惠活动
 以虚拟变量为因变量的线性回归-优选内容
以虚拟变量为因变量的线性回归-优选内容
 以虚拟变量为因变量的线性回归-相关内容
以虚拟变量为因变量的线性回归-相关内容
机器学习
2.3 分类支持以下模型,详情参见功能页面。 模型名称 模型简介 逻辑回归 逻辑回归是经典的统计学习分类模型,是在线性回归的映射中加一层非线性函数映射,先把该样本的特征线性求和,然后使用逻辑斯蒂函数将值映射到... 支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,CatBoost是由catgorical和boost组成,另外是处理梯度偏差(Gradient bias)以及预测偏移(Prediction shift)的问题,提高算法的准确性和...
机器学习
2.3 分类支持以下模型,详情参见功能页面。 模型名称 模型简介 逻辑回归 逻辑回归是经典的统计学习分类模型,是在线性回归的映射中加一层非线性函数映射,先把该样本的特征线性求和,然后使用逻辑斯蒂函数将值映射到 ... 支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,CatBoost是由catgorical和boost组成,另外是处理梯度偏差(Gradient bias)以及预测偏移(Prediction shift)的问题,提高算法的准确性和...
最佳实践
为了保持 Airflow 环境的整洁,一些重复性的参数,比如说连接信息应该专门配置到 Airflow Connections 中,而非在每一个 DAG 中单独定义。而在每一个 DAG 中,专门定义一个default_args来管理变量也是一种很好的实践... 它会从数据库中读取对应变量值),进行 http 请求等等。这些代码与 DAG 结构无关,却在 Scheduler 解析并更新 DAG 结构的时候显著提高了处理时间。下面是两个来自官方的例子说明: 2.3.1 反例 python from datetime im...
如何使用 Cluster Autoscaler 将批处理作业的节点扩容到 2000 个|KubeCon China
也是线性增长的。虽然 Pending Pod 的数量规模达到了,但实际 CA 僵死的时间是远比我们测出来的 400s 多,所以我们继续接近客户的使用方式,将 Pod 的调度逻辑做了修改,从之前的默认调度约束,改为了使用节点 **亲和性... 除此以外,我们继续控制变量,调整 Pod 的 request,将之前的单个节点上只跑 1 个 Pod,改为单个节点上能跑 8 个 Pod,这样修改后,预期添加到集群中的节点数量是之前的 1/8,同时整个计算耗时,相比之前的曲线,也是接近水...
AI 和机器学习:探索智能科技的未来 | 社区征文
可以使用基于机器学习的算法来改进产品设计,减少材料浪费,并提高产品性能:```# 一个简单的基于机器学习的设计优化示例from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegression# 加载和准备设计数据# ...# 划分数据集为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 使用线性回归模型进行设计优化m...
初探金融风控中的信用评分卡搭建全流程 | 社区征文
则可以完全以指标上限为目标而不必考虑模型复杂程度的限制。1. 模型的交付形式:模型的上线形式决定了模型的最终交付形式和外部接口。## 模型开发阶段模型开发阶段是整个评分卡模型开发的核心部分,包括数据收... 生产中常用随机森林进行变量重要性排序,选取累计贡献率达到阈值的变量作为最终的输入变量以进行模型训练。### 模型的训练与优化机器学习中有很多模型,从简单的线性回归到复杂的深度神经网络。在训练模型之前需...
什么是云原生及 Go 语言在原生时代的优势|社区征文
然后就有了**硬件虚拟化。****虚拟化**虚拟化是软件中模拟物理服务器硬件吗,虚拟服务器可以根据需要创建,完全可以在软件中进行编程,只要能够模拟硬件,就永远不会过时。使用虚拟化能够增加程序的可移植性。虚... 服务网格越来越难以理解和管理。**不可变的基础架构**里的“不可变”非常类似于程序设计中的“不可变”概念。程序设计中,不可变变量(Immutable Variable)就是在完成赋值后就不能发生更改,只能创建新的来整体替换...
计算机视觉算法探究:OpenCV CLAHE 算法详解| 社区征文
以上代码就是 OpenCV 自适应直方图均衡 CLAHE 对应源代码中关于 clipLimit 赋值处理的相关代码,可以看到,类设置方法中对 clipLimit 设置后,其值会保存在类私有变量 clipLimit_ 中,最终进行 apply 自适应直方图均衡... 则将该分组中超过 clipLimit_的像素数累加到 clipped 局部变量中,然后将该直方图分组像素数强制设置为 clipLimit_。上述过程对当前块的所有分组都处理完成后,将超出后累加的 clipped 变量值按分组数平均分配到各...
如何使用 Cluster Autoscaler 将批处理作业的节点扩容到 2000 个
也是线性增长的。虽然 Pending Pod 的数量规模达到了,但实际 CA 僵死的时间是远比我们测出来的 400s 多,所以我们继续接近客户的使用方式,将 Pod 的调度逻辑做了修改,从之前的默认调度约束,改为了使用节点 **亲和性... 除此以外,我们继续控制变量,调整 Pod 的 request,将之前的单个节点上只跑 1 个 Pod,改为单个节点上能跑 8 个 Pod,这样修改后,预期添加到集群中的节点数量是之前的 1/8,同时整个计算耗时,相比之前的曲线,也是接近水...
